1 引言
据文化和旅游部统计数据[1 ] 显示,2018年中国旅游人数达55.39亿人次,全年实现旅游总收入5.97万亿元,全年全国旅游业对GDP的综合贡献为9.94万亿元,占GDP总量的11.04%。旅游市场的高速增长说明人们对旅游的需求越来越大,而不同的旅游者往往有着不同的旅游目的,或是放松身心,或是探索知识。大多数旅游者在出行前都会查询相关旅游信息,但随着网络信息的爆炸式增长,很难从网站提供的众多产品和服务中选取适合自己的产品。国内具有代表性的旅游景点推荐网站如携程、马蜂窝等,也仅仅提供了大众化的旅游信息,如“当季推荐”、“主题精选”等。如何满足不同爱好、不同目的的旅游者不同的旅游需求,让旅游者能更加高效地做出旅游决策,是一个值得研究的问题。
近年来,推荐系统被认为是解决信息超载问题的有效方法,已经被广泛应用于图书、电影、音乐和网页的个性化推荐上。推荐系统在旅游领域的具体应用,既包括对景点、酒店、餐馆、航班等的推荐,也包括对旅游目的地、旅游计划、旅游包等涵盖多项产品、活动与服务等组合内容的推荐[2 ] 。用户根据自己出游的目的和计划,也会对推荐系统有着不同的需求。短期出游的用户通常希望能获得旅游景点和旅游线路的推荐,而出游时间较长的用户则希望推荐系统能结合自己的时间、位置、旅游目的地的天气和消费水平等信息提供多元化的推荐[3 ] 。
目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] 。其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] 。但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点。
Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率。
通过对现有研究分析可知,与传统推荐相比,旅游推荐的准确率和用户满意度在很大程度上受到位置、时间、天气、花费、交通、人流量、环境等多种因素的影响[19 ] 。毫无疑问,引入上下文信息越多,得到的推荐结果将会越好,现有研究也都试图综合考虑更多的旅游上下文信息,但是想要获取多种不同渠道的数据是非常困难的,多源异构的数据也将降低推荐模型的效率和时效性。针对此问题,本文提出一种只通过获取旅游网站用户点评页面相关数据,实现数据分析、推荐模型构建和模型性能评价的方法。在采用基于余弦相似度的协同过滤算法的基础上,引入用户在进行旅游决策时最关心的两个因素:时间和景点热度,以达到更好的推荐效果。在寻找相似用户时,现有研究的一般做法是计算目标用户与训练集中每一位用户之间的用户相似度,但实际上训练集中的大部分用户都不会成为目标用户的相似用户,大量无效的计算将对算法的速度和效率产生较大影响。因此,本文提出一种基于“分段用户群”的训练集动态构建方法,以用户的“旅游经验值”作为筛选条件,为每一位目标用户构建与其经验值匹配的训练集,以提高推荐的准确性和有效性。
2 推荐模型构建
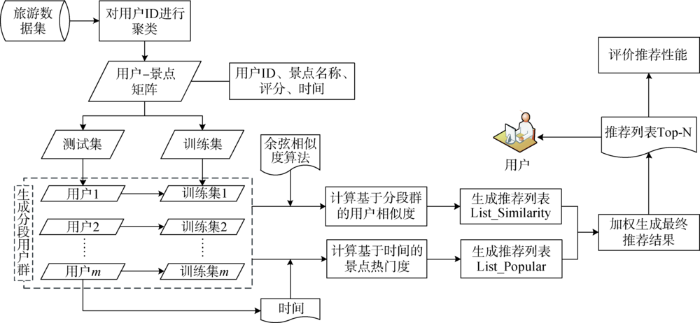
通过挖掘旅游网站用户点评页面的用户ID、用户评分和评论时间等数据,可以分析得到用户去过的景点名称和数量、用户对景点的评分、景点的整体热门程度以及不同月份景点的热门程度等数据。利用以上数据集,可以构建基于用户偏好、景点热度和时间的景点个性化推荐模型。
采集的原始数据是不同景点下不同用户的相关评论信息,因此首先需要对用户ID进行聚类,得到每个用户去过的景点列表,即用户-景点矩阵,同时包含了用户对相应景点的评分和评论时间;筛选出游览景点数不低于景点总数20%的用户作为实验用户,得到实验用户矩阵;接着将实验用户按比例随机分为训练集和测试集,并利用基于“分段用户群”的训练集构建方法为测试集中的每一位用户构建与之对应的新的训练集;然后通过余弦相似度算法为用户寻找相似用户集,生成基于用户相似度的推荐列表,同时通过获取被推荐用户的游览时间,生成基于时间的热门景点推荐列表;最后对两个推荐列表进行加权计算,得到最终推荐结果,并对推荐结果进行评价。模型构建框架如图1 所示。
图1
图1
基于分段用户群与时间上下文的旅游景点推荐模型
Fig.1
Tourist Attractions Recommendation Model Based on Segmented User Group and Time Context
2.1 实验用户矩阵
对于 m n U = { u 1 , u 2 , ⋯ , u m } P = { p 1 , p 2 , ⋯ , p n } U ' U ″
(1) U ' = u 1 , p 1 , s 11 , t 11 u 1 , p 2 , s 12 , t 12 ⋮ u m , p n , s mn , t mn
(2) U ″ = u 1 , q 1 u 2 , q 2 ⋮ u m , q m
其中, S = { s i 1 , s i 2 , ⋯ , s ij } i j T = { t i 1 , t i 2 , ⋯ , t ij } i j Q = { q 1 , q 2 , ⋯ , q m } m
2.2 生成分段用户群
要实现基于用户的协同过滤推荐算法,首先需要通过计算用户间的相似度为目标用户寻找相似用户集,离线实验的一般做法是,将数据集随机分为 M M - 1 A 的相似用户集,用户A 、用户B 、用户C 在训练集中游览过的景点和对该景点的评分为: u a = { p 1 : 5 , p 2 : 4 , p 3 : 5 , p 4 : 5 , p 5 : 4 , p 6 : 3 } u b = { p 1 : 5 , p 3 : 5 } u c = { p 1 : 5 } [20 ] 构建的基于用户评分的推荐模型则会计算出 u b u c u a u b u c u a
为了解决上述问题,本文提出一种基于“用户经验值”和“分段用户群”的训练集构建方法,游览的景点越多,用户的经验值越高,经验值相近的用户可以互相提供推荐。但并不是经验值越高,就越适合给他人做推荐,提供推荐者和被推荐者的经验值相差不应该太大。比如一个资深老影迷与一个只看过少量电影的初级影迷可能会因为都曾对某几部热门影片进行过评分而成为相似用户,但是资深老影迷也许并不适合为初级影迷提供推荐,因为老影迷看过的电影太多,推荐的影片可能带有浓厚的个人偏好,而这些电影也许完全不是初级影迷所喜爱的类型。因此,要为一个已经游览过 n q U n + m ≥ q ≥ n - m m ∈ * ,再从该训练集中为目标用户寻找相似用户。计算分段用户群(Segmented User Group, Sug)的具体算法如下。
算法1 计算分段用户群,为测试集中每一位用户构建新的训练集
输出:集合user_train,包含每一位用户user和与之对应的训练集U
①循环test,获取test中的每一位用户user
通过分段用户群的方法构建训练集有两个优点:在为目标用户寻找相似用户时,可将搜索范围由整个训练集缩小到特定训练集,从而提高搜索效率;寻找到的相似用户与目标用户在“经验值”上更为相近,可为目标用户提供更加准确和有效的推荐。
2.3 寻找相似用户集
计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数。本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息。因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值。因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能。
(3) sim u , v = N ( u ) ⋂ N ( v ) N ( u ) N ( v )
其中, sim u , v u v N u u N v v N u N v
如果两个用户共同去过的景点都十分热门,如武汉的“黄鹤楼”和“东湖”,这实际上并不能说明他们有相似的偏好,因为几乎所有来武汉的游客都会去这两个景点。为了解决这个问题,Breese等[21 ] 提出改进的余弦相似度计算公式。
(4) sim u , v = ∑ i ∈ N ( u ) ⋂ N ( v ) 1 log 1 + N ( i ) N ( u ) N ( v )
该公式通过 1 log ( 1 + N ( i ) ) u v
基于用户评分数据寻找相似用户常用的方法包括欧氏距离和皮尔逊相关系数。对旅游景点的评分与对电影、音乐的评分类似,因为不同用户评分标准不一,会存在某些用户的评分始终比其他用户评分更加“严格”的情况,评分值整体偏低,但二者的分值之差却又始终保持一致,这样的用户之间仍然可能存在较好的相关性[24 ] 。此时,如果使用欧氏距离作为评价标准,则会得出两者不相似的结论。用户评分的平均值可以用来衡量用户评分的标准,皮尔逊相关系数法通过减去某一用户在所有景点评分的平均值避免了由于标准不一而造成的影响。因此,本文选用皮尔逊相关系数寻找基于用户评分的相似用户集。
(5) sim u , v = ∑ i ∈ I r ui - r u ¯ ⋅ r vi - r v ¯ ∑ i ∈ I r ui - r u ¯ 2 ∑ i ∈ I r vi - r v ¯ 2
其中, I u v r ui u i r vi v i r u ¯ u r v ¯ v
2.4 设计推荐算法
(1) 基于用户行为和余弦相似度的协同过滤算法(UserCF)
通过余弦相似度计算得到相似用户集后,选取与目标用户相似度最高的前 K u p [13 ] 所示。
(6) I ( u , p ) = ∑ v ∈ S ( u , K ) ⋂ U ( p ) sim ( u , v )
其中, S ( u , K ) K U ( p ) p sim ( u , v ) u v
输入:用户user,训练集train,用户相似度集sim,排序后的相似用户集user_sim
①获取目标用户user去过的景点集合seen_items
for u in user_sim[user][:K]{
items[item_x] += sim[user][u]
③完成上述循环,得到包含目标用户感兴趣的景点和兴趣值的集合items
④对兴趣值进行降序排列,取前N个景点作为目标用户的Top-N推荐列表
(2)基于用户行为和改进的余弦相似度的协同过滤算法(UserIIF)
该方法相比于UserCF除了在相似度计算时加入了惩罚系数,其推荐算法与算法2完全类似,故不再赘述。
(3)基于用户评分和皮尔逊相关系数的协同过滤算法(ScoreCF)
在得到用户相似度后,利用相似度对用户评分进行加权,得到一个加权的分数值,通过对分数值进行降序排列得到推荐列表。用户 u p
(7) s up = ∑ v ∈ U , p ∈ I sim u , v ⋅ s vp ∑ v ∈ U sim u , v
其中, sim ( u , v ) u v s vp v p U I
输入:用户user,用户-景点-评分集合prefs,用户相似度集sim
①获取目标用户user去过的景点集合seen_items
totals[item_x] += sim[user][u]×prefs[u]
simSums[item_x] += prefs[u]
③完成上述循环,得到景点推荐值集合totals和与景点对应的用户相似度集合simSums
④循环totals和simSums,用推荐值之和除以相似度之和,得到目标用户对未去景点的预测评分值
⑤对预测评分进行降序排列,取前N个景点作为目标用户的Top-N推荐列表
基于用户评分进行推荐的优点是不仅可以得到景点推荐列表,还可以推测用户对未去过景点的评分;缺点是游客对旅游景点的评分往往比较随意,这使得评分并不能很好地反映用户偏好。
(4) 基于相似用户、热门景点和时间上下文的协同过滤算法(SPT)
根据经验可知,用户对景点的选择会受到自身偏好、景点热度和旅游时间的影响,因此,本文提出一种基于相似用户(Similarity)、景点热度(Popular)和时间(Time)的SPT景点推荐算法,如公式(8)所示。
(8) rec u , t = w 1 × rec _ sim + w 2 × rec _ pop t
其中, rec ( u , t ) t u rec _ sim rec _ pop ( t ) t N N w 1 w 2
以上4种推荐算法既可以使用传统训练集实现推荐,也可以通过生成“分段用户群(Sug)”的方法构建新的训练集实现推荐,以SPT算法为例,基于“分段用户群”的SPT算法的实现过程,如公式(9)所示。
(9) rec ( u , t ) = w 1 × rec _ sim ( U n - m ≥ q ≥ n + m ) + w 2 × rec _ pop ( t ) ( U n - m ≥ q ≥ n + m )
其中, U n + m ≥ q ≥ n - m u
①通过算法1和训练集train,计算得到分段用户群集合user_train
②循环test,获取test中的每一位用户user
获取目标用户user的训练集user_train[user]
通过算法2和user_train[user],得到基于用
通过user_train[user],得到基于时间的热
③完成上述循环,为test中的每一位用户提供Top-N的景点推荐
3 实验与分析
3.1 数据集及预处理
从旅游网站携程网(http://www.ctrip.com )的用户评论页面获取武汉市评论数较多的53个景点下28 146位用户的45 505条点评数据。每一条数据都包含用户ID(userId)、景点名称(attractions)、评论内容(content)、评论时间(date)和评分(score)等信息,如表1 所示。
本次实验只需用户ID、景点名称、月份和评分数据,对原数据集进行初步处理,得到如表2 所示的数据集。为了使实验结果更加可靠,需进一步对数据集进行预处理。
(1)删除重复评论。如果同一用户在同一月份对同一景点进行多次评论,即使评论内容不一样,也认为这样的评论属于重复评论。但是如果同一用户在不同月份对同一景点进行评论,则认为这样的评论属于有效评论。因此,删除数据集中userId、attractions、month均相同的重复数据;
(2)计算每个用户游览过的景点数量。如果用户对某景点进行过评分,则认为用户已经游览过该景点,因此通过对userId进行聚类,可以计算出每个用户游览过的景点数量,用num表示;
(3)构建用户-景点-时间-评分矩阵。以步骤(2)计算的num为主键,进行降序排列,得到每个用户去过的景点列表,以及相应的时间和评分,如表3 所示。
数据预处理后,得到实验数据集包含28 146个用户产生的39 439条数据。
3.2 景点热度影响因素分析
景点评论数反映景点热度,绝大部分游客在进行旅游决策时,都会先查询旅游目的地的热门景点排名,然后从排名中选取自己感兴趣的景点。但某一景点的热门程度不是固定不变的,往往会因时间、价格、交通、游客偏好等因素的改变而改变,下面将利用旅游数据集分析时间和游客“旅游经验值”两个因素对不同景点热度的影响。
(1) 通过获取所有景点不同月份总的评论数量,比较不同月份之间武汉市所有景点的总体旅游热门程度,结果如表4 所示。
武汉市旅游最热门的月份依次是10月、4月和5月。10月是国庆黄金周,该月的旅游人数远远超过同季节的9月和11月;3-5月因气候宜人,均是旅游旺季,4月和5月分别有清明假期和五一假期,也使得旅游人数有所增长。通过分析可知,表4 显示的数据与实际情况相符,同时也证明了实验数据集的可靠性和准确性。
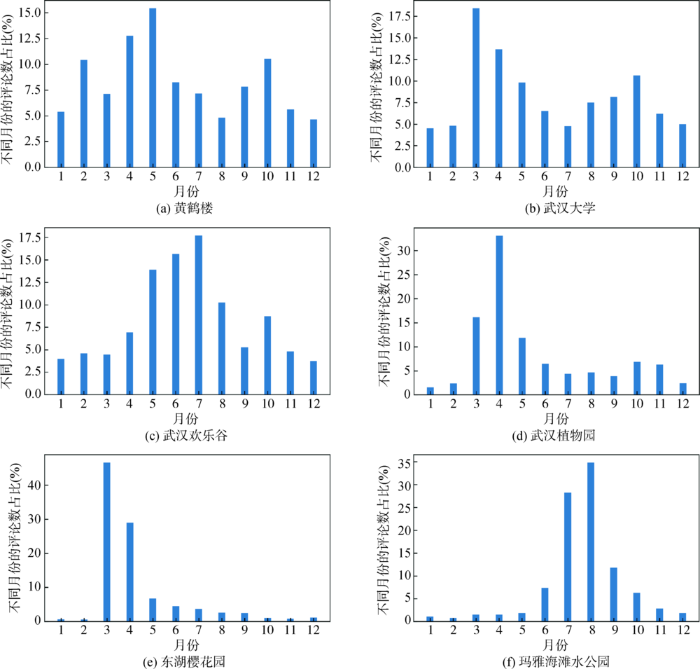
(2) 通过获取不同景点在不同月份的评论数,比较不同景点在不同月份的热门程度。本次实验选取武汉市53个景点中受季节因素影响较大的6个景点进行分析,如图2 所示。
图2
图2
部分景点在不同月份的热门程度
Fig.2
Popularity of Some Attractions in Different Months
“黄鹤楼”的热门程度随月份变化的趋势与表4 中所有景点的总体热门程度随月份变化的趋势相近,4月、5月和10月是其旅游旺季;“武汉大学”在3月的热门程度高于4月、5月和10月,因为武汉大学樱花的盛花期在3月中旬至4月初,这段时期吸引了大量游客;“武汉欢乐谷”在7月最热门,因为去欢乐谷的游客普遍是学生,而7月刚好在暑假期间。“武汉植物园”、“东湖樱花园”和“玛雅海难水公园”的热门程度受月份的影响非常大,这是因为这三个景点均属于季节性景点,“武汉植物园”在3月、4月草木茂盛,因此游客很多;“东湖樱花园”在3月、4月的游客比例与武汉大学十分相似,因为受到樱花花期的影响;“玛雅海滩水公园”是户外水主题乐园,只有在炎热的夏季才会有更多的游客,和图2 中显示的数据一致,7月、8月是“玛雅海滩水公园”的旅游旺季。
通过上述分析可知,时间是影响景点热门程度的一个重要因素。有些景点可以根据经验推测出其最佳游览时节,如“武汉植物园”、“玛雅海滩水公园”等;但有些景点却含有一些影响其热门程度的隐形因素,如“武汉大学”的樱花节。对武汉不熟悉的外地游客,可能并不知道武汉大学有樱花,也不知道樱花的盛花期是什么时候。因此,本文构建的旅游推荐模型中,将时间作为一个重要的影响因素。
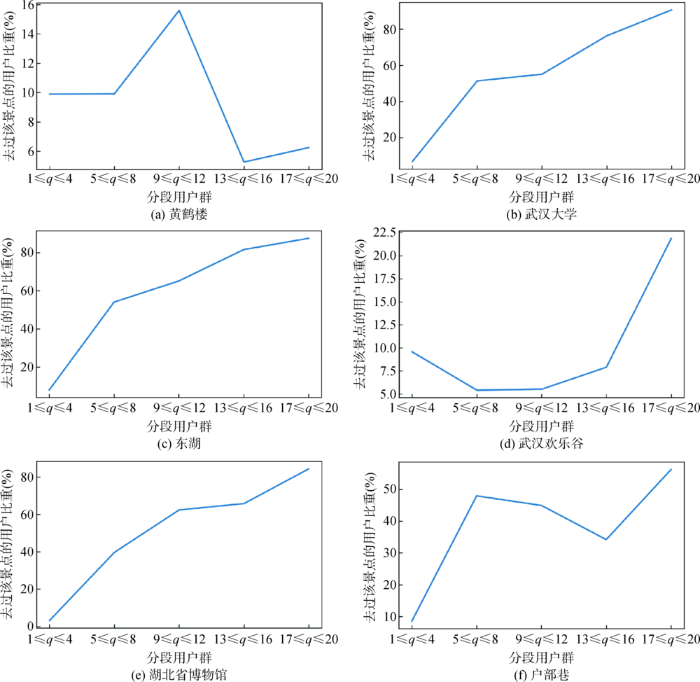
(3) 根据用户游览过的景点数量对用户进行分段,比较不同景点在不同分段用户群中受欢迎的程度。本次实验选取武汉市53个景点中最热门的6个景点进行分析,结果如图3 所示。其中横坐标刻度值“ q q 9 ≤ q ≤ 12 图3 可知,在旅游经验更丰富的用户群中,“武汉大学”、“东湖”、“湖北省博物馆”的受欢迎程度在不断增加, q ≥ 17 13 ≤ q ≤ 16 q ≥ 17
图3
图3
部分景点在分段用户群中受欢迎的程度
Fig.3
Popularity of Some Attractions Among Segmented User Group
通过上述分析可知,不同的用户群具有不一样的游览偏好。相比在全集中寻找相近用户而言,先寻找经验值相近的用户群,再寻找偏好相似的用户是一种更高效、也更容易找到有效相似用户的方法。因此,可以通过这种方法构建用户训练集,提供更加准确的推荐。
3.3 性能评价指标
使用准确率(Precision)、召回率(Recall)、覆盖率(Coverage)和平均流行度(Popularity)[25 ] 等4个指标评测各种算法的性能,指标定义如下。
(10) Precision = ∑ u ∈ U R u ⋂ T u ∑ u ∈ U R u
(11) Recall = ∑ u ∈ U R u ⋂ T u ∑ u ∈ U T u
(12) Coverage = ∪ u ∈ U R u I
(13) Popularity = ∑ i ∈ I ( u ) item _ pop ( i ) N
以上公式中, R ( u ) T ( u ) I item _ pop ( i ) i N
3.4 算法性能分析
通过已构建的离线旅游数据集,比较不同推荐算法的实际性能,算法使用Python语言实现。
(1) 比较不同推荐算法的性能。包括随机推荐算法(Random)、基于热门景点的推荐算法(Popular)、ScoreCF、UserCF、UserIIF、SPT。其中,经多次实验,发现SPT算法中加权系数分别取值 w 1 w 2 表5 所示。
在准确率上,Random算法最低,SPT算法最高,而Popular算法虽然与Rondom算法一样,都是非个性化推荐算法,但准确率却达到41.99%,与UserCF、UserIIF、SPT等个性化推荐算法接近。这是因为几乎所有游客到达某个城市后都会优先游览该地区的热门景点,而绝大多数旅游网站也是直接根据景点的热门程度为用户提供推荐,导致游客在选择景点时,在很大程度上受到景点热门程度的影响;在召回率上,ScoreCF算法最低,同时ScoreCF算法在准确率上的表现也不佳,这说明根据预测用户评分的方法为用户提供Top-N推荐并不是一个好的选择,至少在推荐旅游景点上,应该把预测评分和提供Top-N推荐分成两个不同的问题来对待;在覆盖率和流行度上,由表5 中数据可知,覆盖率和平均流行度的变化趋势相反,这是因为推荐物品的平均流行度越高,说明推荐的物品越热门,从而覆盖率就会降低。Popular算法的平均流行度最高,覆盖率最低,Random算法与之刚好相反,这是因为Popular算法只推荐最热门的景点,而Random算法在随机推荐的过程中会将一些冷门的景点推荐给用户。总的来看,在准确率、召回率、覆盖率和流行度等4个指标上,SPT算法相较于Popular、UserCF、UserIIF都具有更好的推荐性能。
(2) 比较Top-N在不同取值时,SPT算法的推荐性能,实验结果如表6 所示。
当N=5时,算法具有最高的准确率,但此时召回率很低,因为测试集中的用户待预测的景点数大约为4至15个,对于待预测景点数较多的用户,如果只为其推荐5个景点,显然推荐成功的概率会很大,因此准确率较高。随着N取值的逐渐增大,算法的准确率开始降低,但召回率不断升高。N的取值既要考虑各项指标的表现,也应该考虑到算法的实际应用场景,因为本次研究推荐的内容是旅游景点,综合考虑用户的实际需求和各项指标的性能表现,认为N=10是比较合适的选择。
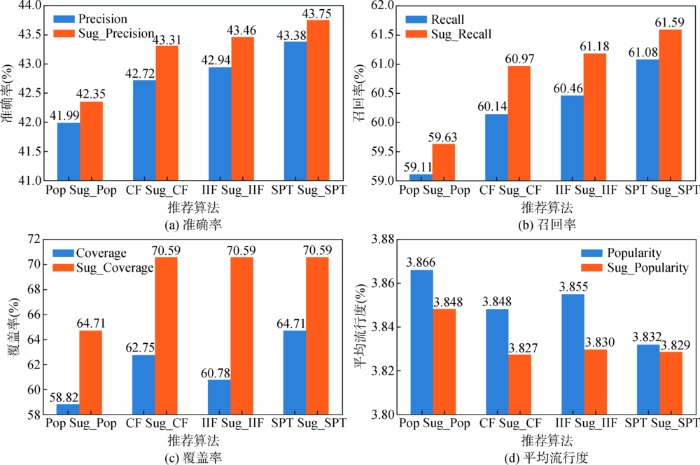
(3) 比较不同算法在分段用户群下的性能。算法Popular、UserCF、UserCF分别以Pop、CF和IIF表示,分段用户群下的各种算法分别以Sug_Pop、Sug_CF、Sug_IIF、Sug_SPT表示。经多次实验,Sug中的参数 m 图4 所示。
图4
图4
不同算法在分段用户群下的性能比较(Top10)
Fig.4
Performance of Different Algorithms Under Segmented User Group (Top10)
不论是非个性化推荐算法Popular,还是个性化推荐算法UserCF、UserIIF和SPT,基于分段用户群的训练集构建方法都使算法性能得到提升。同时,基于分段用户群的方法将相似用户的搜索范围缩小为与目标用户“经验值”相近的用户群,而不需在整个训练集中进行搜索,因此提高了搜索效率。
综上所述,通过以上实验的对比分析,可以发现本文提出的Sug_SPT推荐算法在旅游景点的个性化推荐上相较于传统方法具有更好的推荐性能。
4 结语
针对旅游推荐时影响因素多,但多源数据获取难的问题,本文提供一种通过旅游网站用户评论页面实现数据获取、数据分析、推荐模型构建和模型性能评价的完整方法,并利用旅游网站的真实数据集验证了方法的可行性。本文的主要贡献包括:
(1)提出一种基于用户相似度、景点热度和时间的旅游景点个性化推荐算法SPT,实验表明,该算法相比于传统的协同推荐算法具有更好的推荐性能;
(2)提出一种基于“分段用户群”的训练集构建方法,该方法提高了目标用户寻找相似用户的效率,同时实验表明,不论是各种传统的协同推荐算法还是本文提出的推荐算法SPT,基于“分段用户群”的训练集构建方法都能使算法性能得到进一步提升。
本文的局限性包括两个方面:一是新用户的冷启动问题,实验使用的是离线数据集,数据集中的所有用户都已经积累了一定的历史游览数据,但是对于新用户而言,将无法为其寻找到相似用户集,SPT推荐算法在为新用户提供推荐时,将为其首先推荐基于时间的热门景点列表以解决冷启动问题;二是“分段用户群”方法只在本文的旅游数据集上进行了验证,若要验证该方法的适用范围和性能,需在多种不同的数据集上进行实验。
在未来的研究计划中,将继续探究通过“分段用户群”寻找相似用户的优缺点,研究如何构建更有效的训练数据集;将旅游景点推荐和旅游路线推荐相结合,综合考虑天气、用户位置等上下文信息和影响因素,设计基于位置服务的更加智能的旅游推荐系统。
作者贡献声明
郑淞尹:设计研究方案,数据采集,实验分析,论文撰写与修订;
支撑数据
支撑数据由作者自存储,E-mail: zhengsongyin@126.com。
[1] 郑淞尹.xiecheng_spider_wuhan_attractions.xls.武汉旅游景点原始数据集.
[2] 郑淞尹.user_attractions.csv.实验数据集.
[3] 郑淞尹.user_attractions.ipynb.数据预处理程序.
[4] 郑淞尹.algorithm_experiment.ipynb.推荐算法实验程序.
[5] 郑淞尹.drawing.ipynb.实验结果图绘制程序.
参考文献
View Option
[1]
中华人民共和国文化与旅游部 .2018年旅游市场基本情况
[EB/OL]. [ 2019 - 02 - 12 ]. http://zwgk.mct.gov.cn/auto255/201902/t20190212_837271.html.
URL
[本文引用: 1]
( Ministry of Culture and Tourism of the People’s Republic of China . Basic Situation of Tourism Market in 2018
[EB/OL]. [ 2019 - 02 - 12 ]. http://zwgk.mct.gov.cn/auto255/201902/t20190212_837271.html.)
URL
[本文引用: 1]
[2]
乔向杰 , 张凌云 . 近十年国外旅游推荐系统的应用研究
[J]. 旅游学刊 , 2014 ,29 (8 ):117 -127 .
[本文引用: 1]
( Qiao Xiangjie Zhang Lingyun . Overseas Applied Studies on Travel Recommender Systems in the Past Ten Years
[J]. Tourism Tribune , 2014 ,29 (8 ):117 -127 .)
[本文引用: 1]
[3]
匡海丽 , 常亮 , 宾辰忠 , 等 . 上下文感知旅游推荐系统研究综述
[J]. 智能系统学报 , 2019 ,14 (4 ):611 -618 .
[本文引用: 1]
( Kuang Haili Chang Liang Bin Chenzhong , et al . Review of a Context-aware Travel Recommendation System
[J]. CAAI Transactions on Intelligent Systems , 2019 ,14 (4 ):611 -618 .)
[本文引用: 1]
[4]
Fenza G Fischetti E Furno D , et al . A Hybrid Context Aware System for Tourist Guidance Based on Collaborative Filtering
[C]// Proceedings of the 2011 IEEE International Conference on Fuzzy Systems. 2011 .
[本文引用: 1]
[5]
Alptekin G I Büyüközkan G . An Integrated Case-based Reasoning and MCDM System for Web Based Tourism Destination Planning
[J]. Expert Systems with Applications , 2011 ,38 (3 ):2125 -2132 .
DOI:10.1016/j.eswa.2010.07.153
URL
[本文引用: 1]
[6]
Hsu F M Lin Y T Ho T K . Design and Implementation of an Intelligent Recommendation System for Tourist Attractions: The Integration of EBM Model, Bayesian Network and Google Maps
[J]. Expert Systems with Applications , 2012 ,39 (3 ):3257 -3264 .
DOI:10.1016/j.eswa.2011.09.013
URL
[本文引用: 1]
[7]
Nilashi M bin Ibrahim O Ithnin N , et al . A Multi-criteria Collaborative Filtering Recommender System for the Tourism Domain Using Expectation Maximization (EM) and PCA-ANFIS
[J]. Electronic Commerce Research and Applications , 2015 ,14 (6 ):542 -562 .
[本文引用: 1]
[8]
Moreno A Valls A Isern D , et al . Sigtur/e-destination: Ontology-based Personalized Recommendation of Tourism and Leisure Activities
[J]. Engineering Applications of Artificial Intelligence , 2013 ,26 (1 ):633 -651 .
[本文引用: 1]
[9]
Dodwad P R Lobo L . A Context-aware Recommender System Using Ontology Based Approach for Travel Applications
[J]. International Journal of Advanced Engineering and Nano Technology , 2014 ,1 (10 ):8 -12 .
[本文引用: 1]
[10]
Niaraki A S Kim K . Ontology Based Personalized Route Planning System Using a Multi-criteria Decision Making Approach
[J]. Expert Systems with Applications , 2009 ,36 (2 ):2250 -2259 .
DOI:10.1016/j.eswa.2007.12.053
URL
[本文引用: 1]
[11]
Al-Hassan M Lu H Lu J . A Semantic Enhanced Hybrid Recommendation Approach: A Case Study of e-Government Tourism Service Recommendation System
[J]. Decision Support Systems , 2015 ,72 :97 -109 .
[本文引用: 1]
[12]
Borràs J Moreno A Valls A . Intelligent Tourism Recommender Systems: A Survey
[J]. Expert Systems with Applications , 2014 ,41 (16 ):7370 -7389 .
[本文引用: 1]
[13]
项亮 . 推荐系统实践 [M]. 北京 : 人民邮电出版社 , 2012 .
[本文引用: 4]
( Xiang Liang Recommendation System Practice [M]. Beijing : Posts and Telecommunications Press , 2012 .)
[本文引用: 4]
[14]
Noguera J M Barranco M J Segura R J , et al . A Mobile 3D-GIS Hybrid Recommender System for Tourism
[J]. Information Sciences , 2012 ,215 :37 -52 .
[本文引用: 1]
[15]
Horozov T Narasimhan N Vasudevan V . Using Location for Personalized POI Recommendations in Mobile Environments
[C]// Proceedings of the 2006 International Symposium on Applications and the Internet (SAINT’06). IEEE , 2006 .
[本文引用: 1]
[16]
李广丽 , 朱涛 , 滑瑾 , 等 . 混合分层抽样统计与贝叶斯个性化排序的旅游景点推荐模型研究
[J]. 华中师范大学学报:自然科学版 , 2019 ,53 (2 ):214 -220 .
[本文引用: 1]
( Li Guangli Zhu Tao Hua Jin , et al . Hybrid Recommendation System for Tourist Spots Based on Hierarchical Sampling Statistics and Bayesian Personalized Ranking
[J]. Journal of Central China Normal University: Natural Sciences , 2019 ,53 (2 ):214 -220 .)
[本文引用: 1]
[17]
王志强 , 文益民 , 李芳 . 基于多方面评分的景点协同推荐算法
[J]. 山东大学学报: 工学版 , 2016 ,47 (6 ):54 -61 .
[本文引用: 1]
( Wang Zhiqiang Wen Yimin Li Fang . Collaborative Recommendation for Scenic Based on Multi-aspect Ratings
[J]. Journal of Shandong University: Engineering Sciences , 2016 ,47 (6 ):54 -61 .)
[本文引用: 1]
[18]
李雅美 , 王昌栋 . 基于标签的个性化旅游推荐
[J]. 中国科学技术大学学报 , 2017 ,47 (7 ):547 -555 .
[本文引用: 1]
( Li Yamei Wang Changdong . Tag-based Personalized Travel Recommendation
[J]. Journal of University of Science and Technology of China , 2017 ,47 (7 ):547 -555 .)
[本文引用: 1]
[19]
Liu Q Chen E Xiong H , et al . A Cocktail Approach for Travel Package Recommendation
[J]. IEEE Transactions on Knowledge and Data Engineering , 2012 ,26 (2 ):278 -293 .
DOI:10.1109/TKDE.2012.233
URL
[本文引用: 1]
[20]
Segaran T . 集体智慧编程 [M]. 莫映, 王开福译. 北京 :电子工业出版社 , 2009 .
[本文引用: 1]
( Segaran T . Programming Collective Intelligence [M]. Translated by Mo Ying, Wang Kaifu. Beijing : Publishing House of Electronics Industry , 2009 .)
[本文引用: 1]
[21]
武永亮 , 赵书良 , 李长镜 , 等 . 基于TF-IDF和余弦相似度的文本分类方法
[J]. 中文信息学报 , 2017 ,31 (5 ):138 -145 .
[本文引用: 2]
( Wu Yongliang Zhao Shuliang Li Changjing , et al . Text Classification Method Based on TF-IDF and Cosine Similarity
[J]. Journal of Chinese Information Processing , 2017 ,31 (5 ):138 -145 .)
[本文引用: 2]
[22]
Breese J S Heckerman D Kadie C . Empirical Analysis of Predictive Algorithms for Collaborative Filtering
[C]// Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence. 1998 .
[本文引用: 1]
[23]
俞婷婷 , 徐彭娜 , 江育娥 , 等 . 基于改进的Jaccard系数文档相似度计算方法
[J]. 计算机系统应用 , 2017 ,26 (12 ):137 -142 .
[本文引用: 1]
( Yu Tingting Xu Pengna Jiang Yu’e , et al . Text Similarity Method Based on the Improved Jaccard Coefficient
[J]. Computer Systems and Applications , 2017 ,26 (12 ):137 -142 .)
[本文引用: 1]
[24]
Wang C Song Y Li H , et al . Distant Meta-path Similarities for Text-based Heterogeneous Information Networks
[C]// Proceedings of the 2017 ACM Conference on Information and Knowledge Management. ACM , 2017 : 1629 -1638 .
[本文引用: 2]
[25]
Levy M Bosteels K . Music Recommendation and the Long Tail
[C]// Proceedings of the 1st Workshop on Music Recommendation and Discovery. 2010 .
[本文引用: 1]
2018年旅游市场基本情况
1
2019
... 据文化和旅游部统计数据[1 ] 显示,2018年中国旅游人数达55.39亿人次,全年实现旅游总收入5.97万亿元,全年全国旅游业对GDP的综合贡献为9.94万亿元,占GDP总量的11.04%.旅游市场的高速增长说明人们对旅游的需求越来越大,而不同的旅游者往往有着不同的旅游目的,或是放松身心,或是探索知识.大多数旅游者在出行前都会查询相关旅游信息,但随着网络信息的爆炸式增长,很难从网站提供的众多产品和服务中选取适合自己的产品.国内具有代表性的旅游景点推荐网站如携程、马蜂窝等,也仅仅提供了大众化的旅游信息,如“当季推荐”、“主题精选”等.如何满足不同爱好、不同目的的旅游者不同的旅游需求,让旅游者能更加高效地做出旅游决策,是一个值得研究的问题. ...
2018年旅游市场基本情况
1
2019
... 据文化和旅游部统计数据[1 ] 显示,2018年中国旅游人数达55.39亿人次,全年实现旅游总收入5.97万亿元,全年全国旅游业对GDP的综合贡献为9.94万亿元,占GDP总量的11.04%.旅游市场的高速增长说明人们对旅游的需求越来越大,而不同的旅游者往往有着不同的旅游目的,或是放松身心,或是探索知识.大多数旅游者在出行前都会查询相关旅游信息,但随着网络信息的爆炸式增长,很难从网站提供的众多产品和服务中选取适合自己的产品.国内具有代表性的旅游景点推荐网站如携程、马蜂窝等,也仅仅提供了大众化的旅游信息,如“当季推荐”、“主题精选”等.如何满足不同爱好、不同目的的旅游者不同的旅游需求,让旅游者能更加高效地做出旅游决策,是一个值得研究的问题. ...
近十年国外旅游推荐系统的应用研究
1
2014
... 近年来,推荐系统被认为是解决信息超载问题的有效方法,已经被广泛应用于图书、电影、音乐和网页的个性化推荐上.推荐系统在旅游领域的具体应用,既包括对景点、酒店、餐馆、航班等的推荐,也包括对旅游目的地、旅游计划、旅游包等涵盖多项产品、活动与服务等组合内容的推荐[2 ] .用户根据自己出游的目的和计划,也会对推荐系统有着不同的需求.短期出游的用户通常希望能获得旅游景点和旅游线路的推荐,而出游时间较长的用户则希望推荐系统能结合自己的时间、位置、旅游目的地的天气和消费水平等信息提供多元化的推荐[3 ] . ...
近十年国外旅游推荐系统的应用研究
1
2014
... 近年来,推荐系统被认为是解决信息超载问题的有效方法,已经被广泛应用于图书、电影、音乐和网页的个性化推荐上.推荐系统在旅游领域的具体应用,既包括对景点、酒店、餐馆、航班等的推荐,也包括对旅游目的地、旅游计划、旅游包等涵盖多项产品、活动与服务等组合内容的推荐[2 ] .用户根据自己出游的目的和计划,也会对推荐系统有着不同的需求.短期出游的用户通常希望能获得旅游景点和旅游线路的推荐,而出游时间较长的用户则希望推荐系统能结合自己的时间、位置、旅游目的地的天气和消费水平等信息提供多元化的推荐[3 ] . ...
上下文感知旅游推荐系统研究综述
1
2019
... 近年来,推荐系统被认为是解决信息超载问题的有效方法,已经被广泛应用于图书、电影、音乐和网页的个性化推荐上.推荐系统在旅游领域的具体应用,既包括对景点、酒店、餐馆、航班等的推荐,也包括对旅游目的地、旅游计划、旅游包等涵盖多项产品、活动与服务等组合内容的推荐[2 ] .用户根据自己出游的目的和计划,也会对推荐系统有着不同的需求.短期出游的用户通常希望能获得旅游景点和旅游线路的推荐,而出游时间较长的用户则希望推荐系统能结合自己的时间、位置、旅游目的地的天气和消费水平等信息提供多元化的推荐[3 ] . ...
上下文感知旅游推荐系统研究综述
1
2019
... 近年来,推荐系统被认为是解决信息超载问题的有效方法,已经被广泛应用于图书、电影、音乐和网页的个性化推荐上.推荐系统在旅游领域的具体应用,既包括对景点、酒店、餐馆、航班等的推荐,也包括对旅游目的地、旅游计划、旅游包等涵盖多项产品、活动与服务等组合内容的推荐[2 ] .用户根据自己出游的目的和计划,也会对推荐系统有着不同的需求.短期出游的用户通常希望能获得旅游景点和旅游线路的推荐,而出游时间较长的用户则希望推荐系统能结合自己的时间、位置、旅游目的地的天气和消费水平等信息提供多元化的推荐[3 ] . ...
A Hybrid Context Aware System for Tourist Guidance Based on Collaborative Filtering
1
2011
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
An Integrated Case-based Reasoning and MCDM System for Web Based Tourism Destination Planning
1
2011
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
Design and Implementation of an Intelligent Recommendation System for Tourist Attractions: The Integration of EBM Model, Bayesian Network and Google Maps
1
2012
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
A Multi-criteria Collaborative Filtering Recommender System for the Tourism Domain Using Expectation Maximization (EM) and PCA-ANFIS
1
2015
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
Sigtur/e-destination: Ontology-based Personalized Recommendation of Tourism and Leisure Activities
1
2013
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
A Context-aware Recommender System Using Ontology Based Approach for Travel Applications
1
2014
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
Ontology Based Personalized Route Planning System Using a Multi-criteria Decision Making Approach
1
2009
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
A Semantic Enhanced Hybrid Recommendation Approach: A Case Study of e-Government Tourism Service Recommendation System
1
2015
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
Intelligent Tourism Recommender Systems: A Survey
1
2014
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
4
2012
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
... (1) 余弦相似度[13 ] ...
... 通过余弦相似度计算得到相似用户集后,选取与目标用户相似度最高的前 K u p [13 ] 所示. ...
4
2012
... 目前,旅游推荐的方法包括:基于协同过滤的推荐[4 ,5 ,6 ,7 ] 、基于内容的推荐[8 ] 、基于知识的推荐[9 ,10 ] 和混合推荐[11 ,12 ] .其中,基于用户的协同过滤算法是推荐系统中应用最广泛的算法[13 ] .但是协同过滤算法存在数据稀疏和冷启动问题,旅游相比电影和音乐是一项成本较高的活动,用户的旅游数据往往比较稀疏,因此如何将协同过滤技术应用于个性化旅游推荐系统,并解决上述问题,是研究的重点. ...
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
... (1) 余弦相似度[13 ] ...
... 通过余弦相似度计算得到相似用户集后,选取与目标用户相似度最高的前 K u p [13 ] 所示. ...
A Mobile 3D-GIS Hybrid Recommender System for Tourism
1
2012
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
Using Location for Personalized POI Recommendations in Mobile Environments
1
2006
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
混合分层抽样统计与贝叶斯个性化排序的旅游景点推荐模型研究
1
2019
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
混合分层抽样统计与贝叶斯个性化排序的旅游景点推荐模型研究
1
2019
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
基于多方面评分的景点协同推荐算法
1
2016
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
基于多方面评分的景点协同推荐算法
1
2016
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
基于标签的个性化旅游推荐
1
2017
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
基于标签的个性化旅游推荐
1
2017
... Noguera等[14 ] 为移动端设计了一个基于位置服务的旅游推荐系统,采用基于协同过滤和基于知识的混合方法解决了冷启动问题,系统可以根据用户的偏好和所在位置为其推荐最适合的餐馆和旅游景点;Horozov等[15 ] 通过引入虚拟用户对餐馆进行分类和评分,解决协同过滤算法的冷启动问题,从而使得在数据稀疏的情况下也能找到相似用户并为目标用户提供推荐;李广丽等[16 ] 认为传统的协同过滤旅游推荐模型仅处理了稀疏的评分数据,未深入挖掘用户及对象的潜在语义,且用户的喜好信息也未充分利用,因此提出混合分层抽样统计与贝叶斯个性化排序的推荐模型,实验结果表明新模型具有更好的推荐性能;王志强等[17 ] 针对传统协同过滤景点推荐模型仅利用景点总体评分进行用户相似度计算,而无法准确反映用户对景点不同方面的感受,提出综合利用用户对景点在景色、性价比、趣味性等三个方面的评分计算用户之间的相似性,实验结果表明在引入多维评分信息后,推荐结果的准确率、覆盖率、均方根误差、平均绝对误差都得到了改善;李雅美等[18 ] 针对旅游数据的稀疏性问题,提出从海量的游记中提取地域、类型、主题和时间等4个与景点相关的因素丰富数据信息,同时采用线性加权的方式混合基于标签的协同过滤算法和基于标签内容的推荐算法,实验证明混合算法有效提高了推荐结果的准确率. ...
A Cocktail Approach for Travel Package Recommendation
1
2012
... 通过对现有研究分析可知,与传统推荐相比,旅游推荐的准确率和用户满意度在很大程度上受到位置、时间、天气、花费、交通、人流量、环境等多种因素的影响[19 ] .毫无疑问,引入上下文信息越多,得到的推荐结果将会越好,现有研究也都试图综合考虑更多的旅游上下文信息,但是想要获取多种不同渠道的数据是非常困难的,多源异构的数据也将降低推荐模型的效率和时效性.针对此问题,本文提出一种只通过获取旅游网站用户点评页面相关数据,实现数据分析、推荐模型构建和模型性能评价的方法.在采用基于余弦相似度的协同过滤算法的基础上,引入用户在进行旅游决策时最关心的两个因素:时间和景点热度,以达到更好的推荐效果.在寻找相似用户时,现有研究的一般做法是计算目标用户与训练集中每一位用户之间的用户相似度,但实际上训练集中的大部分用户都不会成为目标用户的相似用户,大量无效的计算将对算法的速度和效率产生较大影响.因此,本文提出一种基于“分段用户群”的训练集动态构建方法,以用户的“旅游经验值”作为筛选条件,为每一位目标用户构建与其经验值匹配的训练集,以提高推荐的准确性和有效性. ...
1
2009
... 要实现基于用户的协同过滤推荐算法,首先需要通过计算用户间的相似度为目标用户寻找相似用户集,离线实验的一般做法是,将数据集随机分为 M M - 1 A 的相似用户集,用户A 、用户B 、用户C 在训练集中游览过的景点和对该景点的评分为: u a = { p 1 : 5 , p 2 : 4 , p 3 : 5 , p 4 : 5 , p 5 : 4 , p 6 : 3 } u b = { p 1 : 5 , p 3 : 5 } u c = { p 1 : 5 } [20 ] 构建的基于用户评分的推荐模型则会计算出 u b u c u a u b u c u a
1
2009
... 要实现基于用户的协同过滤推荐算法,首先需要通过计算用户间的相似度为目标用户寻找相似用户集,离线实验的一般做法是,将数据集随机分为 M M - 1 A 的相似用户集,用户A 、用户B 、用户C 在训练集中游览过的景点和对该景点的评分为: u a = { p 1 : 5 , p 2 : 4 , p 3 : 5 , p 4 : 5 , p 5 : 4 , p 6 : 3 } u b = { p 1 : 5 , p 3 : 5 } u c = { p 1 : 5 } [20 ] 构建的基于用户评分的推荐模型则会计算出 u b u c u a u b u c u a
基于TF-IDF和余弦相似度的文本分类方法
2
2017
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
... 如果两个用户共同去过的景点都十分热门,如武汉的“黄鹤楼”和“东湖”,这实际上并不能说明他们有相似的偏好,因为几乎所有来武汉的游客都会去这两个景点.为了解决这个问题,Breese等[21 ] 提出改进的余弦相似度计算公式. ...
基于TF-IDF和余弦相似度的文本分类方法
2
2017
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
... 如果两个用户共同去过的景点都十分热门,如武汉的“黄鹤楼”和“东湖”,这实际上并不能说明他们有相似的偏好,因为几乎所有来武汉的游客都会去这两个景点.为了解决这个问题,Breese等[21 ] 提出改进的余弦相似度计算公式. ...
Empirical Analysis of Predictive Algorithms for Collaborative Filtering
1
1998
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
基于改进的Jaccard系数文档相似度计算方法
1
2017
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
基于改进的Jaccard系数文档相似度计算方法
1
2017
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
Distant Meta-path Similarities for Text-based Heterogeneous Information Networks
2
2017
... 计算用户相似度常见方法包括:余弦相似度[13 ,21 ] 、改进的余弦相似度[22 ] 、Jaccard相似度[23 ] 、欧氏距离[24 ] 和皮尔逊相关系数.本文的实验数据集包含用户ID、景点名称、评分和时间等数据,其中用户ID、景点名称是隐反馈数据,用户对景点的评分是显反馈数据,评分时间是上下文信息.因为本文重点研究的是推荐的景点是否被用户喜欢,而不是预测用户对该景点的评分值.因此将基于最常用的余弦相似度和隐反馈数据实现Top-N的推荐,同时也会基于皮尔逊相关系数和显反馈数据预测用户对推荐景点的评分,预测评分的目的是根据评分的高低顺序为用户提供Top-N的景点推荐,并对比不同算法的性能. ...
... 基于用户评分数据寻找相似用户常用的方法包括欧氏距离和皮尔逊相关系数.对旅游景点的评分与对电影、音乐的评分类似,因为不同用户评分标准不一,会存在某些用户的评分始终比其他用户评分更加“严格”的情况,评分值整体偏低,但二者的分值之差却又始终保持一致,这样的用户之间仍然可能存在较好的相关性[24 ] .此时,如果使用欧氏距离作为评价标准,则会得出两者不相似的结论.用户评分的平均值可以用来衡量用户评分的标准,皮尔逊相关系数法通过减去某一用户在所有景点评分的平均值避免了由于标准不一而造成的影响.因此,本文选用皮尔逊相关系数寻找基于用户评分的相似用户集. ...
Music Recommendation and the Long Tail
1
2010
... 使用准确率(Precision)、召回率(Recall)、覆盖率(Coverage)和平均流行度(Popularity)[25 ] 等4个指标评测各种算法的性能,指标定义如下. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}