




1 引言
在数据采集技术和数据存储设备快速发展的大环境下,多种针对数据分析、挖掘的应用应运而生。在学术研究过程中同样需要数据分析的应用,如期刊论文的分类研究。目前,在论文文献分类中还没有普遍使用的统一标准。由于期刊数量和投稿人数量逐年增加,论文的增长趋势也不容小觑[1]。长期以来,由于审稿周期较长、稿件本身的时效性使得一些投稿人未能遵守底线,一稿多投和一文多刊的现象层出不穷[2]。早期针对期刊投稿指南的相关研究往往仅给投稿者提出一些主观的期刊投稿建议,如“了解认识期刊”、“了解同行评审和稿件要求”等[3],这些建议缺乏可执行性,在具体操作时仍不能给予投稿者切实有效的帮助。随着信息共享意识的觉醒以及信息系统的普及,相关学者提出构建期刊投稿网络系统的设想,希望通过多家期刊共同参与,建设一个科学、透明、共享的投稿平台[2]。
对于一篇具体的论文,篇幅一般较长,具有包含大量信息的特殊性。为了有效提取文本的关键信息,在进行文本分类时,常选择对能够容纳一篇论文最为核心信息的题录信息进行处理[4],从而更精准地概括文献的内外部特征,进一步挖掘出期刊收录偏好特征。
综上,本文以图书馆学、情报学(Library and Information Science,LIS)学科SSCI收录期刊为例,获取该学科期刊10年内收录文献的题录信息,挖掘收录偏好特征相近的期刊进行聚类后构建层次体系结构,然后通过机器学习和深度学习的方法对该层次分类模型进行验证,选择最优的特征组合和分类算法,根据以上分析结果考虑将内容相似度较高的期刊进行合并,从而获得最佳的期刊投稿推荐意见。
2 相关研究
主流的文本聚类算法包括基于层次的聚类方法和基于划分的聚类方法。除此之外,还有基于网格[12,13]、密度[14,15]、模型[16]的聚类方法。CURE[17]、ROCK[18]、Chameleon[19]是层次聚类中最具代表性的三种算法。层次聚类算法一般适用于小型数据集[20],张雅杰等[21]、言迎等[22]利用层次聚类的方法对连州市和益阳市的土地进行划分。最经典的划分聚类算法当属1967年提出的k-均值(k-means)聚类算法[23],后来大多数划分聚类算法都是基于该方法进行改进,如k-modes算法[24,25]、一致性保留k-means算法[26]等。划分聚类方法的应用较为广泛,如李洋[27]将k-means应用于对入侵检测库和安全级别的构建当中。邢留伟[28]通过k-means算法进行客户数据建模,达到了对客户进行更精准细分的目的。众多学者将机器学习算法和深度学习算法应用于文本分类研究,在专业期刊自动分类[29]、门户网站文本情感分析[30]和新闻文档的主题分类[31]中都取得良好的实验效果。齐玉东等[32]将军事文本文档进行分类实验,分别利用支持向量机(Support Vector Machine,SVM)[33]、卷积神经网络(Convolutional Neural Networks,CNN)[34]、循环神经网络(Recurrent Neural Networks,RNN)[35]等机器学习算法和深度学习算法得到较高的性能。汪少敏等[36]对比了传统机器学习分类算法和深度学习分类算法在文本分类中的效果,在测试集上验证了深度学习算法的优越性。
可见,期刊类目划分逐渐由人工向机器过渡。但在人工类目划分标准下,主观因素难免影响划分结果。针对某一研究领域的期刊一般只有该专业学者才具有类目划分的知识储备,很难形成对多种学科领域具有全方位指导价值的方法体系。这时,机器划分的优势得以体现。很多学者已经利用机器学习算法、深度学习算法在多种文本实验中得到良好的分类结果。一般情况下,随着文本量和语料丰富程度的增加,深度学习常常较机器学习更具优势。在此背景下,本文利用机器学习方法和深度学习方法为期刊论文投稿的多分类问题提供解决方案,同时也为高水平期刊收录内容的差别化探索提供思路。
3 实验设计和优化
3.1 研究框架
为了构建某一学科下的期刊分类体系,本文设计了总体研究框架,如图1所示。以图书馆、情报学学科SSCI期刊为研究对象,选择题名(TIss)、关键词(KWss)、附加关键词(DEss)与摘要(ABss)这4个字段的信息作为实验数据,经过数据预处理后得到每类期刊的期刊术语矩阵。采用余弦相似度的计算公式得到基于期刊题录信息的层次聚类模型。在此模型基础上,选取不同特征来源组合的期刊术语矩阵,按照一定的比例划分训练集和测试集,分别应用机器学习和深度学习算法进行训练,并将输出的结果与测试集的类别矩阵进行比较,得到相应的准确率,进而对不同特征来源组合和不同算法下的分类效果进行分析,确定最合适的特征组合和分类算法。在得到实验结果后,本文尝试将分类结果中的某些易混淆的期刊进行合并再次进行准确率的统计,以期获得更好的分类效果。
图1

3.2 数据来源与初始化
本文数据来自Web of Science数据库。检索范围为LIS学科于2014-2016年连续三年进入前三区 ( 分区标准参见《中国科学院文献情报中心期刊分区表》。)的26种期刊。首先,确定检索年限为2009-2018年,共得到20 297篇文献的题录信息,具体信息如表1所示。
表1 26种期刊详细信息检索表
Table 1
| 编号 | 期刊英文名 | 期刊名缩写 | 篇数 |
|---|---|---|---|
| 1 | COLLEGE & RESEARCH LIBRARIES | C&RL | 770 |
| 2 | EUROPEAN JOURNAL OF INFORMATION SYSTEMS | EJIS | 419 |
| 3 | GOVERNMENT INFORMATION QUARTERLY | GIQ | 723 |
| 4 | INFORMATION PROCESSING & MANAGEMENT | IPM | 707 |
| 5 | INFORMATION SOCIETY | IS | 397 |
| 6 | INFORMATION SYSTEMS JOURNAL | ISJ | 303 |
| 7 | INFORMATION TECHNOLOGY & PEOPLE | ITP | 293 |
| 8 | INTERNATIONAL JOURNAL OF INFORMATION MANAGEMENT | IJIM | 920 |
| 9 | JOURNAL OF ACADEMIC LIBRARIANSHIP | JAL | 1 204 |
| 10 | JOURNAL OF COMPUTER- MEDIATED COMMUNICATION | JCMC | 333 |
| 11 | JOURNAL OF DOCUMENTATION | JOD | 647 |
| 12 | JOURNAL OF HEALTH COMMUNICATION | JHC | 1 313 |
| 13 | JOURNAL OF INFORMETRICS | JOI | 807 |
| 14 | JOURNAL OF STRATEGIC INFORMATION SYSTEMS | JSIS | 238 |
| 15 | JOURNAL OF THE AMERICAN MEDICAL INFORMATICS ASSOCIATION | JAMIA | 1 878 |
| 16 | JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY | JASIST | 992 |
| 17 | JOURNAL OF THE ASSOCIATION FOR INFORMATION SYSTEMS | JAIS | 343 |
| 18 | JOURNAL OF THE MEDICAL LIBRARY ASSOCIATION | JMLA | 843 |
| 19 | LEARNED PUBLISHING | LP | 513 |
| 20 | LIBRARY & INFORMATION SCIENCE RESEARCH | L&ISR | 399 |
| 21 | ONLINE INFORMATION REVIEW | OIR | 867 |
| 22 | RESEARCH EVALUATION | RE | 369 |
| 23 | SCIENTOMETRICS | SCIM | 3 058 |
| 24 | SOCIAL SCIENCE COMPUTER REVIEW | SSCR | 433 |
| 25 | TELECOMMUNICATIONS POLICY | TP | 796 |
| 26 | TELEMATICS AND INFORMATICS | TI | 732 |
表2 单篇文献六元组信息举例
Table 2
| 题录项 | 值 |
|---|---|
| ID | 16 |
| TIss | discov|foodborn|ill|onlin|restaur|review| |
| KWss | machin|learn|social|media|foodborn|disea|text|min|classif| |
| DEss | unit|st|media| |
| ABss | object|develop|system|discoveri|foodborn|ill|mention|onlin|yelp|restaur|review|use|text|classif|system|use|new|york|citi|health|mental|hygien|dohmh|monitor|yelp|foodborn|ill|complaints|materi|method|built|classifi|2|task|1|determin|if| |
| SO | JOURNAL OF THE AMERICAN MEDICAL INFORMATICS ASSOCIATION |
构建期刊术语矩阵作为分类算法的输入,其中期刊术语矩阵的构建方法如公式(1)所示。
其中,JTM为一个
3.3 方法论
(1) 聚类算法
聚类即通过获取数据不同的特征将其划分成不同的类别,本质就是通过一定的方法,使同一类数据间相似度更高,不同类数据间相似度更低[38]。
聚类的步骤一般如下:①文本分词,即将文本分割成有意义的最小单元;②文档特征表示,即用数学表达式的形式将文档特征提取出来;③确定聚类模型。
在本次文本聚类实验中,文本分词的方法如3.2节所述,将收集到的数据导入SATI中得到相应的分词结果即可。文档特征提取的方法一般有两种思路:基于概率和基于语义的提取方式[39]。由于本文的实验数据是论文题录信息的分词结果,词与词之间不存在语义联系,故而首先排除基于语义的提取方式。文档频率[40,41]、互信息[42,43]、信息增益[44,45]都是常见的基于概率的文档特征表示方法,但是基于已有研究[35]中互信息倾向于对罕见词的提取以及信息增益方法操作的繁琐程度,实验最终敲定基于文档频率的特征提取方式。特征选择的常见矩阵形式有0-1矩阵、TF-IDF、TFw、词向量、文本卡方值等。本文实验中,为了凸显题名、关键词、附加关键词与摘要4种字段对于文档特征的不同表征程度,按照题名:关键词:附加关键词:摘要=4∶2∶2∶1的权重构造TFw矩阵作为输入数据。在选择聚类模型时,笔者结合此次数据的特点对第2节梳理的两种主流聚类算法进行取舍。首先,需要建立的期刊分类模型不需要提前给出具体划分的类别数目,不符合划分聚类算法的前提要求;其次,本次实验数据规模较小,符合层次聚类算法的适用条件。因此,最终选定层次聚类法进行实验,进行SSCI期刊分类体系结构的构建。
(2) 分类算法
分类是指将未标明类别的实验数据划分到某一预定标签的类别中。文本分类的步骤一般为:确定分类的类别;清洗、分词等;确定文本特征表示方法;应用文本分类模型训练文本分类器;评价分类器模型并进行文本分类。
在本文实验中,分类的类别已经通过聚类算法构建的分类模型给出。清洗、分词等工作同3.3节聚类算法中文本聚类的处理方法一致。文本特征的表示方法上,选取不同的字段组合作为实验的因变量之一,考虑到实验的复杂性,采用这些不同字段组合的0-1矩阵作为文本特征的提取。因此,本文分类实验的核心问题就落在分类模型的选择和分类效果的评价上。
选择分类模型时,传统的机器学习分类算法有朴素贝叶斯、决策树、K近邻、支持向量机(SVM)等。通过应用场景预判以及前人经验支持[15],当需要分类的文本具有矩阵稀疏、维度较高的特点时,为了得到更好的分类效果和分类效率,SVM算法识别能力好、训练效率高、稳定性强的优势较为明显,因此本文采用SVM 算法进行机器学习部分的建模。随着深度学习算法的日渐成熟,CNN、RNN等算法在多种数据集上都呈现出相较于传统机器学习算法更明显的分类优势。因此,为了对比机器学习与深度学习算法在相同数据集上的实验效果,在SVM算法的基础上,本文尝试使用CNN和RNN算法进行深度学习实验部分的建模。
在进行分类效果评价时,需要考虑以下参数:
①TP_num:正例被分为正例的个数;
②FP_num:负例被分为正例的个数;
③FN_num:正例被分为负例的个数;
④TN_num:负例被分为负例的个数。
定义TP_num+FN_num=P_num,即实际正例个数;FP_num+TN_num=N_num,即实际负例个数。
4 SSCI期刊分类模型构建
4.1 SSCI期刊层次聚类结果
在10年的数据中选取2017年共计2 141篇文献的题录信息在Matlab中进行层次聚类后得到层次聚类效果图,如图2所示。
图2
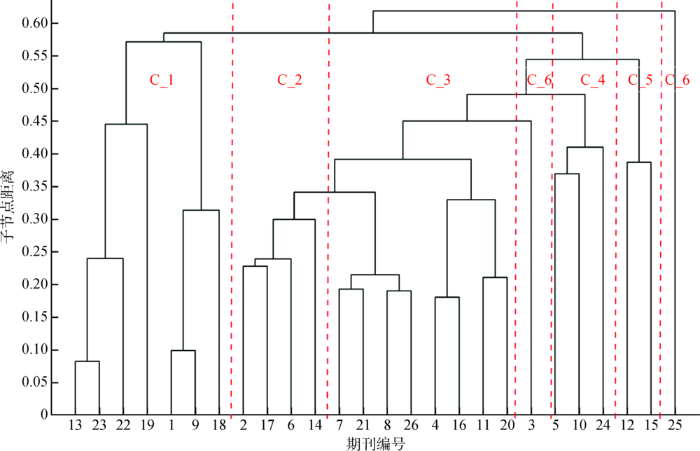
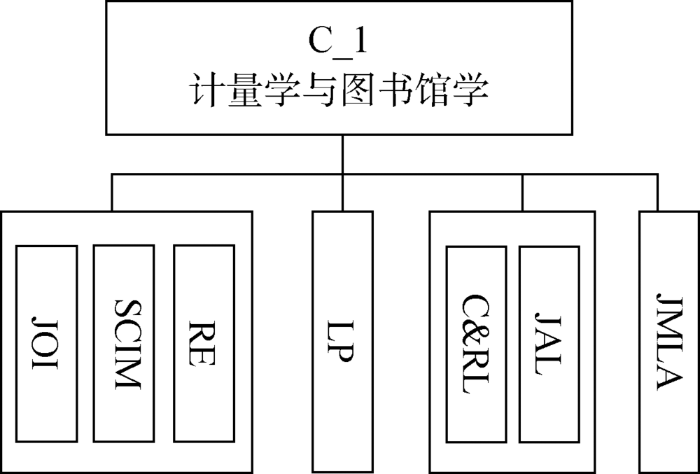
根据以上层次聚类效果图显示的聚类结果,可将26种期刊划分为6个期刊分区,分别为C_1、C_2、C_3、C_4、C_5、C_6,每个期刊分区中所包含的期刊如表3所示。
表3 6个期刊分区包含期刊汇总
Table 3
| 期刊分区 | 期刊缩写 | 期刊编号 |
|---|---|---|
| C_1 | C&RL | 1 |
| JAL | 9 | |
| JOI | 13 | |
| JMLA | 18 | |
| LP | 19 | |
| RE | 22 | |
| SCIM | 23 | |
| C_2 | EJIS | 2 |
| ISJ | 6 | |
| JSIS | 14 | |
| JAIS | 17 | |
| C_3 | ITP | 7 |
| IJIM | 8 | |
| OIR | 21 | |
| TI | 26 | |
| IPM | 4 | |
| JOD | 11 | |
| JASIST | 16 | |
| L&ISR | 20 | |
| C_4 | IS | 5 |
| JCMC | 10 | |
| SSCR | 24 | |
| C_5 | JHC | 12 |
| JAMIA | 15 | |
| C_6 | GIQ | 3 |
| TP | 25 |
结合期刊的具体内容,可以得出以下结论。
(1)C_1中的期刊主要为计量学和图书馆学领域的期刊。例如,在该分区下的期刊RE是一本跨学科的同行评审国际期刊,其官方介绍中的描述“科学计量学与研究评价之间存在着密切的关系”也印证了这一结论。
(2)C_2中的4种期刊都是信息系统领域的专业期刊。在数据爆炸的信息时代,信息系统的设计与研究也发展成为LIS学科一个重要的分支。
(3)C_3中围绕“信息管理”“信息处理”和“信息技术”等出现的关键词则将这些期刊指向情报学这一领域的研究,因为情报学自发展初期就离不开信息管理、处理等环节。
(4)C_4中的期刊更偏向计算机科学领域,这一趋势是伴随着计算机科学愈发走向成熟的产物。
(5)C_5中的两种期刊与健康学、医学的联系非常紧密,偏向医学信息学领域相关的研究。
(6)C_6中的两种期刊与其他期刊不能聚成一类,故将这两种期刊分为其他类。
4.2 SSCI期刊层次体系结构
根据4.1节对期刊层次聚类结果中6个期刊分区的分析,可将26种LIS学科英文核心期刊划分成以下层次结构,如图3所示。
图3
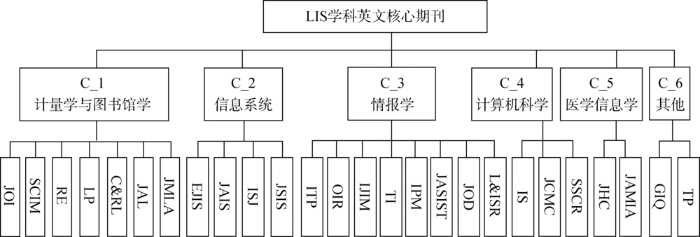
图3
基于题录信息的图书情报学学科英文期刊层次体系
Fig.3
Hierarchical System of LIS English Journals Based on Bibliographic Information
5 基于层次分类法的期刊论文自动分类
选取TIss、KWss、DEss、ABss字段表征单篇论文信息的内容。由于不同字段对论文的表征程度不同,因此不同组合对于分类的效果会产生不同程度的影响。一般认为,TIss字段最能展示论文的核心内容,因此被认为是表征能力最强的字段;KWss是作者挑选出来作为核心检索字段的一组词汇,也具有较强的反映文献内容的能力;DEss是对关键词的补充,和KWss所具有的表征内涵相似;ABss是对文章内容的高度概括,文章中出现的核心信息往往能在摘要中得到体现,但当摘要以句子的形式呈现时,会包含一些非核心词汇,一定程度上会削弱其对文献的表征能力[11]。在本文的实验中,选取以上字段进行不同的组合作为分类算法的输入。
实验分两层展开,首先进行第一层分类,即将每篇论文映射到6种期刊分区,然后对每一类中的期刊分别进行第二层分类,即将每篇论文映射到该区下对应的期刊中。
5.1 第一层分类实验
在第一层分类实验中,先后选取TIss、TIss+KWss、TIss+ABss、TIss+KWss+DEss、TIss+KWss+DEss+ABss等5种组合方式进行实验,分别使用SVM、CNN、RNN进行分类,对应每组实验的数据量如表4所示。
表4 不同特征组合实验数据量汇总
Table 4
| 特征组合 | 实验数据量 | 特征矩阵维度 |
|---|---|---|
| TIss | 6 000 | 6 456 |
| TIss+KWss | 5 840 | 8 328 |
| TIss+ABss | 5 891 | 14 661 |
| TIss+KWss+DEss | 5 242 | 8 451 |
| TIss+KWss+DEss+ABss | 5 242 | 14 625 |
(1) 整体准确率分析
在以上不同的特征组合和分类算法下进行实验后,统计每组实验的准确率,结果如图4所示。
图4

图4
不同特征组合下三种算法分类准确率
Fig.4
Accuracy Statistics Based on Three Algorithms Under Different Feature Combinations
①随着语料的增加,即在特征来源的组合变得逐渐复杂的趋势下,分类的准确率基本呈现上升趋势;
②特征来源仅为TIss时,SVM的准确率已经可达70.00%,说明TIss对于文献的表征能力十分显著;然而当语料较少时,CNN与RNN的分类效果不是特别理想,这与深度学习的大数据量需求一致;
③特征来源分别增加KWss和ABss后,SVM分类的准确率分别提升至76.00%和73.68%,说明这两种操作对于SVM分类的效果都呈积极影响,KWss的表征能力优于ABss;对比来看,当使用CNN与RNN分类时,ABss的表征能力优于KWss;
④当语料增加为TIss+KWss+DEss+ABss时,准确率下降为48.63%,究其原因:ABss中一些词的含义并不能十分准确地表征论文内容,有时甚至会干扰机器学习的判断能力,因此准确率急速下降。与SVM分类效果不同,特征来源的组合达到最复杂的TIss+KWss+DEss+ABss时,两种深度学习分类算法的效果都达到最优,CNN的分类准确率可以达到80%以上。
综上,在使用SVM进行分类时,最佳的语料组合方式为TIss+KWss+DEss;在使用深度学习算法进行分类时,最佳的语料组合方式为TIss+KWss+DEss+ABss。对比两种深度学习算法CNN和RNN的分类效果,在每组实验中CNN分类效果均优于RNN,认为前者在区分期刊术语语料的能力上更强,更适合此次实验语料的分类。因此,在以下实验和分析中,在深度学习算法部分仅采用CNN算法进行实验并对其结果进行分析。
(2) 分类F1值分析
针对特定算法选定最匹配的语料组合后,对第一层的6类期刊分区分别进行F1值统计,如图5所示。
图5
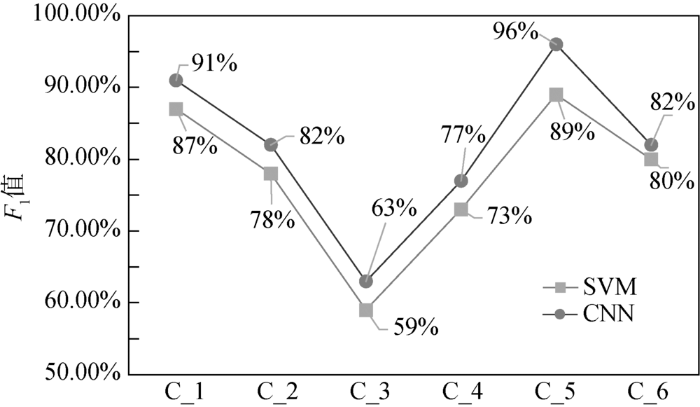
在每一类期刊分区中,CNN的F1值都要高于SVM,这和该层次的整体准确率对比的结果相一致。其中两种分类算法下都是C_3的F1值最低,分别为63%和59%,C_5的F1值最高,分别为96%和89%。对这两组极值数据分析后得到以下两个方面的影响因素。
①参加实验的文本数量的差异。统计C_3和C_5下参与实验的文本数量后发现,C_3的训练和测试文本数量相对较少,C_5的训练和测试文本数量相对较多。一般认为训练样本越充足,训练效果越好。且由于样本数量的不均匀问题,样本数量比例较高的类一般会收获较高的F1值。因此,足以证明文本数量对于分类效果的影响较为明显。
②两种期刊分区下收录期刊内容的差异。考察C_3下的期刊内容发现,其下共8种期刊,都为情报学相关研究,但是每种期刊的研究内容各有针对性。例如,IPM发表的大多是情报学领域偏向工程性的文章;OIR收录的文章偏向情报学与社会科学领域的交叉与应用;JOD的文章更多关注情报学传统的研究领域——文献学。若同一分区下的期刊各自研究方向存在差别,收集到的题录信息差异性大,则该类别的内聚性相对较低,与其他分区下的期刊内容混淆性较强,利用基于相似度计算的分类算法进行分类时效果相对较差。以同样的视角观察C_5,该分区是LIS学科下医学信息学领域,其下仅有两种期刊:JHC和JAMIA,这两种期刊从内容上主题十分明确。统计这两种期刊参与实验的数据中高频出现的10个词分别为:health、record、patient、electron、data、clinic、inform、medic、system、care。可以明显看出,这些单词能够轻易表征出医学信息学研究领域的主题信息,所以可以认为C_5下的两种期刊的内聚性很强,与其他期刊分区下的内容区分度较高。
综上,不同分类算法和特征来源的组合可以得到分类效果最佳的搭配。应用到具体的场景中,在进行论文投稿时,可以将论文先进行第一层次的大致划分,考虑可以将论文投至哪一分区,这样选择投稿的期刊范围可以进一步缩小,也更具针对性。
5.2 第二层分类实验
在进行第二层分类时,由于26种期刊中都包含的字段只有TIss和ABss,且第一层实验中验证了TIss+ABss的组合分类效果整体优于其他字段组合,因此选择TIss+ABss的组合进行实验。在算法选择上,由第一层分类实验得出SVM和CNN的准确率相对较高,因此仅使用这两种算法进行实验。每一个期刊分区中参与实验的数据量如表5所示。
表5 6种期刊分区参与实验数据汇总
Table 5
| 期刊 分区 | 期刊分区 下期刊数量 | 特征组合 | 实验 数据量 | 特征 矩阵维度 |
|---|---|---|---|---|
| C_1 | 7 | TIss+ABss | 5 570 | 11 615 |
| C_2 | 4 | TIss+ABss | 1 117 | 4 689 |
| C_3 | 8 | TIss+ABss | 4 738 | 11 013 |
| C_4 | 3 | TIss+ABss | 992 | 4 892 |
| C_5 | 2 | TIss+ABss | 2 858 | 8 404 |
| C_6 | 2 | TIss+ABss | 1 268 | 4 938 |
(1) 整体准确率分析
在选定TIss+ABss该特征组合后,分别使用SVM和CNN分类算法进行实验,统计每个期刊分区的准确率,如图6所示。
图6

图6
SVM和CNN算法下6类期刊分区准确率
Fig.6
Accuracy of Six Journal Partitions Based on SVM and CNN
①第二层分类实验的6组实验中,分类准确率明显下降,其中SVM在C_2的分类准确率仅有36.61%,CNN的准确率也仅有41.07%,在C_1、C_3、C_4类的分类效果也不理想,究其原因,相比于第一层分类实验中每次接近6 000条数据的数据量,第二层分类实验的数据量有限,直接导致算法学习得不够充分,从而间接导致准确率不高。
②在数据量一致的前提下,6种期刊分区的分类实验结果表明,CNN算法相比于SVM算法的优越性仍然明显。说明在期刊题录语料不能充分训练的小样本集上,深度学习仍具有机器学习算法未能超越的优势。
③获得较高准确率的两个期刊分区C_5和C_6除了拥有相对更丰富的语料这一特征外,这些类别下的期刊种类相比于其他类更少,都仅有两种期刊,这与分类算法在二分类上的分类效果优于多分类的特性相符合。
(2) 分类F1值分析
对第二层分类实验中6个期刊分区下属共计26种期刊分别使用SVM和CNN算法分类的F1值进行统计,如图7所示。
图7
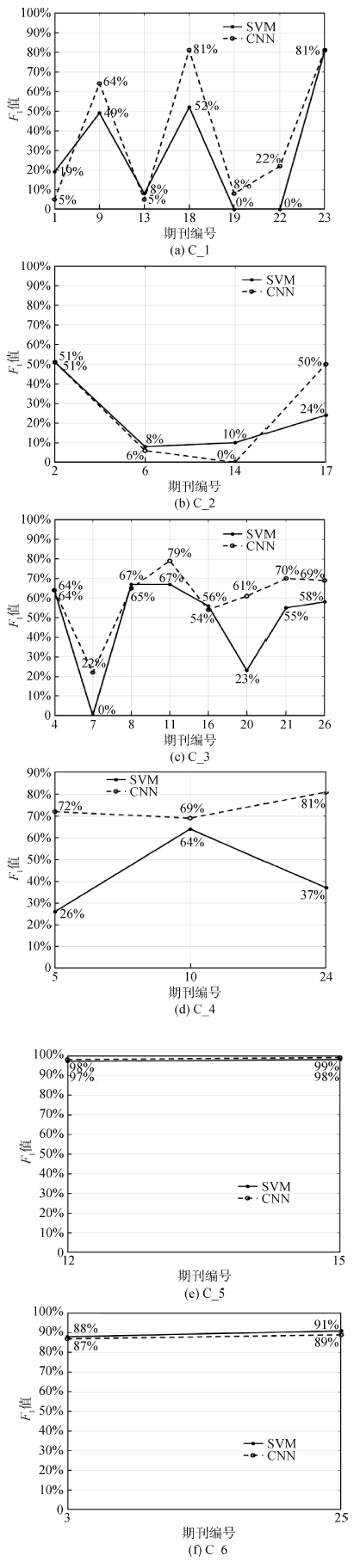
由于分类实验已经深入第二层,相比第一层期刊分区的分类实验结果,这一层的F1值明显下降。
①在不同的期刊分区中,下属的期刊数不同,则F1值也有相应差别。C_1和C_3分区下期刊较多,因此每一种期刊参加训练的数据量相对较少,可以很明显地观察到有些期刊的F1值较低。由于C_5和C_6分区下仅包含两种期刊,其F1值都达到85%以上。
②观察图7,SVM算法和CNN算法对比明显,在绝大多数情况下,CNN算法都比SVM算法更适合于此次实验的分类模型。
5.3 分类结果的优化
在得到第二层分类实验中直接对应到单个期刊的分类结果后,联系实际期刊投稿的应用场景:在进行投稿时,不单给投稿者某一个特定期刊的投稿意见,而是给出推荐准确率排名前几位的期刊,投稿投中的准确率往往会大幅提升。因此,对分类结果中错误分类期刊比例进行统计分析,将某一类期刊下最易混淆的某几种期刊进行组合,即将期刊收录内容相近的几种期刊同时视为可以投稿的对象后,观察分类准确率的提升效果。
仅以第二层分类实验中CNN分类结果下C_1的7种期刊为例,其他5个分区可参考其优化思路。调查这7种期刊的错分情况,如表6所示,已知CNN算法对该期刊分区的分类整体准确率为66.07%。
表6 C_1期刊分区错分情况统计
Table 6
| 序号 | 正确期刊 | 预测期刊 | 分类 错误数 | 分类错误数占 错误总量的比例 | 分类错误总计 |
|---|---|---|---|---|---|
| 1 | C&RL | JAL | 31 | 83.78% | 37 |
| C&RL | JOI | 0 | 0.00% | ||
| C&RL | JMLA | 2 | 5.41% | ||
| C&RL | LP | 0 | 0.00% | ||
| C&RL | RE | 2 | 5.41% | ||
| C&RL | SCIM | 2 | 5.41% | ||
| 2 | JAL | C&RL | 2 | 16.67% | 12 |
| JAL | JOI | 0 | 0.00% | ||
| JAL | JMLA | 3 | 25.00% | ||
| JAL | LP | 0 | 0.00% | ||
| JAL | RE | 0 | 0.00% | ||
| JAL | SCIM | 7 | 58.33% | ||
| 3 | JOI | C&RL | 0 | 0.00% | 70 |
| JOI | JAL | 0 | 0.00% | ||
| JOI | JMLA | 0 | 0.00% | ||
| JOI | LP | 0 | 0.00% | ||
| JOI | RE | 2 | 2.86% | ||
| JOI | SCIM | 68 | 97.14% | ||
| 4 | JMLA | C&RL | 0 | 0.00% | 5 |
| JMLA | JAL | 1 | 20.00% | ||
| JMLA | JOI | 0 | 0.00% | ||
| JMLA | LP | 0 | 0.00% | ||
| JMLA | RE | 2 | 40.00% | ||
| JMLA | SCIM | 2 | 40.00% | ||
| 5 | LP | C&RL | 0 | 0.00% | 23 |
| LP | JAL | 4 | 17.39% | ||
| LP | JOI | 0 | 0.00% | ||
| LP | JMLA | 1 | 4.35% | ||
| LP | RE | 5 | 21.74% | ||
| LP | SCIM | 13 | 56.52% | ||
| 6 | RE | C&RL | 0 | 0.00% | 29 |
| RE | JAL | 0 | 0.00% | ||
| RE | JOI | 0 | 0.00% | ||
| RE | JMLA | 2 | 6.90% | ||
| RE | RE | 0 | 0.00% | ||
| RE | SCIM | 27 | 93.10% | ||
| 7 | SCIM | C&RL | 0 | 0.00% | 13 |
| SCIM | JAL | 8 | 61.54% | ||
| SCIM | JOI | 2 | 15.38% | ||
| SCIM | JMLA | 0 | 0.00% | ||
| SCIM | LP | 0 | 0.00% | ||
| SCIM | RE | 3 | 23.08% |
以80%为阈值,将分类错误数占该类错误总数比例超过该阈值的类别进行组合。按照这一规则,进行如下实验,如表7所示。
表7 不同期刊组合实验优化方案
Table 7
| 实验名称 | 期刊组合方式 | 重新组合后C_1期刊分区所含期刊 |
|---|---|---|
| A | 期刊C&RL和JAL进行组合视为期刊A | A,JOI,JMLA,LP,RE,SCIM |
| B | 期刊JOI和SCIM进行组合视为期刊B | C&RL,JAL,B,JMLA,LP,RE |
| C | 期刊RE和SCIM进行组合视为期刊C | C&RL,JAL,JOI,JMLA,LP,C |
| D | 期刊JOI、RE和SCIM进行组合视为期刊D | C&RL,JAL,LP,JMLA,D |
| A+B | 期刊C&RL和JAL进行组合视为期刊A,期刊JOI和SCIM进行组合,视为期刊B | A,B,JMLA,LP,RE |
| A+C | 期刊C&RL和JAL进行组合视为期刊A,期刊RE和SCIM进行组合视为期刊C | A,JOI,JMLA,LP,C |
| A+D | 期刊C&RL和JAL进行组合视为期刊A,期刊JOI、RE和SCIM进行组合视为期刊D | A,D,JMLA,LP |
图8
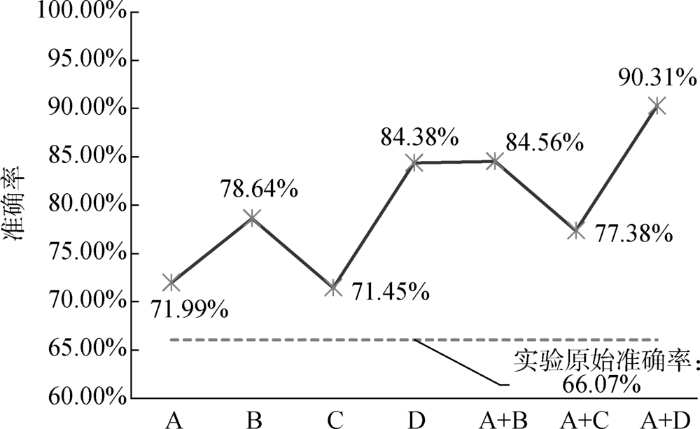
图8
不同期刊组合实验优化方案准确率对比
Fig.8
Comparison of the Accuracy of Different Journals Combination
图9
综上,针对每一期刊分区下的已有的分类体系,在保证准确率的前提下,可以将最易错分的特定期刊作为一个推荐组合,建议投稿人向多个期刊投稿。这样既能保证推荐结果的准确性,又能保证针对性。
6 结语
本文以LIS学科领域26种SSCI收录期刊为研究对象,进行面向期刊选择的学术论文分类研究。收集这26种期刊10年内收录文献的题录信息,选择其中一年的数据,使用层次聚类进行层次模型的构建。在此基础上,使用机器学习和深度学习的分类算法对10年的数据进行分类。结果表明,特征来源的多元化和数据规模的扩大可以增加语料的丰富程度,从而在一定程度上可以提高分类的准确性;在期刊分区数据量接近的情况下,期刊数目的增加对于分类的效果呈消极作用;在语料充足、数据量一致的条件下,深度学习算法体现出相比于机器学习算法的优越性,符合深度学习算法适用于较大数据运算量的特性;将内容相近的期刊进行组合后有利于分类准确性的提升。
本研究仍然存在以下不足之处:仅采用Web of Science数据库中26种英文期刊10年内的数据,在进行聚类时也仅使用了一年的数据进行实验,数据量的局限性可能会导致聚类、分类结果出现一定的偏差。关于上述不足,在后续的研究中需要对此进一步优化。例如,通过扩大时间跨度获取更多的题录信息进行实验。
作者贡献声明
王鑫芸:数据收集、实验论证和论文撰写;
王昊:提供研究思路,设计研究方案;
邓三鸿:提出论文修改意见;
张宝隆:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突。
支撑数据
支撑数据由作者自存储,E-mail:mg1914024@smail.nju.edu.cn。
[1] 王鑫芸.聚类数据.xlsx.层次聚类实验的所有题录数据.
[2] 王鑫芸.分类数据.xlsx.分类实验的所有题录数据.
[3] 王鑫芸.TFw文档-术语矩阵.xlsx.最终层次聚类图的TFw矩阵.
[4] 王鑫芸.TIss文档-术语矩阵.txt.第一层分类实验的TIss矩阵.
[5] 王鑫芸.TIss+KWss文档-术语矩阵.txt.第一层分类实验的TIss+KWss矩阵.
[6] 王鑫芸.TIss+ABss文档-术语矩阵.txt.第一层分类实验的TIss+ABss矩阵.
[7] 王鑫芸.TIss+KWss+DEss文档-术语矩阵.txt.第一层分类实验的TIss+KWss+DEss矩阵.
[8] 王鑫芸.TIss+KWss+DEss+ABss文档-术语矩阵.txt.第一层分类实验的TIss+KWss+DEss+ABss矩阵.
[9] 王鑫芸.第二层分类实验TIss+ABss数据.xlsx.第二层分类实验的数据.
参考文献
学术论文的数量特征与文本趋势
[J].
Quantitative Characters and Structural Change of Academic Papers
[J].
建立期刊投稿网络系统的探讨
[J].
Discussion on the Establishment of Periodical Contribution Network System
[J].
如何向国外专业期刊投稿
[J].
How to Contribute to Foreign Professional Journals
[J].
基于支持向量机的中文极短文本分类模型
[J].
Classification Model Based on Support Vector Machine for Chinese Extremely Short Text
[J].
二十年来西方保险理论的演变及其倾向
[J].
Evolution of Western Insurance Theories and Their Trends in the Past Two Decades
[J].
民国期刊分类服务体系探索与实践——以“全国报刊索引民国时期期刊全文数据库”为例
[J].
The Exploration and Practice of Classification Service System of Periodicals in the Republic of China: A Case Study of CNBKSY Database
[J].
高校社科类国际期刊分类评价研究
[J].
Study on the Classification and Evaluation of International Journals of Social Science in Universities
[J].
我国旅游学术期刊影响力和影响因子研究
[J].
Assessing the Influence and Impact of China’s Tourism Research Journals
[J].
文本挖掘在期刊评价中的应用研究
[J].
Research on the Application of Text Mining in Journal Evaluation
[J].
基于文本挖掘的期刊决策参考研究
[D].
Research on Journal Decision-Making Reference Based on Text Mining
[D].
基于半监督支持向量机的期刊收稿系统自动分类方法
[J].
An Automatic Classification Method Based on Semi-Supervised Support Vector Machine for Periodical Manuscript Acceptance System
[J].
网格聚类算法在用电营销中的应用
[D].
Application of Grid Clustering Algorithm in Electric Power Marketing
[D].
CLIQUE网格聚类算法在医学空间数据中的应用
[D].
Grid Clustering Algorithm of CLIQUE in the Medical Application of Spatial Data
[D].
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise
[C]
DBSCAN算法在公路选线中的应用
[J].
DBSCAN Spatial Clustering Algorithm and Its Application in Highway Alignment Selection
[J].
基于模型的聚类方法研究
[J].
Study on Model-based Clustering Methods
[J].
CURE: An Efficient Clustering Algorithm for Large Databases
[J].
ROCK: A Robust Clustering Algorithm for Categorical Attributes
[J].DOI:10.1016/S0306-4379(00)00022-3 URL [本文引用: 1]
Chameleon: Hierarchical Clustering Using Dynamic Modeling
[J].
聚类算法研究
[J].
Clustering Algorithms Research
[J].
层次聚类分析法在连州市土地利用分区中的应用
[J].
Application of Hierarchical Clustering Analysis Method to Land Use Regionalization in Lianzhou
[J].
层次聚类分析法在土地利用分区中的应用——以益阳市南县为例
[J].
Application of Hierarchical Cluster on Land Utilization Division——Take Nan County in Yiyang for Example
[J].
Some Methods for Classification and Analysis of Multivariate Observations
[C]
Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values
[J].
K-modes Clustering
[J].DOI:10.1007/s00357-001-0004-3 URL [本文引用: 1]
K-nearest-neighbor Consistency in Data Clustering: Incorporating Local Information into Global Optimization
[C]
K-means聚类算法在入侵检测中的应用
[J].
提出了一种基于聚类分析方法构建入侵检测库的模型,实现了按K-平均值方法建立入侵检测库并据此划分安全等级的思想。该检测系统的建立不依赖于经验数据,能自动依据原有数据对入侵行为进行重新划分。仿真实验表明,该方法具有较强的实用性和自适应功能。
Application of K-means Clustering Algorithm in Intrusion Detection
[J].
提出了一种基于聚类分析方法构建入侵检测库的模型,实现了按K-平均值方法建立入侵检测库并据此划分安全等级的思想。该检测系统的建立不依赖于经验数据,能自动依据原有数据对入侵行为进行重新划分。仿真实验表明,该方法具有较强的实用性和自适应功能。
K-means算法在客户细分中的应用研究
[D].
Application of K-means in Customer Segmentation
[D].
基于支持向量机的医学期刊文章自动分类研究
[J].
Research on Automatic Classification of Medical Journal Articles Based on SVM
[J].
基于SVM的文本词句情感分析
[J].
Emotion Analysis on Text Words and Sentences Based on SVM
[J].
基于GloVe与SVM的文本分类研究
[J].
Research on Text Classification Based on GloVe and SVM
[J].
基于改进CNN的海军军事文本分类模型
[J].
Navy Text Classification Model Based on Improved CNN
[J].
关于统计学习理论与支持向量机
[J].
Introduction to Statistical Learning Theory and Support Vector Machines
[J].
Gradient-based Learning Applied to Document Recognition
[J].
A Recurrent Neural Network: Limitations and Training
[J].DOI:10.1016/0893-6080(90)90054-O URL [本文引用: 2]
基于深度学习的文本分类系统关键技术研究与模型验证
[J].
Key Technology Research and Model Validation of Text Classification System Based on Deep Learning
[J].
文献题录信息挖掘技术方法及其软件SATI的实现——以中外图书情报学为例
[J].利用C#编程技术基于.NET平台设计开发出文献题录信息统计分析工具软件SATI,可导入处理EndNote格式、NoteExpress格式及NoteFirst格式的国内文献题录数据和HTML格式的WoS国际文献题录数据,进行数据格式的转换、字段信息的抽取、词条频次的统计和知识单元共现矩阵、词条频率逐年分布矩阵及文档词条矩阵的构建,以辅助生成聚类图、多维尺度图谱、网络知识图谱、策略坐标图等可视化结果。以2006~2010年中外图书情报学各十种具有代表性的核心期刊刊载的17440篇论文数据为实例,基于聚类与多维尺度分析结果,呈现出中外图书情报学三大主要研究领域,并结合共词分析与社会网络分析方法,通过绘制共现网络知识图谱与策略坐标图,进一步揭示研究领域结构的内部联系及其特征。
A Study on Mining Bibliographic Records by Designed Software SATI:Case Study on Library and Information Science
[J].利用C#编程技术基于.NET平台设计开发出文献题录信息统计分析工具软件SATI,可导入处理EndNote格式、NoteExpress格式及NoteFirst格式的国内文献题录数据和HTML格式的WoS国际文献题录数据,进行数据格式的转换、字段信息的抽取、词条频次的统计和知识单元共现矩阵、词条频率逐年分布矩阵及文档词条矩阵的构建,以辅助生成聚类图、多维尺度图谱、网络知识图谱、策略坐标图等可视化结果。以2006~2010年中外图书情报学各十种具有代表性的核心期刊刊载的17440篇论文数据为实例,基于聚类与多维尺度分析结果,呈现出中外图书情报学三大主要研究领域,并结合共词分析与社会网络分析方法,通过绘制共现网络知识图谱与策略坐标图,进一步揭示研究领域结构的内部联系及其特征。
文本聚类综述
[J].
An Overview of Text Clustering
[J].
基于语义的文档特征提取研究方法
[J].
Semantic-based Feature Extraction Method for Document
[J].
自动文本分类特征选择方法研究
[J].
Automatic Text Categorization Feature Selection Methods Research
[J].
基于文档频率的特征选择方法
[J].在构建空间矢量全球四叉树数据库时,四叉树矢量结点的生成可能涉及海量矢量数据的读取。针对上述情况,提出基于多路归并的建库方法,以外排序的方法解决内存限制问题,采用矢量层分割自然形成的结点顺串以及内存文件映射技术存取结点顺串,使矢量建库的效率得到保证。实验结果证明该建库方法效率高。
Feature Selection Method Based on Document Frequency
[J].在构建空间矢量全球四叉树数据库时,四叉树矢量结点的生成可能涉及海量矢量数据的读取。针对上述情况,提出基于多路归并的建库方法,以外排序的方法解决内存限制问题,采用矢量层分割自然形成的结点顺串以及内存文件映射技术存取结点顺串,使矢量建库的效率得到保证。实验结果证明该建库方法效率高。
基于互信息最大化的特征选择算法及应用
[J].该文以互信息最大化原则为指导,经过推导和分析后提出了一种基于信息论模型的新的特征选择算法,称之为基于互信息最大化的特征选择算法(MaxMI)。基本思想就是特征选择后,应当尽可能多地保留关于类别的信息。该算法与传统的信息增益、互信息和交叉熵在表达形式上具有一定的相似性,但是并不完全相同。从实验上验证了基于互信息最大化的特征选择算法优于其它三种算法。
Mutual Information Maximization Based Feature Selection Algorithm in Text Classification
[J].该文以互信息最大化原则为指导,经过推导和分析后提出了一种基于信息论模型的新的特征选择算法,称之为基于互信息最大化的特征选择算法(MaxMI)。基本思想就是特征选择后,应当尽可能多地保留关于类别的信息。该算法与传统的信息增益、互信息和交叉熵在表达形式上具有一定的相似性,但是并不完全相同。从实验上验证了基于互信息最大化的特征选择算法优于其它三种算法。
基于互信息的遥感图像区域配准并行算法的研究与实现
[J].图像配准是图像融合、变化检测、目标识别等遥感应用中的重要步骤.互信息由于具有无需预处理、自动化程度高以及鲁棒性强等特点,将其作为一种相似性测度进行图像配准成为近几年图像处理领域的研究热点.随着遥感图像数据量的不断加大,传统的单机处理模式已经无法满足一些应用的时效性要求.基于对串行算法计算瓶颈的实验分析,研究并提出了一种基于互信息的遥感图像区域配准并行算法,分别给出了数据划分策略和互信息计算并行处理方案,采用边界冗余划分和二叉树归约方法减少数据通信,并对算法进行了定量的复杂度分析.实验结果表明该算法可扩展性好,通用性强.
Study and Implement of Parallel Region-based Registration Algorithm Based on Mutual Information for Remote-sensing Images
[J].图像配准是图像融合、变化检测、目标识别等遥感应用中的重要步骤.互信息由于具有无需预处理、自动化程度高以及鲁棒性强等特点,将其作为一种相似性测度进行图像配准成为近几年图像处理领域的研究热点.随着遥感图像数据量的不断加大,传统的单机处理模式已经无法满足一些应用的时效性要求.基于对串行算法计算瓶颈的实验分析,研究并提出了一种基于互信息的遥感图像区域配准并行算法,分别给出了数据划分策略和互信息计算并行处理方案,采用边界冗余划分和二叉树归约方法减少数据通信,并对算法进行了定量的复杂度分析.实验结果表明该算法可扩展性好,通用性强.
文本分类中信息增益特征选择方法的研究
[J].分析了传统信息增益(IG)特征选择方法忽略了特征项在类间、类内分布信息的缺点,引入类内分散度、类间集中度等因素,区分与类强相关的特征;针对传统信息增益(IG)特征选择方法没有很好组合正相关特征和负相关特征的问题,引入比例因子来平衡特征出现和不出现时的信息量,降低在不平衡语料集上负相关特征的比例,提高分类效果。通过实验证明了改进的信息增益特征选择方法的有效性和可行性。
Study on Information Gain-based Feature Selection in Chinese Text Categorization
[J].分析了传统信息增益(IG)特征选择方法忽略了特征项在类间、类内分布信息的缺点,引入类内分散度、类间集中度等因素,区分与类强相关的特征;针对传统信息增益(IG)特征选择方法没有很好组合正相关特征和负相关特征的问题,引入比例因子来平衡特征出现和不出现时的信息量,降低在不平衡语料集上负相关特征的比例,提高分类效果。通过实验证明了改进的信息增益特征选择方法的有效性和可行性。
Supervised Semantic Classification for Nuclear Proliferation Monitoring
[C]
An Improved Hoeffding-ID Data-stream Classification Algorithm
[J].
An Enhance Excavation Equipments Classification Algorithm Based on Acoustic Spectrum Dynamic Feature
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}