




1 引言
随着移动互联网和社交网络的蓬勃发展,用户投诉、在线评论等在线文本信息越来越多,用户和企业可以对这些信息进行有效挖掘,及时发现数据中潜在的商业价值和用户的需求。如何对这些数据进行有效挖掘,对于广大企业而言显得尤为重要。
文本分类作为自然语言处理中的基础任务之一,在垃圾邮件过滤、情感分析、问答系统、信息检索等领域起着极其重要的作用。目前,文本分类任务中流行的方法主要有两类:基于传统机器学习的方法和基于深度学习的方法。
另一种高效的文本分类方法是基于深度学习的方法。传统机器学习方法很大程度上依赖于人工特征构建,这将消耗大量的人力和时间成本,人为因素干扰会造成特征噪声。深度学习方法有效地解决了这些问题,被广泛用于自然语言处理中。在深度学习文本分类任务中,很多学者在特征获取阶段采用词嵌入(Word Embedding)技术避免人工设计特征,有效捕捉词汇隐藏的语义和语法特征。现阶段词嵌入技术已经和深度学习紧密结合,这为文本分类的研究提供了新的思路。
而在文本分类中,中文文本存在特征稀疏、上下文依赖性强等特点,在进行处理的过程中总会丢失较多的语义特征,特征获取不够全面。同时,在中文文本中还存在由于拼写错误、同音词等对分类效果所造成的影响,如何有效地获取特征、提高模型的准确率,是中文文本分类研究所面临的一个挑战。为了解决中文文本分类中存在的这些问题,本文提出一种多特征融合的文本分类模型。在词向量的基础上结合拼音字符特征,缓解拼写错误所带来的影响,并加入词性标记和汉字字符特征作为特征补充以丰富语义信息,以便深度学习模型获取更全面的语义信息。
2 相关工作
随着深度学习的不断发展,与传统的自然语言处理方法相比,深度学习算法在自然语言处理任务中取得了不错的效果。在文本分类任务中,最受欢迎的深度学习方法主要包括:卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)。
卷积神经网络(CNN)是一个典型的空间上的深度神经网络,具有优异的特征自抽取能力,能够显著降低文本分类中人工抽取特征的难度。很多学者在CNN的基础上进行了改进,并且可以达到预期的令人满意的性能。Kim[3]利用不同的滤波器获取不同层面的语义信息,并利用多个卷积层获取深层的语义信息,与单层的卷积相比,模型效果得到显著提升。Kalchbrenner等[4]提出一种动态卷积神经网络(Dynamic Convolutional Neural Network,DCNN)模型,采用动态(k-Max)池化获取句子语义特征,模型在问题和情感分类方面取得了不错的效果。Johnson等[5]提出一种词级别的深层卷积神经网络模型(Deep Pyramid Convolutional Neural Networks,DPCNN),能够在有效获取多层次语义特征的基础上,有效获取文本中的长期依赖信息。
循环神经网络(RNN)可以有效地学习近距离的语义特征,但存在梯度消失或梯度弥散问题。因此,RNN出现多个变种循环神经网络模型,如长短时记忆网络(Long Short-Term Memory,LSTM)。在问题分类任务中,LSTM[6]有效解决了RNN梯度回传过程中面临的消失和爆炸的问题,进一步优化了深度模型。虽然LSTM可以提取长距离的上下文语义特征,但结构复杂,时间代价大。针对CNN和LSTM自身存在的不足,王海涛等[7]将多层的CNN与LSTM相结合进行优势互补。门控循环单元(Gated Recurrent Unit,GRU)网络结构相对LSTM而言更简单[8],能有效地提高模型训练时间。双向门限循环单元(BiGRU)[9]通过双向GRU充分地利用上下文信息,记忆当前单词并实时更新这个时刻之前的所有单词的信息,基于序列从而更好地预测。为了提升模型的性能,郑诚等[10]将CNN与BiGRU相结合进行特征获取,有效缓解了特征丢失的问题。
在文本分类任务中,很多学者将深度学习与词嵌入技术相结合。词嵌入方法中最流行的方法是Word2Vec[11,12]。Word2Vec是一种基于预测的词向量模型,有CBOW(Continuous Bag-of-Word)和Skip-Gram两种训练模式。依据文本粒度粗细的划分,词嵌入分为词语级别嵌入和字符级嵌入两种。在此基础上,很多学者结合深度学习对文本特征从词级别和字符级别进行了深度拓展。对于词级别特征扩展,为了提高文本分类的准确率,文献[3,4]通过词级别特征与深度学习模型相结合获取文本的抽象语义特征,准确率得到大幅度提升。陈钊等[13]结合卷积神经网络和传统词语情感序列特征,通过对文本中词语进行抽象表示获得了更高的分类准确率。王海涛等[7]使用词嵌入技术将文本进行向量表示,并输入改进的MLCNN(Merge-LSTM-CNN)中,准确率得到大幅度提升。在字符特征研究中,刘敬学等[14]提出一种字符特征的CNN和LSTM相结合的模型进行短文本分类,使用字符嵌入保留原始文本信息,但是对于词语间的理解仍有所欠佳。为了丰富语义信息,杨路辉等[15]在词级别特征的基础上结合字符特征进行特征扩展,同时提取浅层和深层字符级特征并融合,模型的效果提升显著。聂维民等[16]在字粒度的基础上结合词粒度和主题粒度,不断提高文本的特征表示能力,但涉及的词序关系范围小。刘龙飞等[17]则利用字特征挖掘微博文本特征,与词级别原始输入特征相比,模型准确率更高。为了缓解中文文本中的拼写错误及其同音词所造成的语义理解偏差,余本功等[18]提出一种结合拼音字符和词的双输入卷积神经网络模型CP-CNN,并在采样层使用k-Max动态采样,增强模型特征的表达能力。
在文本分类任务中,鉴于每个词都具有不同的词性,在词性中也包含着一些重要的语义信息。为了学习语篇中更深层次的抽象特征,有学者通过词性标注区分词在句子结构或语义中的不同角色[19,20,21],有助于模型提取相应的特征。也有学者在分类的过程中,探究了不同词性(名词、副词、形容词、情态动词、形容词等)标签的影响,只保留对分类过程重要的语义特征,有效地消除了文本歧义,提高了文本的分类性能[22,23,24,25]。为了提高区分术语的能力,文献[26,27]通过整合搭配作为术语特征,对形容词、名词、动词等特定类型词类的确定,提取出搭配词,降低了特征向量维数,提高了文档的表达能力。在词性研究中,Cheng等[28]通过嵌入将词性部分映射为向量表示,然后直接将其输入带有词向量的模型中进行训练,在不同的语言中通过添加词性特征[29,30,31,32],分析更深层的语义信息,实验结果表明,词性特征嵌入使所有分类器的分类准确率得到提高。为了更好地探索词语的句法信息,Huang等[33]发现在神经网络中进行词性标记编码可以增强句子/短语的表示。Shiguihara-Juárez等[34]考虑到文本中词法、语法和依赖特性的特征关系,利用词性标签特性中的信息,并与单词相结合,有效提取句子中的特征。有学者在输入层中构建词级别和词性特征双通道[8],以及字符级别、词级别和词向量融合词性特征的三通道[35],有效学习到句子内部的抽象语义信息。
鉴于深度学习领域CNN和BiGRU在文本分类任务中的显著效果,同时考虑到在分类文本中,不同的词性所代表的重要性不同,而Word2Vec词向量忽略了词性信息,同时为了弥补特征获取不充分的问题,本文提出了基于多种特征融合的文本分类模型。多种特征融合的文本分类模型,结合Word2Vec获取词级别的原始语义信息,在此基础上结合拼音字符特征、汉字字符特征和词性特征进行特征补充,使模型更充分地保留语义特征,在减少特征丢失的同时,提高模型的语义表征能力。同时,模型融合了BiGRU和CNN,在有效获取文本上下文特征的同时,结合CNN获取局部特征,去除冗余特征,有效获取抽象的高级语义信息。通过多种优化,不断丰富模型语义特征,以实现特征信息更加完整,进而提升模型分类性能。本文方法通用性较强,无需人工提取特征,极大地减少了参数量,节约了大量的人力和时间成本,满足了文本自动分类的需求。
3 基于多特征融合的文本分类模型
本文提出的多种特征融合文本分类模型,从多种语义层面进行语义理解,进一步提高文本的表征能力,进而提高文本分类的准确率。对于多特征融合的文本分类模型,首先需要对预处理后的待分类文本数据进行语义特征建模,包括词级特征表示、词性POS(Part-Of-Speech)特征表示、汉字字符特征表示和拼音字符级特征表示,构建4种不同的输入表示;然后将处理好的特征表示分别输入BiGRU进行上下文语义特征获取;接着将获取的上下文语义特征输入多种滤波器的卷积神经网络中进行局部特征获取,增强模型的特征学习能力;最后将多种不同的语义特征融合,丰富特征信息,并输入Softmax层中进行分类,预测得到所需要的类别标签。多特征融合的文本分类模型结构如图1所示。整个模型主要由语义特征表示、上下文特征获取、局部特征获取、多特征融合和Softmax分类5部分组成。
图1
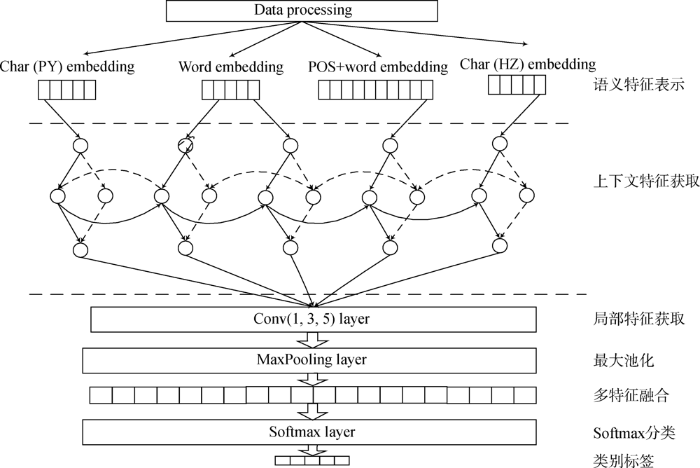
图1
多特征融合文本分类模型结构
Fig.1
Structure of Text Classification Model Based on Multi-Feature Fusion
3.1 语义特征表示
语义特征表示阶段主要是将待分类的文本映射成4种不同的特征表示,分别为词级特征表示、POS词性特征表示、汉字字符特征表示和拼音字符级特征表示,构建4种不同的特征作为多特征融合模型的特征输入。在输入特征构建中,首先需要对文本进行词向量训练、词性特征训练、拼音字符特征训练和汉字字符特征训练。将词向量特征表示作为原始语义特征,构建词级别特征;将词向量与POS词性特征进行拼接,构建POS词性特征扩展;将汉字字符特征作为特征输入,构建汉字字符特征表示;将拼音字符特征作为输入特征,构建拼音字符特征扩展。将4种不同的语义特征进行融合,可以为原始语义特征提供额外的信息,获取更为深层的语义信息,加深语义间的理解。
(1) 词级别特征表示
图2
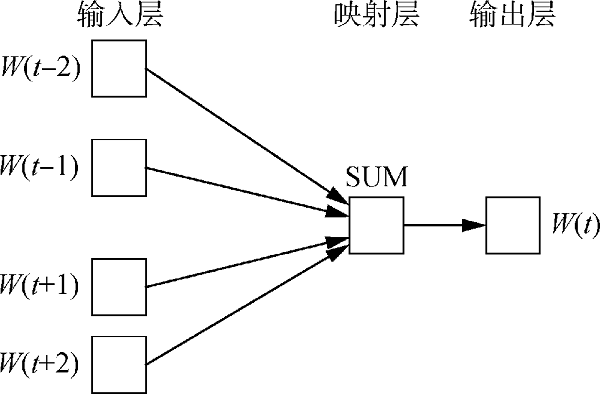
在训练过程中,CBOW模型将该词上下文的n个词进行编码后,利用滑动窗口进行权重计算,最终获取当前词的向量表示。模型在词向量表示时,考虑到词的上下文信息,所以最终的词向量表示了一定的语义信息。在文本词向量训练中,将每个词表示固定为100维度的向量
(2) 词性标记
词性作为词语基本的语法属性,是词语和语句的关键性特征,为了获取更深层的语义特征,加深语义理解,本文结合词性特征进行特征获取。对于待分类文本,将其分词后进行相应的词性标记。将切分后的每个词赋予其对应的词性,包括名词、时间词、处所词、方位词、动词、形容词等类别,作为后面语义分析的基础工作。本文使用的词性标注标准为中国科学院计算技术研究所标注集。为了便于计算,将词性标记的特征向量维度固定为50维,词性标记后,进行One-Hot编码获得词性特征
(3) 汉字字符特征获取
在中文分词的过程中,不同的分词工具分词也不尽相同,分词的不同造成的语义也就会存在不同,为了减少不同的分词对语义理解所造成的理解偏差,将汉字字符特征作为一个特征输入辅助原始语义特征,以学习更为深层的语义特征。在训练的过程中,将汉字字符特征的维度设定为100维。将待分类的文本进行汉字字符分割后,然后用Word2Vec对每个汉字进行编码向量化,如公式(5)和公式(6)所示,其中
(4) 拼音字符特征获取
为了获取深层语义特征,结合拼音自身特点,通过构建拼音字符特征进行语义特征扩展。在中文里,字符级别特征表示即拼音表示序列。文本中单个字的拼音表示,是以拼音为基本组成单位训练词向量。在数据预处理阶段,原始中文文本按字符划分为单个汉字与符号,依照所建字典顺序映射为字嵌入原始矩阵。引入中文的拼音序列对原始文本进行语义拓展,通过汉语拼音进行中文文本的转换,拼音表示的文本再按字符嵌入。例如,“[笔记本电脑散热底垫]”拼音可表示为“[bijibendiannao sanredidian]”。按照字母表的顺序,一一对应相应的文本,使用大规模语料训练得到的单词嵌入向量集合,记为
通过构建拼音字符特征,进一步在字符层面拓展文本特征,同时可以降低同音字、多音字和错别字等异常字符对分类结果的影响。拼音表示相较于字嵌入,在错别字和多音字的处理上可适当纠错。例如,“一代水果”中错别字“代”拼音表示为“dai”,多音字“还”字拼音表示为“hai”或“huan”。字嵌入相较于拼音表示,在同音字的处理上存在优势。例如,“一部”的拼音“yibu”和“不错”的拼音“bucuo”,“bu”为音同字不同,语义上可以区分。
3.2 上下文特征获取
在自然语言中,语义特征的一个显著特点是连续性,词语的出现顺序往往影响句子的意义。为了对词序进行建模,同时考虑到文本中正向和反向语序的影响,基于以上两点,本文采用BiGRU模型提取文本的上下文语义信息。
GRU传统的循环神经网络中加入细胞态,同时加入门保护细胞态的信息更新,有效地解决了长距离依赖问题,与LSTM相比,它将隐层状态和细胞状态合并,减少了门的数量,同时减少了冗余信息和参数,模型的计算效率得到有效提高。GRU主要包括更新门和控制门,通过门进行信息选择和控制,并对选择后的信息进行更新。门元素的值在[0,1],当值为1时表示信息完全通过,当值为0时表示信息完全阻塞。GRU结构信息如图3所示。
图3
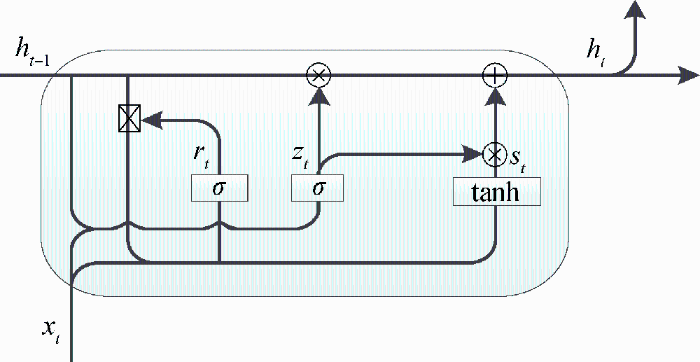
其中,
在GRU对文本序列建模时,每个位置的隐藏状态只能对前面上下文进行正向编码,而不考虑反向上下文。双向GRU利用了两个并行通道,一个GRU从句首到句末进行文本语义建模,另一个GRU从句末向句首进行文本表示,然后将两个GRU的隐藏状态进行连接作为每个位置的表示。通过这种方式,当前时刻的输出就不仅仅与之前的状态有关,还与未来的状态有关,这样前后上下文可以同时考虑。双向计算的过程如公式(10)-公式(12)所示。
其中,
3.3 局部特征获取
(1) 卷积层
为了获取关键语义特征,避免特征冗余,在上下文语义特征获取后加入卷积层来捕获局部语义特征,结合多种卷积核获取不同层级的信息。卷积本质上是对输入信号的加权叠加,将卷积核
其中,
对于某个卷积核,它对应一个卷积模板,能够提取一类特征。通常情况下,不同文本内容其上下文信息并不相同,因此,采用不同的卷积核大小提取不同粒度的局部特征,卷积核的大小分别取为{1,3,5}。经过三种不同的滤波器操作后,将得到三种不同的特征输出
(2) 最大池化层
卷积层之后是池化操作,池化层也叫作降采样层,通过池化操作不仅可以降低文本特征的维度,保留主要特征,还可以防止过拟合现象的发生。常见的池化操作有两种:最大池化和平均池化操作,模型采用最大池化操作生成固定维度的特征向量,供分类器进行分类,将卷积后得到的C值进行最大池化,如公式(15)所示。然后将不同特征图池化后的值进行融合操作,如公式(16)所示。接着将不同大小滤波器的结果进行融合获取一个通道的输出特征
3.4 多特征融合
在最大池化操作之后,需要将获得的4种不同的语义特征进行融合,获取最终的语义特征表示。需要将向量进行连接,形成固定长度的融合特征向量,即将原始文本的语义向量表示、词性语义特征扩展、拼音字符特征扩展和汉字字符特征进行拼接,拼接后得到最终语义特征
3.5 Softmax分类
Softmax分类层主要是对上一层的输出向量进行归一化。将获取的最终语义向量表示
其中,
其中,
4 实验与分析
4.1 实验数据准备
(1) 实验环境
本文实验环境描述如表1所示。
表1 实验环境配置参数
Table 1
| 环境 | 配置参数 |
|---|---|
| 处理器 | Intel(R) Core(TM) I5-4200U CPU @1.6GHz |
| 显卡 | NVIDIA GeForce GT 740M |
| 内存 | 12GB |
| 编译器、语言 | PyCharm,Python3.7 |
(2) 数据准备
本文实验使用两个数据集,数据集信息如表2所示。一个为计算机专利数据,在SooPAR专利上选择中国专利“计算机”主题,文本主分类号为G06F1/16、G06F1/18、G06F1/20、G06F3/02、G06F3/14,选择近4年的专利数据,每个类别选择2 000篇进行下载。对下载后的专利数据进行筛选去重,保留专利摘要文本和主分类号并分类存储。另一个数据集为搜狗新闻语料库开源的数据集[37],包含搜狐新闻2012年6月至7月期间18个频道的新闻数据,选择有代表性的5类数据,分别为汽车(2 000条)、财经(2 000条)、科技(2 000条)、体育(2 000条)、其他(2 000条)。获取的数据都相对平衡,避免了数据的不平衡对实验所造成的影响。
表2 数据集信息
Table 2
| 数据项 | 计算机专利 | 搜狗新闻 |
|---|---|---|
| 来源 | SooPAR专利 | 搜狗实验室开源 |
| 类别数 | 5 | 5 |
| 数量 | 10 000 | 10 000 |
| 平均长度(字符) | 210 | 843 |
| 最短长度(字符) | 150 | 30 |
| 最长长度(字符) | 300 | 400 |
对待分类文本进行数据清洗,除去因网络来源产生的噪声,删除停止词。文档中的大多数词都不是很重要,如助动词、冠词和连词,都可以从文本中删除。然后利用Jieba工具对文本进行拼音表示,将汉字转换为拼音,然后对拼音进行切分,利用Word2Vec训练拼音字符向量。并利用Jieba工具对文本进行词性标记,采用中国科学院计算技术研究所的标注标准,对标记好的文本进行One-Hot编码。同时,将中文文本进行汉字字符切分,用Word2Vec进行汉字字符特征训练。同时,将待分类的文本进行分词后直接用Word2Vec进行训练得到词向量。
Word2Vec训练需要较大的语料数据,因此,本文实验在训练Word2Vec时,将抓取的文本和维基百科中文文本组合在一起,使用CBOW模型完成向量训练。对于数据集的划分,所使用的数据集都已全部划分为训练集和数据集,在训练数据时,将数据随机抽取80%作为训练集,20%作为测试集。
4.2 实验设置与评价指标
(1) 实验设置
参数设置如表3所示。对于模型参数设置,为了使模型达到最好的效果,同时考虑到训练的时间成本,将BiGRU模型的单元数设置为100个,卷积核个数为64个,卷积核的大小为三种,即{1,3,5},训练时的批参数为20,每次迭代32个数据,同时,采用Adam对模型进行优化,降采样的学习率设置为0.25。
表3 模型参数设置
Table 3
| 参数 | 设定值 |
|---|---|
| 卷积核宽度 | {1,3,5} |
| 卷积核个数 | 64 |
| GRU单元数 | 100 |
| Batch Size | 32 |
| Epoch | 20 |
| Optimizer | Adam |
| Dropout Rate | 0.25 |
(2) 评价指标
实验采用分类模型常用的查准率P(Precision)、查全率R(Recall)、二者综合评价F1值和准确率Acc(Accuracy)作为模型的评价指标,如公式(21)-公式(24)所示。
其中,TP表示预测为c类,实际为c类;FP表示预测为c类,实际为非c类;TN表示预测为非c类,实际为非c类;FN表示预测为非c类,实际为c类;c取1,2,3,…。c根据实际类别数来赋值。
4.3 实验结果与分析
(1) 多特征融合对模型分类效果的影响
在对比实验中,为了验证多特征融合的实验效果,本文设计了词性BiGRUCNN、拼音字符BiGRUCNN、汉字字符BiGRUCNN、词向量BiGRUCNN、词性与词向量融合BiGRUCNN、汉字字符与词向量融合BiGRUCNN、字符拼音与词向量融合BiGRUCNN等多种模型与本文模型进行对比。在模型的训练过程中,分别将实验训练5次并求模型的准确率、P值、R值和F1值的平均值。因为本文数据为平衡数据,实验的效果以准确率作为主要的评价指标,其他指标作为辅助。
多特征融合对比实验结果如表4和表5所示。在两种不同的数据集中,通过词性与词向量的模型对比可以看出,结合词向量准确率分别为76.1%和83.6%,结合词性模型准确率只有57.3%和64.9%,结合词性与词向量的模型,准确率达到78.1%和85.1%,同时双通道与结合词性的三通道对比,模型分类效果有不同程度提升,实验证明了模型结合词性的有效性。这说明,结合词性的模型可以在一定程度上提高模型的语义表达能力。通过词向量与拼音字符向量的模型进行对比,可以看出,在两种数据中拼音字符特征准确率只有64.1%和72.3%,当拼音字符特征与词向量相结合模型准确率分别达到79.1%和86.0%,模型的分类效果在不同的数据中都有很大的提升。这说明,结合拼音字符后,模型可以从多种不同语义结构对语义进行理解,提高了模型的理解能力,对于模型的分类性能也有很好的提升。利用拼音来获取字符特征可以降低文本的歧义程度,增强文本的分类性能。通过词向量与汉字字符向量的模型进行对比,结合汉字的模型准确率只有65.2%和75.2%,结合词向量和汉字字符特征模型准确率达到80.2%和87.2%,与单通道词向量模型相比准确率均有所提升。这说明,字符特征可以在一定程度上加强语义表征能力。
表4 多特征融合模型对比(计算机专利)
Table 4
| 数据集 | 模型 | Acc | P | R | F1 |
|---|---|---|---|---|---|
| 计算机专利 | POS-BiGRUCNN | 57.3% | 59.4% | 58.1% | 60.0% |
| PY-BiGRUCNN | 64.1% | 65.3% | 63.5% | 64.1% | |
| HZ-BiGRUCNN | 65.2% | 62.7% | 62.6% | 62.2% | |
| Word-BiGRUCNN | 76.1% | 76.9% | 76.2% | 76.5% | |
| POS-Word-BiGRUCNN | 78.1% | 77.5% | 77.1% | 77.3% | |
| PY-Word-BiGRUCNN | 79.1% | 78.8% | 78.5% | 77.5% | |
| HZ-Word-BiGRUCNN | 80.2% | 79.5% | 79.3% | 79.5% | |
| PY-POS-Word-BiGRUCNN | 81.3% | 80.3% | 78.6% | 79.4% | |
| HZ-POS-Word-BiGRUCNN | 81.2% | 81.3% | 80.5% | 80.9% | |
| PY-HZ-Word-BiGRUCNN | 82.2% | 82.3% | 81.9% | 80.9% | |
| PY-POS-HZ-Word-BiGRUCNN(本文) | 83.3% | 83.6% | 82.9% | 83.4% |
表5 多特征融合模型对比(搜狐新闻)
Table 5
| 数据集 | 模型 | Acc | P | R | F1 |
|---|---|---|---|---|---|
| 搜狐新闻 | POS-BiGRUCNN | 64.9% | 61.3% | 62.6% | 63.3% |
| PY-BiGRUCNN | 72.3% | 71.9% | 69.8% | 71.2% | |
| HZ-BiGRUCNN | 75.2% | 72.7% | 72.6% | 72.2% | |
| Word-BiGRUCNN | 83.6% | 81.6% | 80.1% | 79.8% | |
| POS-Word-BiGRUCNN | 85.1% | 84.2% | 81.9% | 82.1% | |
| PY-Word-BiGRUCNN | 86.0% | 84.8% | 82.2% | 83.2% | |
| HZ-Word-BiGRUCNN | 87.2% | 85.7% | 84.3% | 84.2% | |
| PY-POS-Word-BiGRUCNN | 89.1% | 87.6% | 89.3% | 87.5% | |
| HZ-POS-Word-BiGRUCNN | 89.4% | 89.6% | 89.3% | 89.5% | |
| PY-HZ-Word-BiGRUCNN | 90.2% | 89.6% | 89.9% | 89.1% | |
| PY-POS-HZ-Word-BiGRUCNN(本文) | 91.1% | 91.3% | 90.8% | 89.7% |
将双通道模型与三通道模型对比发现,结合词性和词向量的模型进行拼音特征融合为三通道后,模型的准确率由78.1%、85.1%分别提升为81.3%、89.1%。同理,将词性、汉字字符和词向量融合后模型的效果也有所提升。而在词向量模型的基础上将词性特征、拼音字符特征和汉字字符特征进行多特征融合后,模型的效果达到最佳,准确率为83.3%和91.1%,多特征融合的模型之间相互比较可以发现,模型在词向量的基础上进行不同特征融合均能够对模型起到积极的作用,同时结合多种特征可以进一步加深模型的语义理解,实现多种特征优势互补。
再结合其他几个评价指标来看,P为查全率,在两种实验数据中,融合多特征的模型效果最好,其中模型的查全率和召回率最高。R为召回率,即预测正确的样本数与实际样本总数的比值,本文的模型预测错误的样本数在实际样本总数中所占比例最低。实验结果表明,本文模型的分类效果提升显著,这表明在词级别特征的基础上结合拼音字符特征、汉字字符特征和词性特征,对于文本分类性能有很大的改善。
(2) 基准模型对比
为了验证模型的分类效果,使用计算机专利数据将本文模型与常用的模型LSTM、GRU、BiGRU、CNN进行对比。在对基准模型进行实验时,对待分类文本进行预处理,使用Word2Vec进行向量化,向量的维度为100,都为单通道的实验。实验结果如表6所示。可以看出,当GRU和LSTM相比较时,GRU更胜一筹。因为GRU在结构上比LSTM少一个门,这使GRU模型的训练参数较少,训练时间也将明显缩短,在同一时间内模型的收敛速度更快。通过单向GRU和双向GRU的比较可以发现,单向GRU只能对正面的上下文信息进行编码理解,而不能获取反向的上下文信息,而双向GRU有效解决了这个问题,能够获取更为全面的信息。从实验结果中可得到,BiGRU的文本分类性能较GRU要好,更有利于分类任务。但是,BiGRU也存在一定的缺陷,因为需要进行双向训练,会增加模型的训练时间,需要消耗一定的时间成本。
表6 基准模型对比结果
Table 6
| 模型 | Acc | P | R | F1 |
|---|---|---|---|---|
| LSTM | 74.4% | 74.7% | 74.7% | 74.9% |
| GRU | 75.0% | 74.4% | 75.7% | 75.1% |
| BiGRU | 75.2% | 75.5% | 75.5% | 75.6% |
| CNN | 73.7% | 72.1% | 71.5% | 71.6% |
| PY-POS-HZ-Word-BGRU(本文) | 83.3% | 83.6% | 82.9% | 83.4% |
从实验结果可知,本文模型的准确率最高,F1值也达到最高。首先,本文模型同时结合BiGRU和CNN模型,能够在有效获取上下文语义信息的同时,去除冗余信息进行局部特征获取,在模型上实现了优势互补;其次,本文模型在通常文本分类任务获取词级别语义特征的基础上,结合字符特征和词性特征,实现语义特征扩展,获取多特征语义实现特征补充,有效提升了文本的分类性能。因此,在与基准模型对比时,本文模型分类效果达到最佳,这说明本文模型在文本分类任务中具有很大的优势。
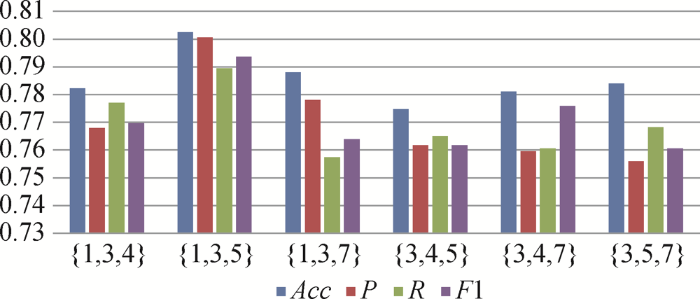
(3) 卷积大小对模型的影响
为了验证不同卷积核大小对模型效果的影响,获得最佳性能时卷积核的大小,使用计算机专利数据将模型采用多种不同卷积大小进行实验。
图4
图5
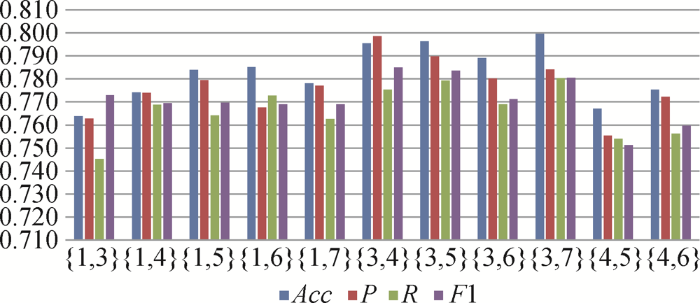
图6
(4) 词向量维度大小对实验的影响
为了探究不同的词向量维度对于模型分类性能的影响,本文使用不同的词向量维度进行对比实验,以保证问题分类的准确性和时效性。实验结果如图7所示,横坐标表示词向量的维度,纵坐标表示模型的分类准确率。由实验结果可知,随着词向量维度的增加,模型的准确率在不断改变。当维度从50增加到150时,模型的准确率在不断提高;当维度从150增加到350时,准确率趋于稳定。而随着维度的不断增加,模型的训练时间随之增长,增长的幅度越来越大,综合考虑模型的分类时效性和准确率,因此选择100作为词向量维度。
图7

5 结语
文本分类是自然语言处理中的关键任务之一,为了有效获取关键信息,捕获更深层的抽象信息,本文提出多特征融合文本分类模型。在构建模型中,首先要进行语义特征表示,将预处理后的待分类文本进行分词后,获取词性特征扩展、拼音字符特征扩展、汉字字符特征扩展和词级别特征扩展,构建多种不同的语义特征,作为模型的输入;将特征输入BiGRU中进行双向上下文特征获取,然后输入CNN中进行局部特征获取,再输入最大池化操作获取最大特征,去除冗余特征,最终输入到Softmax层中进行分类,从而实现文本分类任务。本文的主要贡献如下。
(1)使用拼音作为字符特征扩展作为文本表征方式,解决中文字符难以量化、同音词和拼写错误的问题。
(2)将拼音字符特征与词特征作为联合输入,解决单一字符特征或词特征维度不足的问题。
(3)结合词性进行语义补充,提高模型的特征表达能力。
(4)将汉字字符特征作为特征补充,提高了模型的文本表征能力。
本文的多特征融合模型有效结合了词级别特征、拼音字符级别特征、汉字字符特征和词性特征,实现了语义多特征扩展,在丰富语义信息的同时降低了噪声的干扰,有效优化了模型的分类性能。
虽然本文模型的文本分类效果比基准模型等分类效果有一定的提升,但仍存在一定的不足和可改进之处。根据模型的分类准确率可知,模型仍然存在一定的错误分类情况。要想更好地提升模型的分类效果,一方面,可以考虑加入关键词注意力机制,对关键词进行注意力计算,保留更多的关键信息;另一方面,考虑加强对数据的预处理、及时更新停用词表等,提高数据的质量。由于时间和精力的限制,本文没有考虑注意力机制。未来工作将在此基础上进行深入的研究。
作者贡献声明
王艳:提出研究思路,对研究方法、研究过程进行修正;
王胡燕:数据处理及实验分析,论文撰写;
余本功:提出研究思路,设计研究方案,论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: 1115419302@qq.com。
[1] 王胡燕. Computer Patents.xlsx. 计算机专利分类数据集.
[2] 王胡燕. Sohu news.xlsx. 搜狐新闻数据集.
[3] 王胡燕. 实验图表数据.xlsx. 深度学习模型图表.
[4] 王胡燕. 分类实验结果数据.xlsx. 文本分类实验结果数据.
参考文献
基于类邻域字典的线性回归文本分类
[J/OL].
Class-wise Nearest Neighbor Dictionary based Linear Regression Model for Text Classification
[J/OL].
朴素Bayes分类器文本特征向量的参数优化
[J].
Parameter Optimization of Text Feature Vector of Naïve Bayesian Classifier
[J].
Convolutional Neural Networks for Sentence Classification
A Convolutional Neural Network for Modelling Sentences
Deep Pyramid Convolutional Neural Networks for Text Categorization
基于MAC-LSTM的问题分类研究
[J].
Question Classification Based on MAC-LSTM
[J].
一种基于LSTM和CNN混合模型的文本分类方法
[J].
Text Classification Method Based on Hybrid Model of LSTM and CNN
[J].
基于双通道特征融合的WPOS-GRU专利分类方法
[J].
WPOS-GRU Patent Classification Method Based on Two-channel Feature Fusion
[J].
基于融合特征的商品文本分类方法研究
[J].
Research on Commodity Text Classification Based on Fusion Features
[J].
用于短文本分类的DC-BiGRU_CNN模型
[J].
DC-BiGRU_CNN Model for Short-text Classification
[J].
基于BiLSTM-CRF的政府微博舆论观点抽取与焦点呈现
[J].
Public Opinion Extraction and Focus Presentation in Government Microblog Based on BiLSTM-CRF
[J].
我国省级科技管理部门官网文本数据的主题建模分析研究
[J].
Research on Topic Modeling of China’s Provincial Scientific and Technology Management Department Based on Official Website Text Data
[J].
结合卷积神经网络和词语情感序列特征的中文情感分析
[J].
Combining Convolutional Neural Networks and Word Sentiment Sequence Features for Chinese Text Sentiment Analysis
[J].
字符级卷积神经网络短文本分类算法
[J].
Character-Level Convolutional Neural Networks for Short Text Classification
[J].
一种改进的卷积神经网络恶意域名检测算法
[J].
Improved Algorithm for Detection of the Malicious Domain Name Based on the Convolutional Neural Network
[J].
融合多粒度信息的文本向量表示模型
[J].
A Text Vector Representation Model Merging Multi-Granularity Information
[J].
基于卷积神经网络的微博情感倾向性分析
[J].
Convolutional Neural Networks for Chinese Micro-blog Sentiment Analysis
[J].
基于CP-CNN的中文短文本分类研究
[J].
Chinese Short Text Classification Based on CP-CNN
[J].
Chinese Short Text Multi-Classification Based on Word and Part-of-Speech Tagging Embedding
Sentiment Analysis by POS and Joint Sentiment Topic Features Using SVM and ANN
[J].
DOI:10.1007/s00500-018-3349-9
[本文引用: 1]

Sentiment analysis using the part-of-speech (POS) tags and the joint sentiment topic features is a novel idea. As the sentiment analysis requires effective selection of features which are utilized in the determination of sentiment. In this paper, the POS tagging is performed by using hidden Markov model where the unigrams, bigrams and bi-tagged features are extracted. Similarly, the nonparametric hierarchical Dirichlet process is employed to extract the joint sentiment topic features. The extracted features are combined together in a linear fashion in order to effectively select the best feature subset. The best features are selected based on maximum relevance and minimum redundancy mutual information of the feature subset. The mutual information is used to measure the relevance between features and sentiment analysis decision. The maximum relevance and minimum redundancy mutual information remove the redundant features by considering the mutual information between features. Feature selection is carried out by these fitness conditions using firefly optimization algorithm. Then, the chosen feature subset is employed in the classification process which is performed using support vector machine and artificial neural networks. Thus the proposed sentiment analysis method provides more accurate sentiment recognition. Experimental results show that the proposed sentiment analysis method improves the accuracy and reduces the training speed for sentiment analysis.
结合词性特征与卷积神经网络的文本情感分析
[J].
Text Sentiment Analysis Combined with Part of Speech Features and Convolutional Neural Network
[J].
Classification of Children Stories in Hindi Using Keywords and POS Density
[C]//
文本分类中受词性影响的特征权重计算方法
[J].
Feature Weighting Method Affected by Part of Speech in Text Classification
[J].
Tibetan Text Classification Using Distributed Representations of Words
Accuracy Enhancement of Collaborative Filtering Recommender System for Blogs Using Latent Semantic Indexing
[C]//
Integrating Collocation as TF-IDF Enhancement to Improve Classification Accuracy
Feature Extraction and Performance Measure of Requirement Engineering (RE) Document Using Text Classification Technique
Sentiment Classification Based on Part-of-Speech and Self-Attention Mechanism
[J].DOI:10.1109/Access.6287639 URL [本文引用: 1]
The Effect of POS Tag Information on Sentence Boundary Detection in Turkish Texts
Investigating Bi-LSTM and CRF with POS Tag Embedding for Indonesian Named Entity Tagger
On Empirical Evaluation of Deep Architectures for Indonesian POS Tagging Problem
基于融合词性的BiLSTM-CRF的期刊关键词抽取方法
[J].
Keyword Extraction for Journals Based on Part-of-Speech and BiLSTM-CRF Combined Model
[J].
Encoding Syntactic Knowledge in Neural Networks for Sentiment Classification
[J].
POS-Tags Features for Protein-Protein Interaction Extraction from Biomedical Articles
[C]//
基于细粒度多通道卷积神经网络的文本情感分析
[J].
Sentiment Analysis of Texts Based on Fine-Grained Multi-Channel Convolutional Neural Network
[J].
Distributed Representations of Words and Phrases and Their Compositionality

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}