




1 引言
相关研究中,基于用户评论行为和评论内容的特征识别虚假用户或虚假评论最为常见[3⇓⇓⇓⇓⇓-9],但这些研究只能识别特定行为的虚假用户或特定风格的虚假评论,难以捕捉不断变化的虚假行为及虚假评论特征。一些研究弥补了上述不足,考虑用户、用户群体、用户评论或商户等主体之间的关联关系,提取各关联主体的评估指标,构建迭代模型以识别虚假主体[10-11]。这些研究对于揭示虚假用户的特征、描述虚假用户与关联主体之间的关系等起到重要的启示作用,但都忽视了由用户个体异质性而产生的偏差。事实上,电商环境下的用户偏差至少存在于两个方面:内容偏差和行为偏差。内容偏差体现在用户评论内容风格之间的不一致性,例如一个虚假用户可能经常发表虚假评论,也可能会在某个时段以真实用户身份发表真实评论,评论风格会不一致。行为偏差主要体现为同一家商铺中的某用户与其他用户在评论行为上的不一致性,例如一家商铺的用户群中,有的是高活跃度用户,有的是高好评率用户,有的是偏好提问的用户,有的是密集评论用户等,评论行为明显不一致。最新研究指出,不同用户发表的评论内容偏差可以作为识别虚假用户或虚假评论的一个有效指标[12-13],证实了不同用户评论内容偏差的存在及其对识别虚假主体的有效性,但尚未探讨同一用户评论内容是否存在偏差、不同用户之间行为偏差是否存在影响等重要问题。
如何描述这些方面的用户偏差,如何测度该用户偏差,这些用户偏差又是否能提升虚假用户的识别精度,目前还没有系统性的研究。
基于此,本研究从用户-评论-商户(User-Review-Shop,URS)三个主体对象分别提取虚假度指标,以用户-评论-商户虚假度的增强关系为基础,围绕用户-评论内容和商户-用户行为的不一致性,分别分析用户内容偏差和行为偏差,进而建立用户-评论-商户虚假度迭代修正模型(User-Review-Shop False Degree Iteration Revised Model,URS-FDIRM),最后验证模型对虚假用户识别的有效性,为分析用户偏差、改进虚假用户检测提供新的研究和实践启示。
2 相关研究
虚假用户的识别方法一般分为有监督学习方法和无监督方法。与识别虚假评论类似,采用有监督学习方法识别虚假用户,首先提取与虚假用户相关的特征集合,然后结合机器学习分类算法,训练分类模型识别虚假用户[16⇓-18]。鉴于虚假用户公开数据集难以获取,同时虚假用户的评论行为经常变化,有监督学习方法难以持续追踪不同类型的虚假用户,现有研究越来越侧重通过无监督方法识别虚假用户,如通过深入挖掘用户、评论、产品或商户之间的内在关系,应用统计推断、关系网络、图模型等方法识别虚假用户或虚假群组[5,11,19-20]。其中,Mukherjee等[5]较早提出用户虚假度度量方法,建立一系列与用户行为相关的指标后,运用贝叶斯原理,结合吉布斯抽样得到用户虚假度的后验分布以及与各个指标相关的虚假度概率分布,对虚假度进行排名后得到最终的用户虚假度排名。相较而言,图模型方法更为普遍。Wang等[10]指出,基于用户行为特征识别虚假用户,只能获得一些具有特定特征的虚假评论者,因此他们采用图模型方法建立用户、评论和商户三种节点的联系,运用三者之间的可信度关系对各自的可信度进行迭代,最终得到评论者、评论和商户的可信度排序,并用于识别虚假用户。
上述研究为进一步拓展图模型方法识别虚假用户提供了重要借鉴。基于此,本研究以用户偏差为视角,从三个方面进行创新性思考和研究。
(1)不同于已有研究考察不同用户在评论内容上的偏差,本研究聚焦用户个体异质性,着重考察同一用户发表的评论内容中存在的偏差和不同用户之间评论行为上存在的偏差,从用户自身以及不同用户之间两个不同方面,全面分析可能存在的用户偏差。
(2)考虑到用户偏差度量的精准性,采取均值法、JS散度和KL散度三种方法,分别用于测度用户内容偏差和用户行为偏差,以检验偏差度量的有效性。
(3)以用户偏差和用户-评论-商户三个关联主体虚假度增强关系作为切入点,构建URS-FDIRM模型识别虚假用户,从用户偏差的视角,深入揭示用户-评论-商户虚假度之间的内联关系。
3 研究方法
3.1 模型整体设计
本文提出的URS-FDIRM模型总体设计如图1所示。主要由5个部分组成:①URS虚假度相关指标提取与虚假度计算;②用户偏差分析;③URS虚假度增强关系;④URS-FDIRM模型构建;⑤模型评估与分析。基于用户行为特点、评论文本和商户特点,分别提取表征用户行为、评论内容和商户声誉特点的虚假度指标,并计算用户-评论-商户的初始虚假度。引入均值法、JS散度和KL散度三种测度方法,分别度量个体用户的评论内容偏差和商户中的用户行为偏差。以用户-评论-商户虚假度增强关系为基础,将内容偏差和行为偏差作为权重因子,设计迭代模型,不断修正初始虚假度,以识别虚假用户。最后,选择最优模型进行性能比较和适应性分析,以验证模型的适用性和指标的有效性。
图1
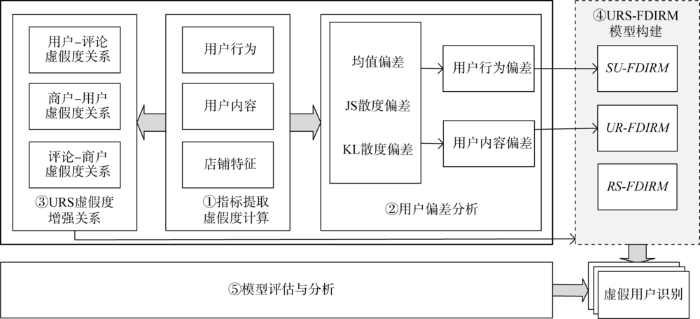
3.2 用户-评论-商户虚假度指标与计算
(1) 用户虚假度指标
与正常用户相比,虚假用户在评论行为上往往表现出明显异常,如点评的活跃程度、点评的突发性、点评的频率等。结合相关研究,本文建立以下主要用户虚假度指标,将其进行标准化处理后,使其值在0~1之间,越接近于1,指标虚假程度越高;越接近于0,指标虚假程度越低。
通常,平台中的用户被赋予的等级体现在多个方面,如用户上线次数、用户与他人互动频率、用户账户年限、用户评论数等,它体现了用户整体的活跃程度。其中,
②用户社交粉丝数(UF)[13]计算方法如公式(2)所示。
其中,
③用户提问与回答比(UQA)计算方法如公式(3)所示。
其中,
其中,
其中,
其中,
⑦用户评论频率(URF)[16]计算方法如公式(7)所示。
其中,
⑧用户评论集中度(URC)[18]计算方法如公式(8)所示。
其中,
其中,
(2) 评论虚假度指标
虚假用户发表的评论与正常评论相比,在长度、评分、图片数、评论相似度等方面可能会显现出异常。基于此,建立以下评论虚假度指标,将其进行标准化处理后,使其值在0~1之间,越接近于1,指标虚假程度越高;越接近于0,指标虚假程度越低。
其中,
其中,
③图片数(RPN)[13]计算方法如公式(12)所示。
其中,
其中,
(3) 商户虚假度指标
虚假商户往往是那些刚刚建立、规模不大、急需大量评论提高自身影响力或声誉的商户。基于此,建立下列商户虚假度指标,将其进行标准化处理后,使其值在0~1之间,越接近于1,指标虚假程度越高;越接近于0,指标虚假程度越低。
①商户年龄(SA)[16]计算方法如公式(14)所示。
其中,
②商户规模(SS)计算方法如公式(15)所示。
其中,
其中,
④商户高评论用户数(SUN)计算方法如公式(17)所示。
其中,
综上,用户、评论和商户虚假度相关的指标总结如表1所示。
表1 用户-评论-商户虚假度相关指标
Table 1
| 类型 | 指标缩写 | 指标个数 |
|---|---|---|
| 用户虚假度指标 | 用户活跃等级(UL) 用户社交粉丝数(UF) 用户提问与回答比(UQA) 时间间隔(UTS) 用户突发评论数(URB) 用户评论次数(URN) 用户评论频率(URF) 用户评论集中度(URC) 用户在商户中的评论集中度(USC) | 9 |
| 评论虚假度指标 | 评论长度(RL) 极端评分(RR) 评论图片数(RPN) 评论相似度(RS) | 4 |
| 商户虚假度指标 | 商户年龄(SA) 商户规模(SS) 商户早期评论数(SRN) 商户高评论用户数(SUN) | 4 |
(4) 用户-评论-商户虚假度计算
评价对象在单个指标上的取值并不能有效评估其整体虚假程度,因此根据各个虚假度指标的表现,计算评价对象的整体虚假程度。计算思路为:将评价对象各指标进行向量化表示后,与元素全为1的等长向量进行余弦相似度计算,进而求得评价对象的虚假度。基于此,得到每个用户的虚假度
其中,
同样地,得到每条评论的虚假度
其中,
3.3 用户偏差分析
对于某个虚假用户,可能亲自撰写评论内容,也可能抄袭其他真实用户的评论内容,因此其每条评论风格各异,会出现较大偏差。再者,同一家商户中,可能同时存在虚假用户和真实用户,但虚假用户的行为通常偏离于正常用户的普遍行为。可见,虚假用户与正常用户相比,至少存在两种偏差:内容偏差和行为偏差,分别从用户-评论、商户-用户对应的虚假度指标中,考虑存在的内容偏差和行为偏差。
(1) 用户-评论内容偏差
个体层面上,同一用户发布的评论大多风格相似,评论风格总体上趋于稳定。若同一用户的评论风格波动较大,该用户有可能是可疑用户。因此,可以通过测度用户发布的某条评论与该用户总体评论风格之间的差异,发现异常的评论。偏差越大,说明用户的评论风格波动较大,越有可能是虚假评论。为此,以用户为单位,分析同一用户
其中,
(2) 商户-用户行为偏差
对同一商户发表评论的用户之间的评论行为趋于协同。因此,可以通过测度同一商户中个体用户与该商户的群体评论行为之间的差异,发现店铺中的异常用户。偏差越大,说明该用户的评论行为与群体行为差异越大,不能很好地代表该店铺的评价水平。为此,以商户为单位,分析同一商户
其中,
(3) 偏差测度
基于JS散度偏差[12],本文引入均值法、JS散度和KL散度三种方法,用于测度用户偏差。
①均值偏差Mean_Dev
均值偏差是各个相关指标与组内各指标的均值的差异,以用户行为偏差为例,计算方法如公式(23)所示。
其中,
②JS散度偏差JS_Dev
JS散度通常用于比较两个分布的差异,JS散度越小,两个分布越相似,偏差越小。通过比较各指标值实际分布与期望分布的差异大小进行偏差的测度[12],以用户虚假度偏差为例,计算方法如公式(24)所示。
其中,
③KL散度偏差KL_Dev
KL散度也是一种比较两个分布差异的方法,在某些情况下度量分布差异能取得较好的效果。以评论虚假度偏差为例,计算方法如公式(25)所示。
其中,
3.4 URS虚假度增强关系与URS-FDIRM模型设计
图2
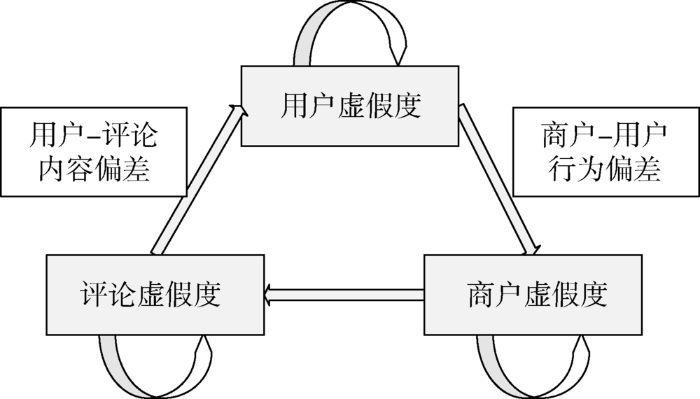
基于评论虚假度和用户虚假度之间的增强关系,可以在用户虚假度计算过程中,引入该用户的评论虚假度影响,从而利用评论的虚假度结果和用户-评论的内容偏差,不断修正用户虚假度计算结果。同理,基于用户虚假度和商户虚假度之间的增强关系,在商户虚假度计算过程中,引入商户中的用户虚假度影响,利用用户的虚假度结果和商户-用户的行为偏差,不断修正商户虚假度计算结果。评论与商户节点没有涉及用户对象,但基于评论虚假度和商户虚假度的增强关系,直接使用更新后的商户虚假度对评论虚假度进行迭代修正。上述计算过程对应三组模型,分别为UR-FDIRM、SU-FDIRM、RS-FDIRM。
(1) UR-FDIRM
根据用户每条评论内容偏差分析的结果,设计用户-评论(User-Review,UR)虚假度偏差修正因子
其中,
基于用户和评论的虚假度增强关系,利用用户-评论虚假度偏差修正因子,实现由评论虚假度对用户虚假度的更新与调整,如公式(27)所示。
其中,
(2) SU-FDIRM
根据店铺中每个用户行为偏差分析的结果,设计商户-用户(Shop-User,SU)虚假度偏差调节因子
其中,
基于商户和用户的增强关系,利用商户-用户虚假度偏差修正因子
其中,
(3) RS-FDIRM
基于评论-商户(Review-Shop,RS)的增强关系,直接使用商户虚假度对评论虚假度进行更新,如公式(30)所示。
其中,
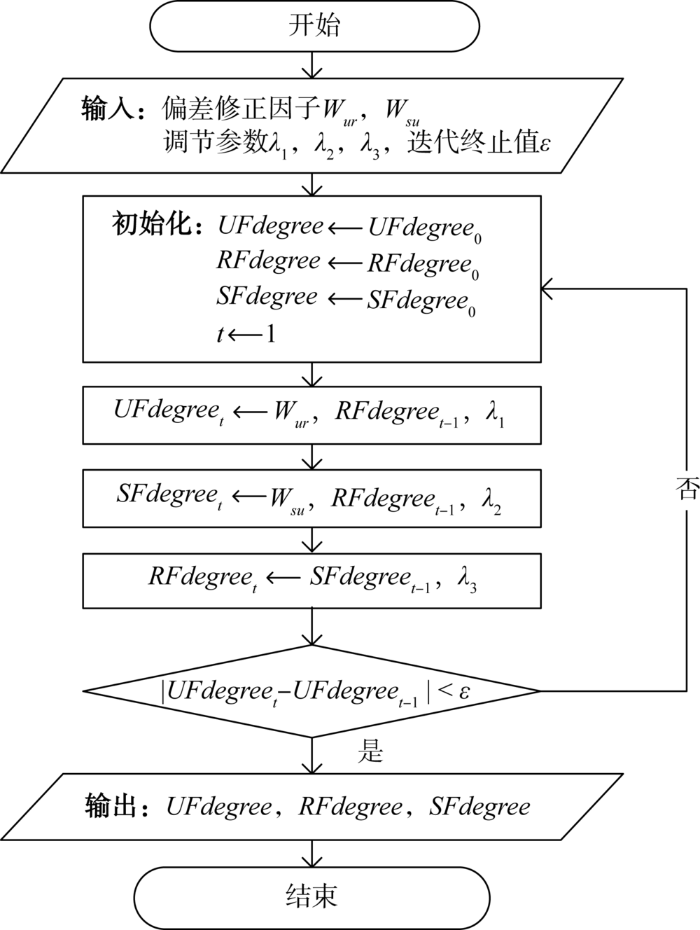
(4) 迭代计算过程
迭代开始时,根据用户-评论-商户的虚假度指标含义,分别计算用户、评论、商户的初始虚假度,作为各个对象虚假度的初始值,然后利用公式(27)、公式(29)和公式(30)开始迭代,直至模型收敛。迭代完成后得到的
图3
4 实 验
4.1 实验数据
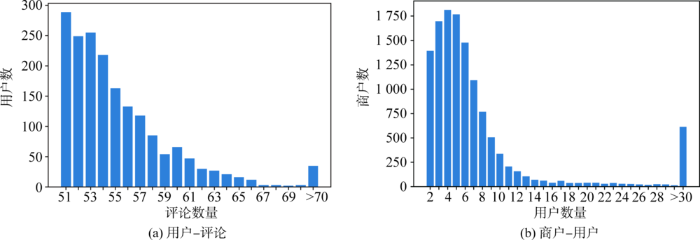
本文以马蜂窝平台(https://www.mafengwo.cn/)作为实验数据来源,重点采集北京、上海、广州、深圳等一线城市的相关数据。截至2021年6月,共获得酒店数据14 095条,用户数据7 882条,评论数据339 364条。文献[12]指出,用户发表的评论越多,体现出的用户行为就越多,就能够为虚假用户识别提供更多的线索。考虑到本文需要人工标注一部分数据集,而虚假评论者的标注任务又具有一定复杂性,为增加模型识别虚假评论者的准确性,本文参照文献[12]最终选取发布评论数较多的用户作为分析对象。此外,根据帕累托法则(Pareto Principle),80%的虚假评论来自20%的用户,因此,选取评论总数排名约前20%的用户。经计算,前20%的用户评论数最少在50条左右,如图4所示。在初始数据集中剔除评论总数小于50条的用户数据及相应的酒店、评论数据。
图4
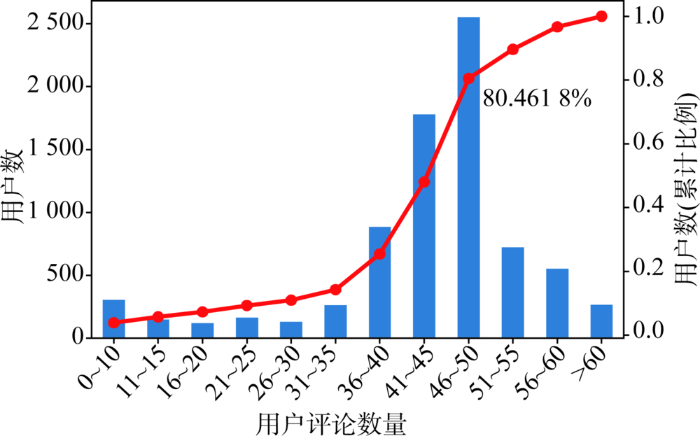
图4
用户评论数量-用户数累计分布统计
Fig.4
Cumulative Distribution of Number of User Reviews and Number of Users
最终获得的实验数据包括13 551家酒店、1 829个用户和102 788条评论数据。各指标在标准化之前的描述性统计如表2所示。在实验数据集中,初步统计用户发表的评论数分布情况和各个商户中的用户数分布情况,如图5所示。在1 829个用户中,多数用户的评论数集中在51~60条之间,有少数用户的评论数大于70条,结合表2,用户评论数最高可至300条。这类用户的评论数量明显偏离总体分布,可能存在异常用户。在13 551家商户中,用户数大多集中在2~10之间,结合表2,最多用户数达到73个,经统计可得,约86.54%的商户高评论用户数小于10,95.12%的商户高评论用户数小于30,而有些商户中的高评论用户数远大于30,明显偏离总体分布,说明这些商户可能存在异常。
表2 描述性统计
Table 2
| 对象 | 指标 | 描述 | 最小值 | 最大值 | 中位数 | 均值 | 标准差 |
|---|---|---|---|---|---|---|---|
| 用户 | UL | 用户活跃等级 | 6.000 0 | 45.000 0 | 17.000 0 | 16.840 0 | 3.460 0 |
| UF | 用户社交粉丝数 | 0.000 0 | 5 927.000 0 | 1 182.000 0 | 960.820 0 | 520.730 0 | |
| UQA | 用户提问与回答比 | 0.000 0 | 1.000 0 | 0.000 0 | 0.040 7 | 0.156 6 | |
| UTS | 用户评论时间间隔 | 1.000 0 | 4 087.000 0 | 2 049.000 0 | 1 985.270 0 | 433.970 0 | |
| URB | 用户突发评论数 | 1.000 0 | 132.000 0 | 2.000 0 | 2.780 0 | 7.290 0 | |
| URN | 用户评论次数 | 51.000 0 | 301.000 0 | 54.000 0 | 56.600 0 | 12.600 0 | |
| URF | 用户评论频率 | 0.014 2 | 64.000 0 | 0.026 9 | 0.093 0 | 1.539 6 | |
| URC | 用户评论集中度 | 0.012 2 | 0.987 6 | 0.037 0 | 0.043 0 | 0.066 2 | |
| USC | 用户在商户中评论集中度 | 0.181 8 | 1.000 0 | 1.000 0 | 0.994 3 | 0.022 5 | |
| 评论 | RL | 评论长度 | 0.000 0 | 576.000 0 | 9.000 0 | 12.470 0 | 13.330 0 |
| RR | 极端评分 | 0.000 0 | 5.000 0 | 5.000 0 | 4.430 0 | 0.770 0 | |
| RPN | 图片数 | 0.000 0 | 10.000 0 | 0.000 0 | 0.002 0 | 0.058 0 | |
| RS | 评论相似度 | 0.000 0 | 1.000 0 | 0.028 0 | 0.039 0 | 0.045 0 | |
| 商户 | SA | 商户年龄 | 0.000 0 | 108.000 0 | 8.000 0 | 9.807 6 | 7.612 7 |
| SS | 商户规模 | 1.000 0 | 1 500.000 0 | 80.000 0 | 102.070 0 | 92.610 0 | |
| SRN | 商户早期评论数 | 1.000 0 | 73.000 0 | 5.000 0 | 7.596 5 | 9.910 7 | |
| SUN | 商户高评论用户数(≥50) | 2.000 0 | 73.000 0 | 5.000 0 | 7.551 3 | 9.782 0 |
图5
4.2 用户-评论-商户虚假度关系检验
为验证本文所建立的用户-评论-商户虚假度增强关系的合理性,首先检验用户、评论、商户三者之间的虚假度是否存在一定程度的关联关系,为此对用户-评论、商户-用户、评论-商户两两之间迭代前的初始虚假度与迭代后的最终虚假度分别进行相关系数检验。检验结果如表3所示,在0.05的显著性水平下,各P值均显著,说明用户-评论、商户-用户、评论-商户两两之间的虚假度在迭代前与迭代后均存在相关关系,这为本文模型的建立提供了支撑。
表3 相关系数检验
Table 3
| 检验对象 | |cor| | |T value| | P value | |||
|---|---|---|---|---|---|---|
| 迭代前 | 迭代后 | 迭代前 | 迭代后 | 迭代前 | 迭代后 | |
| 用户-评论虚假度 | 0.379 7 | 0.051 3 | 17.544 0 | 2.197 1 | 0.000 0*** | 0.028 1*** |
| 商户-用户虚假度 | 0.094 8 | 0.098 3 | 11.075 0 | 11.488 0 | 0.000 0*** | 0.000 0*** |
| 评论-商户虚假度 | 0.458 2 | 0.458 2 | 165.300 0 | 165.300 0 | 0.000 0*** | 0.000 0*** |
(注:***表示在0.05水平上显著。)
4.3 用户偏差分析
(1) 指标偏差分析
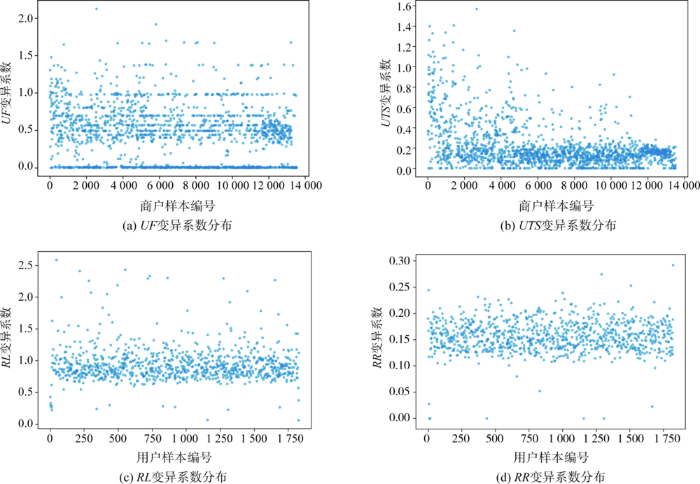
狭义上,用户偏差体现为用户相关指标值与整体平均水平的差异。变异系数可表示一组数据的离散程度,变异系数越大,说明与该组数据的平均数相比,这组数据的离散程度越大,即偏差越大。由此可知,若某指标上用户的变异系数越大,则存在的用户偏差越大。为此,计算用户各指标的变异系数,初步描述用户在相关指标上是否存在一定程度的偏差,结果如图6所示。
图6
(2) 虚假度偏差分析
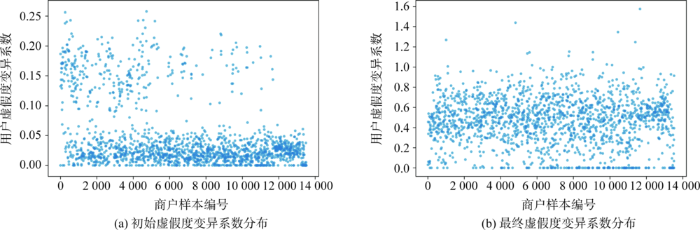
由于用户的虚假度是否存在偏差是识别虚假用户的关键,因此以同样方法分析用户的虚假度是否存在偏差。分别计算商户内的用户初始虚假度(模型迭代前)和最终虚假度(模型迭代后)的变异系数,如图7所示。其中,多数点不同程度地偏离x轴,说明不论是模型迭代前,还是模型迭代后,商户中相当多数量的用户虚假度存在偏差,为本文从用户偏差的视角识别虚假用户奠定了基础。
图7
4.4 模型性能分析
(1) 虚假用户识别结果
表4 标注规则
Table 4
| 规则 | 规则说明 |
|---|---|
| 1 | 如果一个用户的评论总是与对应商户中其他用户的评论差别很大,这个用户是可疑的。例如,如果一个用户总是给他评论过的商户很高的评价,而其余用户给这些商户的评价较低,此时该用户是可疑的[10]。 |
| 2 | 如果一个用户的评论总是与对应商户中其他用户早已发布的评论很相似,这个用户是可疑的。因为虚假用户往往会复制他人已有的评论达到快速评论提高影响的目的[15]。 |
| 3 | 如果一个用户绝大多数评论都集中在某一家或某几家商户,且总是发布好评或差评,这个用户是可疑的。此时很可能存在用户与商户之间的串谋关系[18]。 |
| 4 | 鉴于本文所用的数据为酒店数据,具有其特殊性,如果一个用户在一天内发布了大量评论,这个用户是可疑的。 |
| 5 | 仅仅从评论文本观察,如果一个用户的评论总是遵循一个固定的模板,或是毫无逻辑的辞藻堆砌,这个用户是可疑的。 |
| 6 | 进入用户主页,观察用户相关数据及日常行为,主观感受该用户是否可疑。 |
| 7 | 在进行数据标注时,要综合所有相关信息进行考量,不可仅看一个方面做出想当然的判断。 |
依据多数投票的原则,对于一个用户,如果至少两个标注者认为其是虚假用户,则标记为1,否则标记为0,最终在1 829个用户中标注出279位虚假用户。经过对标注结果的Cohen-Kappa检验,两两标注结果的Kappa平均值达91.65%,标注的一致性结果较为理想。
建立均值偏差、JS散度偏差、KL散度偏差下的URS-FDIRM模型和未使用偏差进行迭代的模型,分别表示为URS-FDIRM_MEAN、URS-FDIRM_JS、URS-FDIRM_KL及URS-FDIRM_WITHOUT_DEV,建立模型时三组参数
表5 模型实验结果
Table 5
| 模型 | F1值 |
|---|---|
| URS-FDIRM_MEAN | 0.914 0 |
| URS-FDIRM_JS | 0.878 1 |
| URS-FDIRM_KL | 0.874 6 |
| URS-FDIRM_WITHOUT_DEV | 0.871 0 |
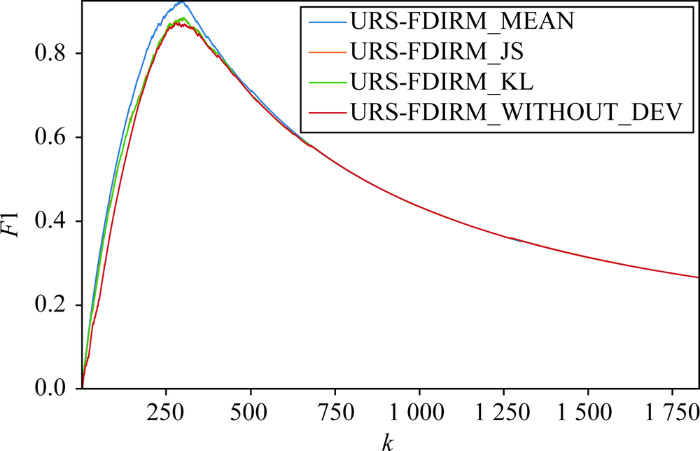
均值偏差URS-FDIRM_MEAN模型的识别效果最好,F1值可达91.40%,JS散度偏差URS-FDIRM_JS模型次之。整体上,三种偏差下的URS-FDIRM模型的识别效果均好于未使用偏差进行迭代的模型,说明用户偏差是识别虚假用户的重要因素。
表6 不同k值下的URS-FDIRM_MEAN实验结果
Table 6
| k | P | R | F1 | |||
|---|---|---|---|---|---|---|
| 230 | 0.961 0 | 0.795 7 | 0.870 6 | |||
| 240 | 0.954 4 | 0.824 4 | 0.884 6 | |||
| 250 | 0.944 2 | 0.849 5 | 0.894 3 | |||
| 260 | 0.934 9 | 0.874 6 | 0.903 7 | |||
| 270 | 0.922 5 | 0.896 1 | 0.909 1 | |||
| 280 | 0.914 6 | 0.921 1 | 0.917 9 | |||
| 290 | 0.903 8 | 0.942 7 | 0.922 8 | |||
| 300 | 0.890 4 | 0.960 6 | 0.924 1 | |||
| 310 | 0.865 0 | 0.964 2 | 0.911 9 | |||
| 320 | 0.844 2 | 0.971 3 | 0.903 3 | |||
| 330 | 0.818 7 | 0.971 3 | 0.888 5 | |||
| 340 | 0.797 7 | 0.974 9 | 0.877 4 | |||
图8
进一步考察迭代过程中三组
表7
Table 7
| F1 | F1 | ||
|---|---|---|---|
| 0.0 | 0.871 0 | 0.6 | 0.591 4 |
| 0.1 | 0.914 0 | 0.7 | 0.483 9 |
| 0.2 | 0.910 4 | 0.8 | 0.344 1 |
| 0.3 | 0.842 3 | 0.9 | 0.222 2 |
| 0.4 | 0.770 6 | 1.0 | 0.179 2 |
| 0.5 | 0.706 1 |
(2) 与基准方法对比分析
表8 多个方法的分类效果比较
Table 8
| 模型 | P | R | F1 |
|---|---|---|---|
| URS-FDIRM_MEAN | 0.893 3 | 0.960 6 | 0.925 7 |
| LR | 0.881 5 | 0.474 1 | 0.613 1 |
| RF | 0.720 5 | 0.131 6 | 0.221 6 |
| KNN | 0.939 2 | 0.737 0 | 0.825 7 |
| DNN | 1.000 0 | 0.750 0 | 0.857 1 |
| Fsum | 0.262 9 | 0.709 7 | 0.383 7 |
在虚假用户识别方面,URS-FDIRM_MEAN、KNN、DNN三个方法的识别效果较好。尽管DNN与KNN在P值上优于其他方法,但R值较小,导致最终的F1值低于本文模型;URS-FDIRM_MEAN在R、F1值两个指标上优于其他方法,表明与其他方法相比,该模型对于虚假用户识别更有效;此外,LR、RF、Fsum方法识别效果较差。
4.5 模型适应性分析
为检验各虚假度指标在虚假用户识别上的有效性,以虚假用户标注标签(0或1)为自变量、各个相关指标为因变量分别进行方差分析。方差分析可用来检验分类型自变量对数值型因变量的影响。为保证虚假用户标注标签与各指标的一一对应,对评论虚假度指标与商户虚假度指标以用户为单位,在各指标上取均值,方差分析结果如表9所示。
表9 方差分析汇总
Table 9
| 指标 | Mean sq | F value | Pr(>F) |
|---|---|---|---|
| UL | 0.205 0 | 35.490 0 | 0.000 0*** |
| UF | 0.314 1 | 41.600 0 | 0.000 0*** |
| UQA | 8.133 0 | 405.000 0 | 0.000 0*** |
| UTS | 0.528 2 | 55.310 0 | 0.000 0*** |
| URB | 0.134 0 | 44.960 0 | 0.000 0*** |
| URN | 0.045 1 | 26.080 0 | 0.000 0*** |
| URF | 0.000 0 | 0.044 0 | 0.833 0 |
| URC | 0.281 8 | 64.980 0 | 0.000 0*** |
| USC | 0.015 3 | 30.550 0 | 0.000 0*** |
| RL | 0.000 0 | 0.523 0 | 0.470 0 |
| RR | 0.013 8 | 0.745 0 | 0.388 0 |
| RPN | 0.000 0 | 1.854 0 | 0.173 0 |
| RS | 0.000 2 | 2.666 0 | 0.103 0 |
| SA | 0.005 2 | 32.170 0 | 0.000 0*** |
| SS | 0.006 0 | 32.020 0 | 0.000 0*** |
| SRN | 0.044 4 | 20.720 0 | 0.000 1*** |
| SUN | 0.046 0 | 21.990 0 | 0.000 0*** |
(注:***表示在0.05水平上显著。)
结果表明,除URF、RL、RR、RPN、RS之外,其余指标均显著,即虚假用户与非虚假用户在这些指标上取值的均值有显著差异。进一步考察不显著的各个指标在本文模型中的作用大小。分别删去各指标,重新按照本文方法建立URS-FDIRM_MEAN模型,得到的模型对于虚假用户识别的效果如表10所示。可知,新模型与原模型相比,识别效果有所下降,这表明虽然虚假用户与非虚假用户在这些指标上取值无明显差异,但这些指标在模型中仍发挥着一定的作用。观察各指标可发现,它们均为用户虚假度指标或评论虚假度指标,未通过显著性检验有可能是商户-用户行为偏差和用户-评论内容偏差过于分散导致的。综上,本文所选择的虚假度相关指标对于虚假用户识别问题的有效性得以验证。
表10 删去各指标后的分类效果比较
Table 10
| 删去的指标 | 新模型的F1值 |
|---|---|
| URF | 0.896 1 |
| RL | 0.408 6 |
| RR | 0.860 2 |
| RPN | 0.881 7 |
| RS | 0.863 8 |
5 结语
针对当前虚假用户识别问题面临的挑战,本研究提出了一种基于偏差的虚假度修正关系模型URS-FDIRM。实验结果表明,该模型具有较好的虚假用户识别性能。本研究的主要工作以构建用户-评论-商户虚假度指标体系为基础,以用户内容偏差和用户行为偏差测度为核心,结合用户偏差和用户-评论-商户虚假度迭代关系,构建虚假用户识别模型,最终提升虚假用户识别精度。
本研究存在以下局限性:
(1) 受限于公开数据集的限制,仅选择马蜂窝平台数据作为实验数据。尽管在数据探索性分析和模型验证等方面取得了理想的实验效果,但未来还应探索更多平台的数据集,拓展模型的应用范围。
(2) 在测度用户偏差方面,检验了均值法、JS散度和KL散度三种方法在建立的指标体系上的测量效果,是否还有其他的用户指标能表征用户偏差,未来可以进行更多的尝试和检验。
作者贡献声明
孟园:拟定研究命题,提出研究思路,论文起草及最终版本修订;
王悦:采集、清洗和分析实验数据,进行实验。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,
[1] 孟园, 王悦. jiudianData.rar. 包括酒店相关数据及酒店中的评论信息.
[2] 孟园, 王悦. users_data.rar. 原始数据, 包括用户相关数据.
[3] 孟园, 王悦. UsersData_all.sql. 处理后的全部用户数据(图4).
[5] 孟园, 王悦. URS_spam.rar. 迭代前后用户-评论-商户两两虚假度数据(表3).
参考文献
Manipulation of Online Reviews: An Analysis of Ratings, Readability, and Sentiments
[J].
Fake Online Reviews: Literature Review, Synthesis, and Directions for Future Research
[J].
基于自适应聚类的虚假评论检测
[J].
Detection of Fake Reviews Based on Adaptive Clustering
[J].
基于行为与内容的科技产品虚假评论识别
[J].
Deceptive Reviews Detection of Technology Products Based on Behavior and Content
[J].
Spotting Opinion Spammers Using Behavioral Footprints
[C]//
Using Deep Linguistic Features for Finding Deceptive Opinion Spam
[C]//
Syntactic Stylometry for Deception Detection
[C]//
Impact of Reviewer Social Interaction on Online Consumer Review Fraud Detection
[J].
Handling Cold-Start Problem in Review Spam Detection by Jointly Embedding Texts and Behaviors
[C]//
Identify Online Store Review Spammers via Social Review Graph
[J].
基于个人-群体-商户关系模型的虚假评论识别研究
[J].
An Individual-Group-Merchant Relation Model for Identifying Online Fake Reviews
[J].
A Unified Framework for Detecting Author Spamicity by Modeling Review Deviation
[J].
From Conflicts and Confusion to Doubts: Examining Review Inconsistency for Fake Review Detection
[J].
基于量化情感的网店垃圾评论检测
[J].
Store Review Spam Detection Based on Quantitative Sentiment
[J].
Collusion-Aware Detection of Review Spammers in Location Based Social Networks
[J].
产品虚假评论文本识别方法研究述评
[J].
Detecting Product Review Spam: A Survey
[J].
基于用户特征提取的新浪微博异常用户检测方法
[J].
Abnormal User Detection Method in Sina Weibo Based on User Feature Extraction
[J].
基于D-S证据理论的电子商务虚假评论者检测
[J].
Detecting E-Commerce Review Spammer Based on D-S Evidence Theory
[J].
基于情感特征和用户关系的虚假评论者的识别
[J].
Spotting Fake Reviewers Based on Sentiment Features and Users’ Relationship
[J].
Discovering Opinion Spammer Groups by Network Footprints
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}