




1 引言
在线评论是用户生成内容的重要组成部分,广泛存在于电子商务、在线旅游、本地生活等各类互联网平台上。在线评论中包含着大量的消费者关于产品与服务的观点,在实际应用中,识别这些观点的原因具有重要的实践意义[1]。一方面,商家可以从消费者对产品与服务的评论中获得反馈信息来进行改进和创新,从而在市场中赢得竞争优势;另一方面,消费者可以从评论中获得更多产品与服务细节的信息,从而更好地进行消费决策。然而,评论文本的非结构化使得人工处理海量的评论变得十分困难,因此观点挖掘(也被称为情感分析或评论挖掘)技术受到学界与工业界的广泛关注。
针对文本分类和评论信息抽取方法存在的不足,本文提出了一个基于酒店领域预训练语言模型的观点原因句分类方法。在预训练语言模型ERNIE(Enhanced Representation Through Knowledge Integration)[5]自有预训练数据集的基础上增加一个额外的酒店领域语料库,使用Devlin等[6]提出的多阶段知识掩码策略的掩码语言模型(Mask Language Model,MLM)和融合情感知识的下一句预测(Next Sentence Prediction,NSP)在预训练语料上提取文本特征,使模型熟悉酒店领域的“行话”,然后利用BiLSTM模型融合所有特征并识别包含观点原因的评论。
2 文献综述
2.1 无监督评论信息抽取
无监督的评论信息抽取方法一般基于规则或主题模型。基于规则的方法主要是利用文本的句法、语法信息和相关词库来挖掘评论中符合一定规则的词作为方面词或情感词。Hu等[7]利用关联规则抽取评论中高频出现的名词和名词短语作为方面,抽取接近这些方面的形容词作为情感词。Qiu等[8]提出一种双重传播方法,利用情感词和方面之间的句法关系以及情感词和方面本身来抽取新的情感词。Lakkaraju等[9]首次利用句法和语义相关性从评论中抽取方面和情感词。Li等[10]利用PMI-IR(Pointwise Mutual Information-Information Retrieval)增强基于频率的方法,通过网络搜索度量候选方面与目标实体的语义相似性,同时扩展了RCut(Rank-Based Thresholding)方法用于学习候选方面的阈值。周清清等[11]针对传统的基于频率的抽取方法会遗漏较多方面的问题,提出一种基于词向量的聚类方法,该方法通过高频名词筛选出种子方面,然后应用深度学习方法得到词向量并基于词向量聚类发现更多方面。
主题模型考虑上下文语义之间的关系,对文档中隐含的主题进行建模。基于主题模型的方法无需依赖人工制定的语言规则,能发现文本中的登录词。Andrzejewski等[12]提出的DF-LDA(Dirichlet Forest Prior in a Latent Dirichlet Allocation)模型在LDA(Latent Dirichlet Allocation)框架中使用了一种新的狄利克雷森林先验整合领域知识,相对于经典的LDA方法,该模型能识别更多方面。Lin等[13]提出一种新的基于LDA的概率模型框架JST(Joint Sentiment-Topic),该模型可以从文本中同时识别方面与情感词。Luo等[14]针对以往研究很少考虑实体和评级的问题,提出一个四元的PLSA(Probability Latent Semantic Analysis)从评论中抽取特征词。
2.2 有监督评论信息抽取
基于机器学习和深度学习的信息抽取方法一般是在隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)模型上做变化,其过程可以视为一个序列标注任务。Jin等[15]提出一种基于词汇化HMM提取方面和情感词的机器学习框架,将词性、上下文等语言特征整合到HMM中进行自动学习。Li等[16]提出一个具有两个LSTM(Long Short-Term Memory)的方面抽取框架,其中两个LSTM可以进行交互学习,使得模型具有扩展记忆与神经记忆。Wu等[17]提出一种混合无监督方法来抽取方面,使用语言规则提取名词短语块并将其作为候选方面,将这些带有候选方面的文本用作伪标注数据来训练一个GRU(Gated Recurrent Unit)网络以进行方面抽取。Yu等[18]提出一个用于方面与情感词的联合抽取方法,该方法通过一个多任务神经网络隐式地学习方面与情感词之间的关系,同时通过一个全局推理方法显式地建模方面与情感词的句法约束。深度学习方法普遍能取得比其他方法更好的效果,但也需要大量的标注数据进行训练,人工成本高。
目前最新的文本分类和信息抽取方法是基于预训练语言模型的方法,它能通过预训练加微调的方式克服一词多义的问题,输出更适合上下文的表示,有效提升模型效果。Devlin等[6]提出的BERT(Bidirectional Encoder Representations from Transformers)含MLM和NSP两个预训练任务,通过这两个任务在大规模语料上预训练学习语言知识并应用于特定的下游任务,克服了Word2Vec[19]方法在产生词向量时未考虑上下文的问题,解决了不同语境下词的歧义问题。另外,不同于ELMo(Embedding Language Model)[20]仅为下游任务提供训练好的固定词向量而无法改变网络参数,BERT的参数可以在进行下游任务时微调,实验表明其微调的方式非常有效,BERT在多项自然语言处理任务上都取得了非常好的效果[21⇓-23]。但BERT的预训练仅根据上下文去预测词的信息,缺乏对更大语义单元的建模,这个问题在中文领域更加明显。针对BERT的不足,Sun等[5]提出的ERNIE能通过多阶段知识掩码策略学习海量语料中实体和短语级的先验知识,相比于BERT对文本中的原始语言信号进行建模,ERNIE对整个语义知识单元进行建模,增强了对语言的表示能力。此外,ERNIE引入了多源数据知识,利用对话反应损失(Dialogue Response Loss)学习对话的隐式关系,通过学习判断多轮对话的真实性进一步增强了模型的语义表示能力。然而,ERNIE的自有预训练语料不具有针对性,在做不同领域的文本分析任务时泛化能力不够,因此本文针对酒店领域的在线评论,提出DERNIE模型,通过额外的预训练语料使模型学习到酒店领域的知识,更好地提取特征。
3 基于两个预训练任务的观点原因识别模型
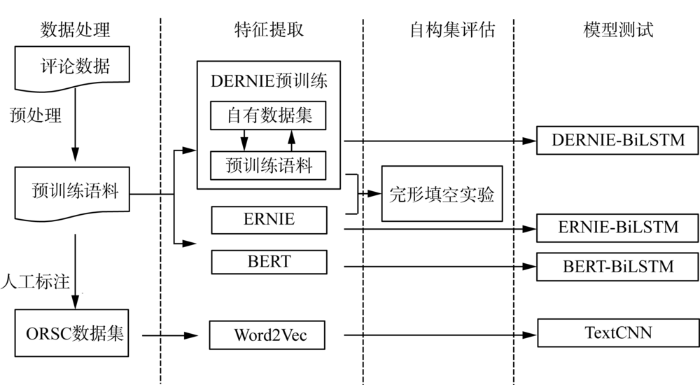
本文的目的是基于ERNIE模型,在ERNIE自有的预训练语料库基础上额外增加酒店领域的训练语料,使用多阶段知识掩码MLM和融合情感知识的NSP两个预训练任务对酒店在线评论经过预训练提取特征,并通过完形填空实验证明自构预训练语料对文本特征提取的有效性。将基于酒店领域的ERNIE预训练模型记为DERNIE,在此基础上,根据观点原因句分类(Opinion Reason Sentence Classification,ORSC)任务的特点提出基于酒店领域的评论观点原因识别模型(DERNIE-BiLSTM),并且通过人工标注的方式构建ORSC数据集。此外,本文也考虑了经典深度学习方法,并基于ORSC数据集使用多个预训练模型提取特征构造分类方法。本文的总体设计如图1所示,目的是通过对比DERNIE-BiLSTM与TextCNN[24]、BERT-BiLSTM和ERNIE-BiLSTM的观点原因句识别结果来分析各模型的好坏。
图1
3.1 ERNIE模型
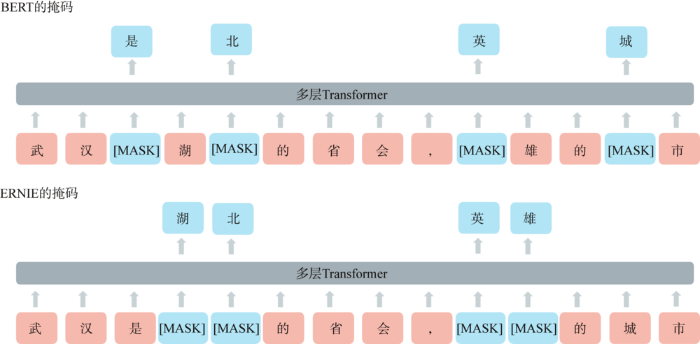
相比于BERT对文本中的原始语言信号进行建模,ERNIE能通过多阶段知识掩码策略学习海量语料中实体和短语级的先验知识,从而对更大语义单元建模,增强其语言表示能力。本文以中文句子为例,设计了BERT和ERNIE掩码策略的对比图,如图2所示,BERT通过“武”、“汉”、“湖”、“的”等字的局部共现,可以判断出被掩盖的“北”字,但在这个过程中模型没有学习到更大语义单元的“武汉”、“湖北”相关的知识。而ERNIE通过掩盖文本中的实体和词语能隐式地学习到“武汉”、“湖北”、“英雄”等词的语义以及它们之间的相关关系。此外,ERNIE本身的输入还是基于字的,这使得模型的使用不需要依赖其他词法工具。
图2
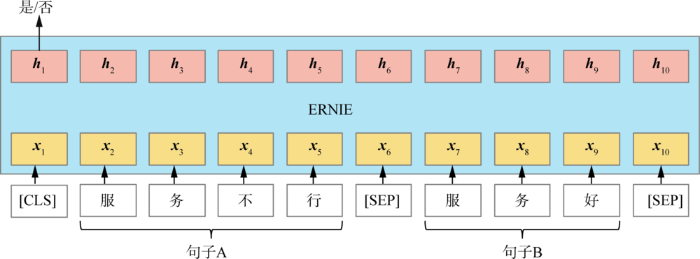
多阶段的知识掩码策略无法对整句话很好地建模,而本文构建的文本分类任务需要获得整句话的语义表示来分类。因此需要进行NSP任务,本文设计的NSP过程如图3所示,模型输入的两个句子有50%的可能性是一段评论中连续的两个句子(正例样本),有50%的可能性是来自不同评论的两个句子(负例样本)。在预训练中,模型需要预测输入的两个句子是否连续。由于评论文本并没有严格的上下文关系,仅让模型判断两句评论是否连续有一定的难度,因此本文在预训练选择负例样本时的选择策略是:以一定的概率选择不同情感倾向的两个句子。例如将“酒店服务人员态度很好,准时接送机。”和“服务员不行,爱答不理。”两句评论组成一个负例,让模型判断这两个句子的情感是否一致。这更有利于模型的收敛,同时也让模型隐式地学习了评论中的情感知识,使模型能更好地处理评论相关的任务。
图3
3.2 基于DERNIE模型的特征提取
图4
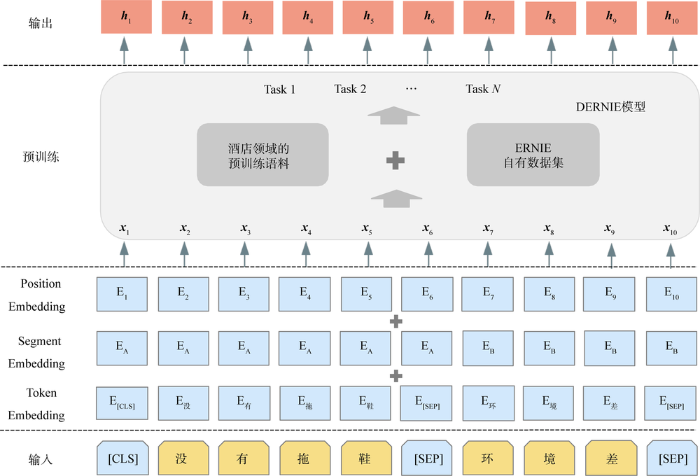
对于给定输入文本序列
3.3 BiLSTM模型
对于序列数据,循环神经网络(Recurrent Neural Network,RNN)是一个经典的模型,但其由于梯度消失和梯度爆炸问题无法学习到序列中的长期依赖,因此在自然语言处理任务中常使用的是LSTM模型。与RNN类似,LSTM模型在每一步都接受上一步的输出作为输入,通过记忆单元和门的结构存储长期依赖信息,改善了RNN中存在的长期依赖问题。
图5
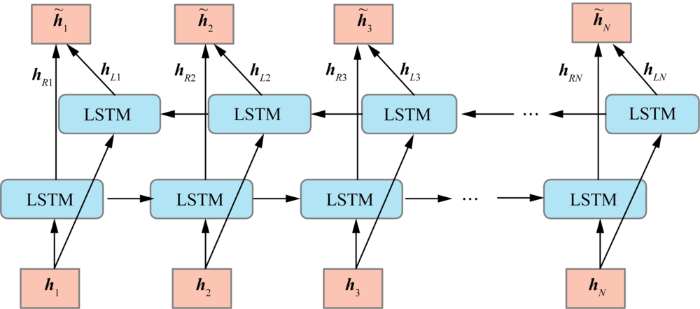
3.4 DERNIE-BiLSTM的观点原因句分类模型
尽管DERNIE能通过预训练语料获得酒店评论的先验语言知识,但直接用于分类会使模型无法充分利用评论中的观点原因片段信息,例如在“没有拖鞋环境差”这句评论中,“没有拖鞋”这个观点原因片段直接决定了该句评论应该被分类为观点原因句,但模型中特殊标记“[CLS]”的表示中没有针对性地对该片段进行建模,因此需要使用BiLSTM模型融合DERNIE输出的所有特征。
DERNIE-BiLSTM模型结构如图6所示,对于给定的输入序列
图6
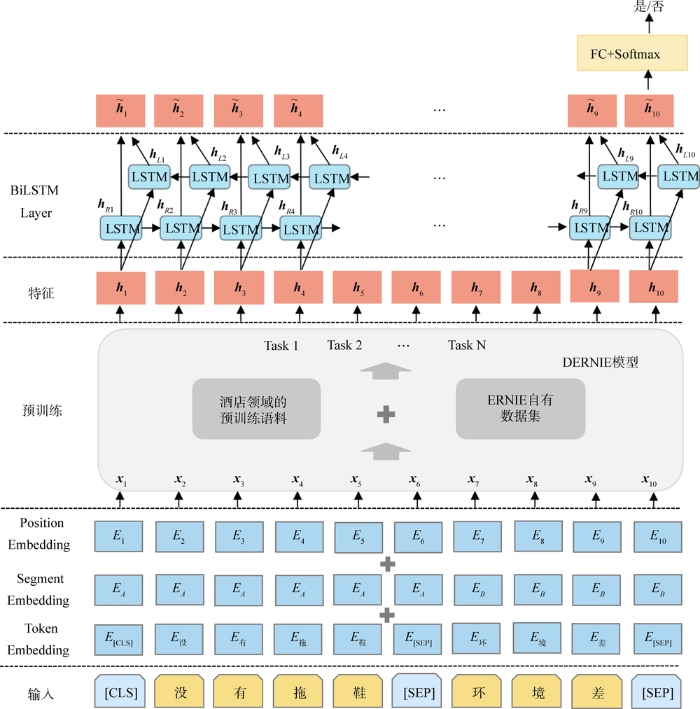
经过BiLSTM模型的序列化处理后,
其中,
其中,
DERNIE-BiLSTM的训练和超参数调优过程如算法1所示。在每个回合(epoch)中,将训练数据拆分为若干个批次尺寸(batch_size),每次将一个batch_size的数据传入模型进行训练,在训练的每一个步数(step)中,首先通过领域ERNIE-BiLSTM模型的前向传播得到损失值,然后通过模型的反向传播得到所有参数的梯度值,最后根据梯度值更新模型的所有参数。
算法1: DERNIE-BiLSTM的训练过程
① for each epoch do
② for each batch_size do
③ 1) DERNIE model forward pass
④ 2) BiLSTM layer forward pass
⑤ 3) calculate the loss
⑥ 4) BiLSTM layer backward pass
⑦ 5) DERNIE model backward pass
⑧ 6) update parameters
⑨ end for
⑩ end for
4 实验与分析
4.1 实验数据与预处理
从酒店在线预订平台携程旅行网上抓取包括武汉、北京、成都、杭州等在内的多个城市的三星级及以下酒店在线评论数据。这个星级区间的酒店和在线评论相对较多,正负面评论分布相对均衡,样本丰富度高。每个数据样本包含用户ID、评分、评论文本等字段,总计抓取2 148 386条评论。本文对原始评论数据预处理的步骤包括:删除不包含汉字的评论和特殊字符;规范化句子中的换行符、空格与标点符号;将句子中的英文转化为小写,汉字转化为简体;去重;样本均衡化处理。预处理完成后得到1 016 410条评论。基于ERNIE模型,通过对预处理后的酒店评论语料进行两个预训练任务来提取文本特征,使模型习得酒店领域的知识。
ORSC是一个新任务,没有相关的公开数据集,因此本文构建了一个ORSC数据集来验证所提出的DERNIE-BiLSTM模型。从预处理后的酒店预训练语料中筛选并人工标注了7 000条评论,其中包括3 500条包含观点原因的评论和3 500条不包含观点原因的评论,部分标注数据如表1所示。针对ORSC任务,由于不包含观点原因的句子相对较短,包含观点原因的句子通常较长,为避免模型可能会根据句子长短来判断是否包括观点原因,本文构建数据集的句子长度都在64个字符及以下。考虑到ORSC数据集的数量分布均衡,以7∶3划分训练集和测试集,通过在测试集上的预测结果对比评价各模型的表现。
表1 ORSC数据集示例
Table 1
| 类别 | 评论 |
|---|---|
| 观点 原因句 | 1.服务人员未经同意擅自进入房间。 2.房间实在太小,二个人都无法并排走 3.无窗,面积很小,非常潮湿闷气,空调的水都是用大 矿泉水瓶接的厕所无完整隔断,导致房内更加潮湿。 但总体来说,住了一夜没有耽误行程,已经很ok了。 |
| 非观点 原因句 | 1.综合条件太差 2.帮朋友订的,不知道怎么样 3.楼下是洗浴,楼上不知道是什么,两三点钟的时候好多脚步声,上楼下楼的,严重影响休息。体验很差! |
4.2 实验设计
在两个预训练任务中,将MLM任务的损失记为
算法2: DERNIE的参数调优过程
① for each batch_size do
② 1) DERNIE model forward pass
③ 2) calculate the total loss
④ 3) DERNIE model backward pass
⑤ 4) update parameters
⑥ end for
为验证本文提出的观点原因句分类模型的有效性,选择以下方法进行对比实验:TextCNN、DERNIE、BERT-BiLSTM、ERNIE-BiLSTM、DERNIE-BiLSTM。其中,TextCNN通过将词向量拼接形成矩阵,然后在词的方向上进行1维卷积提取文本的局部特征,并将特征合并来进行分类;DERNIE没有使用BiLSTM模型进行特征融合,用第一个特殊标记“[CLS]”的隐藏层状态进行分类;BERT-BiLSTM使用BERT提取文本特征,通过BiLSTM模型融合特征来分类。ERNIE-BiLSTM使用ERNIE提取文本特征,通过BiLSTM模型融合特征来分类;DERNIE-BiLSTM先用酒店领域预训练语言模型DERNIE提取文本特征,然后使用BiLSTM模型融合特征输出分类结果。应用了预训练语言模型ERNIE或者BERT的方法不需要单独训练字向量,但TextCNN需要提前预训练的字向量来提升模型效果,因此使用经过预处理后的酒店评论语料作为训练字向量的语料,利用Word2Vec中的Skip-gram模型训练字向量。本文最终确定的超参数均是对应的方法在测试集上表现最佳的超参数,具体情况如表2所示。
表2 ORSC实验超参数设置
Table 2
| 超参数 | TextCNN | DERNIE | BERT-BiLSTM | ERNIE-BiLSTM | DERNIE-BiLSTM |
|---|---|---|---|---|---|
| character embedding dimensions | 100 | 768 | 768 | 768 | 768 |
| hidden dimensions | 100 | 768 | 768 | 768 | 768 |
| max sequence length | 64 | 64 | 64 | 64 | 64 |
| batch_size | 32 | 16 | 32 | 32 | 32 |
| learning rate | 1e-3 | 3e-5 | 5e-5 | 3e-5 | 5e-5 |
| epochs | 6 | 11 | 7 | 13 | 20 |
| dropout | 0.5 | 0.1 | 0.1 | 0.1 | 0.1 |
4.3 评价指标
本文目标是识别ORSC数据集中的观点原因句,本质上是二分类任务,因此使用分类指标准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值作为实验的评估指标,计算方法如公式(3)-公式(6)所示。
其中,TP(True Positive)表示将正例预测为正例的个数,TN(True Negative)表示将负例预测为负例的个数,FP(False Positive)表示将负例预测为正例的个数,FN(False Negative)表示将正例预测为负例的个数。
4.4 实验结果与分析
(1) 预训练任务的结果与分析
DERNIE预训练期间总损失
图7
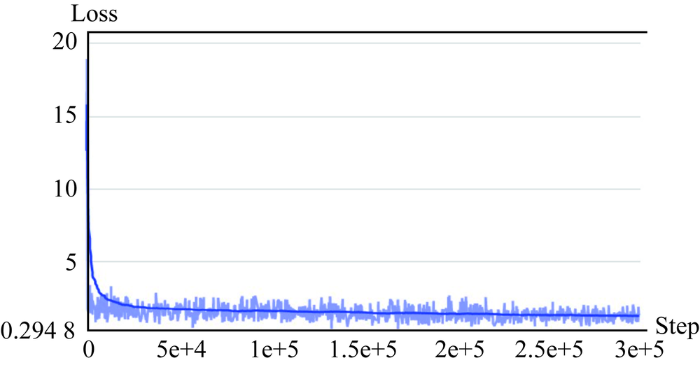
为验证预训练任务是否使DERNIE具备了酒店评论领域的知识,证明所抓取语料库的有效性,进行完形填空[25]实验,掩盖评论样本中的某个词,使用模型预测被掩盖的词。同时对比了三种语言模型在完形填空实验上的表现,其中BERT是谷歌官方预训练的中文模型,预训练语料来自维基百科,预训练任务为MLM和NSP;ERNIE是百度官方预训练的中文模型,预训练任务包括多阶段知识掩码MLM、NSP和DLM;本文提出的DERNIE在百度官方模型的基础上,使用酒店评论语料进行多阶段知识掩码MLM和融合情感知识的NSP预训练,使模型习得酒店领域的知识。
完形填空的部分预测结果如表3所示。在例1中,BERT的预测结果不是一个正确的词,因为基于字的预训练方式导致BERT学习到的词级知识比较少,无法正确预测。相对而言,ERNIE具备更多词级的知识,预测出来的是一个完整的词,这证明了多阶段知识掩码策略的有效性,但ERNIE预测出来的词与酒店领域没有关系。DERNIE的预测结果则比较合适,“服务态度”是酒店领域的常用词,这表明DERNIE已经具备了一定的领域知识,基于酒店领域预训练是有效的。例2和例3类似,BERT和ERNIE预测出的词与酒店相关性比较小,而DERNIE预测出来的都是酒店领域的常用词。从例4和例5中可以看到,DERNIE不仅能准确预测出酒店的方面词,对于酒店评论中常见的情感词“一般”和观点原因“离火车站近”也能准确预测。完形填空的实验证明了在酒店领域的知识推理方面,预训练后的模型DERNIE表现比ERNIE好,这侧面证明了本文爬取的酒店领域训练语料是有效的。
表3 完形填空实验结果
Table 3
| 例子 | 样本 | BERT预测 | ERNIE预测 | DERNIE预测 |
|---|---|---|---|---|
| 1 | 很好,主动给我们介绍附近的景点。 | 服台人务 | 朋友关系 | 服务态度 |
| 2 | 卫生差, 有小虫子咬得却都是疱 | 虽然 | 虽使 | 床上 |
| 3 | 极差,住的人三六九等,半夜被吵醒多次 | 睡眠 | 环境 | 隔音 |
| 4 | 硬件设施,和其他酒店差距有点大! | 不般 | 方面 | 一般 |
| 5 | 位置就是离 近,卫生很差 | 酒店很 | 学校很 | 火车站 |
(2) DERNIE-BiLSTM的结果与分析
本文采用的5种观点原因句识别模型在测试数据集上的表现如表4所示。DERNIE-BiLSTM分类模型在各个指标上的结果均高于94%,优于其他模型。整体来看,应用了预训练语言模型的方法效果都要好于经典的深度学习方法TextCNN,因为预训练语言模型能学习大量的先验语言知识。预训练语言模型输出的字向量是上下文相关的,能够根据每个字的上下文编码字的语义,而传统的Word2Vec方法得到的词向量是上下文无关的,不能应对一词多义的情况,所以基于预训练语言模型提取的文本特征能达到更好的分类效果。DERNIE-BiLSTM的分类准确率和F1值均高于单独应用DERNIE做分类,因为DERNIE仅用第一个特殊标记“[CLS]”的隐藏层状态进行分类,DERNIE-BiLSTM则能通过BiLSTM模型融合DERNIE输出的所有特征,更好地捕获到评论句子中的观点原因片段信息。
表4 ORSC实验结果
Table 4
| 方法 | Accuracy (%) | Precision (%) | Recall (%) | F1-score (%) |
|---|---|---|---|---|
| TextCNN | 90.81 | 90.64 | 91.07 | 90.86 |
| DERNIE | 91.33 | 92.91 | 89.55 | 91.20 |
| BERT-BiLSTM | 92.57 | 92.27 | 92.97 | 92.62 |
| ERNIE-BiLSTM | 94.10 | 93.86 | 94.40 | 94.13 |
| DERNIE-BiLSTM | 94.57 | 94.00 | 95.25 | 94.62 |
BERT-BiLSTM、ERNIE-BiLSTM和DERNIE-BiLSTM具有相同的网络结构,不同的是它们采用不同的预训练语言模型提取文本特征,应用了ERNIE的预训练模型分类准确率和F1值都高于BERT,因为ERNIE在预训练阶段采用多阶段知识掩码MLM,因此相较于BERT基于中文汉字进行预训练的方式,ERNIE能够进一步建模中文词语和实体的语义与关系,对于中文文本的表示能力更强。相比于ERNIE-BiLSTM,DERNIE-BiLSTM取得了更好的效果,这是因为经过基于酒店领域数据的预训练,模型学习到了更多酒店领域的知识,熟悉了特定的语言环境,能更好地提取特征,这也证明了本文自构数据集的有效性。
5 结语
在线评论是用户生成内容的重要组成部分,对于商家和消费者都有十分重要的意义。为了从海量评论中有效地识别出观点原因,本文在携程旅行网上抓取了两百多万条在线评论,经过预处理后构造预训练语料,并通过人工标注构建了一个ORSC训练语料库。基于此,本文提出一个评论中的观点原因识别模型,针对目前文本分类和评论信息抽取方法存在的不足,引入ERNIE作为基础语言模型,在预训练语料上进行了两个预训练任务来提取特征,并通过完形填空对比实验证明了两个预训练任务的有效性。使用BiLSTM模型融合特征输出分类结果,通过多种方法的对比,验证了模型的有效性。
现有研究一般将重点放在对评论中方面的抽取以及方面情感分类上,一定程度上忽略了评论中更有价值的观点原因信息。本文设计的DERNIE-BiLSTM分类模型利用酒店领域的评论数据来习得相关领域的语言背景,在观点原因句识别上具有更高的精度。DERNIE-BiLSTM是基于深度学习的模型,对不同领域的分类任务具有通用性。然而,基于领域数据预训练语言模型对语料库数据量有一定的要求,本文爬取了百万级数据量的预训练语料,这对计算速度和效率会产生一定的影响,未来将研究模型蒸馏等方法减小模型的参数量,提高运算效率。
作者贡献声明
张治鹏:提出研究思路,设计研究方案,进行实验,起草论文;
毛煜升:采集、清洗和分析数据;
张李义:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
[1] 张治鹏. 观点原因句分类数据集. DOI:10.57760/sciencedb.j00133.00012.
[2] 张治鹏. 酒店领域的预训练语料. DOI:10.57760/sciencedb.j00133.00012.
参考文献
Sentiment Analysis Based on Clustering: A Framework in Improving Accuracy and Recognizing Neutral Opinions
[J].DOI:10.1007/s10489-013-0463-3 URL [本文引用: 1]
Extracting Aspects and Mining Opinions in Product Reviews Using Supervised Learning Algorithm
[C]//
Deep Learning Model for Fine-Grained Aspect-Based Opinion Mining
[J].DOI:10.1109/ACCESS.2020.3008824 URL [本文引用: 1]
用于方面提取的软原型增强自适应损失模型
[J].
Soft Prototype Enhanced Adaptive Loss Model for Aspect Extraction
[J].
ERNIE: Enhanced Representation Through Knowledge Integration
[OL].
BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
[OL].
Mining and Summarizing Customer Reviews
[C]//
Expanding Domain Sentiment Lexicon Through Double Propagation
[C]//
Exploiting Coherence for the Simultaneous Discovery of Latent Facets and Associated Sentiments
[C]//
Improving Aspect Extraction by Augmenting a Frequency-Based Method with Web-Based Similarity Measures
[J].DOI:10.1016/j.ipm.2014.08.005 URL [本文引用: 1]
在线用户评论细粒度属性抽取
[J].
Fine-Grained Aspect Extraction from Online Customer Reviews
[J].
Incorporating Domain Knowledge into Topic Modeling via Dirichlet Forest Priors
[C]//
Weakly Supervised Joint Sentiment-Topic Detection from Text
[J].DOI:10.1109/TKDE.2011.48 URL [本文引用: 1]
QPLSA: Utilizing Quad-Tuples for Aspect Identification and Rating
[J].DOI:10.1016/j.ipm.2014.08.004 URL [本文引用: 1]
A Novel Lexicalized HMM-Based Learning Framework for Web Opinion Mining
[C]//
Deep Multi-Task Learning for Aspect Term Extraction with Memory Interaction
[C]//
A Hybrid Unsupervised Method for Aspect Term and Opinion Target Extraction
[J].DOI:10.1016/j.knosys.2018.01.019 URL [本文引用: 1]
Global Inference for Aspect and Opinion Terms Co-Extraction Based on Multi-Task Neural Networks
[J].DOI:10.1109/TASLP.2018.2875170 URL [本文引用: 1]
Deep Contextualized Word Representations
[OL].
BERT for Joint Intent Classification and Slot Filling
[OL].
Chinese Clinical Named Entity Recognition with Variant Neural Structures Based on BERT Methods
[J].DOI:10.1016/j.jbi.2020.103422 URL [本文引用: 1]
A Text Abstraction Summary Model Based on BERT Word Embedding and Reinforcement Learning
[J].DOI:10.3390/app9214701 URL [本文引用: 1]
Combining Fine-Tuning with a Feature-Based Approach for Aspect Extraction on Reviews
[C]//
Convolutional Neural Networks for Sentence Classification
[OL].
“Cloze Procedure”: A New Tool for Measuring Readability
[J].DOI:10.1177/107769905303000401 URL [本文引用: 2]
Attention is All You Need
[C]//
Long Short-Term Memory
[J].
Learning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow. We briefly review Hochreiter's (1991) analysis of this problem, then address it by introducing a novel, efficient, gradient-based method called long short-term memory (LSTM). Truncating the gradient where this does not do harm, LSTM can learn to bridge minimal time lags in excess of 1000 discrete-time steps by enforcing constant error flow through constant error carousels within special units. Multiplicative gate units learn to open and close access to the constant error flow. LSTM is local in space and time; its computational complexity per time step and weight is O(1). Our experiments with artificial data involve local, distributed, real-valued, and noisy pattern representations. In comparisons with real-time recurrent learning, back propagation through time, recurrent cascade correlation, Elman nets, and neural sequence chunking, LSTM leads to many more successful runs, and learns much faster. LSTM also solves complex, artificial long-time-lag tasks that have never been solved by previous recurrent network algorithms.
Bidirectional LSTM-CRF Models for Sequence Tagging
[OL].
Mixed Precision Training
[OL].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}