




1 引言
随着市场竞争日益激烈,企业越来越重视对用户消费需求、尤其是差异化的精细需求的分析和挖掘[1]。
分析用户需求时,问卷调研等传统方法由于成本高、周期长,难以满足企业的要求[2⇓-4]。随着电子商务的蓬勃发展,如何从用户的在线评论中挖掘需求,成为热点问题[5-6]。研究者常采用关键词提取算法提取评论中的产品特征,典型算法有隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型[7]、词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)[8]和TextRank[9]等;也有研究者进一步结合情感词典分析用户对于产品特征的情感倾向,进而分析用户的消费需求[5,10⇓⇓⇓-14]。这类方法能够快速、低成本地处理大规模用户评论,但仍面临以下问题。
(1)关键词提取算法适用于提取评论中的高频词语,而词频不突出的特征容易被忽略。在产品同质化现象突出的今天,提取评论中相对低频的有效特征信息对于差异化产品分析同样具有重要意义。
(3)在线评论常包含错别字,往往会影响分词算法效果。以“超级快充”为例,用户发表评论时可能错打成“超级快冲”,对此使用Jieba分词会将“超级快冲”分为“超级”“快”“冲”,这三个词与充电均毫无关联,导致用户在充电方面的需求被忽略。
针对以上问题,本文选择将方面词引入需求挖掘领域,并与BERT(Bidirectional Encoder Representation from Transformers)结合,提出一种方面级的评论特征提取模型——语境窗口自注意力(Context Window Self-Attention,CWSA)模型。按照国际语义评测大会SemEval 2014给出的定义,方面是指观点评论的实体的具体属性,方面词(或称为方面术语)则是评论中表述方面的词语序列[18],如评论“电池容量够大,立体声扬声器很给力”中的“电池容量”和“立体声扬声器”。与关键词不同,方面词的定义与词语出现的频率无关,也不依赖于是否在文本中扮演关键角色。相比于聚焦高频产品特征的关键词提取算法,方面词提取模型的引入,可以通过提取相对低频的有效特征信息为细粒度的差异化分析提供更好的支持。为了避免分词不准确带来的影响,CWSA模型依据序列标注思想,构造语境窗口自注意力机制来增强模型理解文本的能力。与当前主要的方面词提取算法不同的是,CWSA模型能够着重分析语境窗口内以及邻近文本的特征,弱化不相关文本的负面干扰。在此基础上,使用方面级情感分析模型判断用户的情感倾向,从而提供用户需求的差异化精细分析。本文的主要贡献如下。
(1)提出一种语境窗口自注意力机制,并基于此构造了与BERT模型[19]相结合的CWSA模型。CWSA模型能够在把握文本整体信息的基础上,聚焦语境窗口内以及邻近文本的语义,并在本文构造的方面词标注数据集上获得了较好的实验结果。
(2)在京东手机评论数据集上应用了CWSA模型,并结合方面级情感分析模型挖掘评论中隐藏的用户需求。结果表明,本文以方面词而非关键词为切入点进行需求挖掘,能够支持细粒度的差异化分析,兼顾高频与相对低频的有效信息,同时可以妥善处理评论中的错别字、繁体字带来的负面干扰。
(3) 基于京东在线手机评论,采用序列标注的方式,构造了方面词提取以及方面级情感分析中文数据集①(https://github.com/YuhanXiaoJY/jingdong-phone-dataset-for-aspect-extraction-and-aspect-based-sentiment-analysis.),有助于解决方面词提取与方面级情感分析中文数据集较为匮乏的问题。
2 相关工作
2.1 用户需求挖掘方法
用户需求挖掘方法可以分为两大类:基于问卷调研的传统需求获取方法以及基于文本挖掘算法的自动化需求提取方法。
这两类方法有着不同的适用场景。在数据量不大、人工成本可控的情况下,传统需求获取方法有着不俗的表现[4]。但在数据量激增的信息时代,基于文本挖掘算法的自动化需求提取方法应用更为广泛。Zhang等[10]使用基于词性标注的无监督方法进行高频产品特征提取,自定义种子词集并结合WordNet进行情感分析,最终构造产品再设计指数衡量用户对各类产品特征的待改进需求。Lai等[11]使用TF-IDF的改进方法——特征频率-逆产品频率(Feature Frequency-Inverse Product Frequency,FF-IPF)提取高频关键词作为产品特征,在种子词集的基础上使用Word2Vec[20-21]扩充情感词典,借助图论分析用户的潜在需求。李贺等[12]利用LDA模型对在线手机评论进行评论主题及产品特征挖掘,提取用户需求要素后基于Kano模型设置用户需求调查问卷,最后根据用户满意度提出企业产品管理的优化策略。
国内外学者提出的方法中,产品特征提取与情感分析均处于核心位置,两者的效果对用户需求的挖掘具有重要影响。
2.2 产品特征提取方法
(1) 关键词提取算法
(2) 方面词提取算法
相较于关键词提取算法,近年发展迅速的方面词提取算法在捕捉低频、细粒度的产品特征上具有优势。Liu等[23]基于循环神经网络(Recurrent Neural Network,RNN)提出了一系列方面词判别模型,该系列模型不依赖于特征工程的建立,且结果优于条件随机场等传统机器学习方法。Ma等[24]提出用于方面词提取的序列到序列模型(Sequence-to-Sequence for Aspect Term Extraction,Seq2Seq4ATE),探索了序列到序列学习技术[25]在方面词提取任务中的应用方式,并结合注意力机制设计,获得了较好的实验结果。Yang等[26]则充分利用BERT预训练语言模型的语义表示能力,提出用于方面词提取和情感分析的局部语境聚焦模型(Local Context Focus for Aspect Term Extraction and Polarity Classification,LCF-ATEPC),在多个中英文数据集上取得了优异的成绩。
与关键词提取技术相比,方面词提取技术的发展时间相对较短,优质的方面词中文语料库也较为匮乏[17]。这使得方面词提取技术在需求挖掘领域的应用还不广泛,尤其是与深度学习相结合的方面词提取算法。
2.3 情感分析方法
情感分析方法按粒度可分为文档级、句子级和方面级三大类[27]。在面向评论文本的用户需求挖掘任务中,为了尽可能捕捉用户的具体需求,侧重于提取细粒度情感信息的方面级情感分析算法得到广泛的应用。
方面级情感分析的目的是对实体的若干方面,提取出针对每个方面的情感极性[28]。常用的方法有语言规则、传统机器学习和深度学习等。语言规则类方法一般以情感词典为基础,如Nguyen等[29]基于词典与树的内核识别方面和观点的联系,Lipenkova[30]预建立词典并提出一种与通用语言规则结合的情感算法。传统机器学习方法则需要借助特征工程的构建,Kiritchenko等[31]在特征工程的基础上使用支持向量机获得了优秀的方面级情感判断结果。深度学习技术的发展,更是将方面级情感分析任务的研究向前推进了一大步。Ma等[32]在互动注意力网络(Interactive Attention Networks,IAN)模型中首次提出了语境特征和方面词特征之间的互动式学习,使模型能够重点考虑语境中的情感有效项信息。Song等[33]探索了BERT在方面词情感分析任务中的优势,提出了带有BERT的注意力编码网络(Attentional Encoder Network with BERT,AEN-BERT),其效果超过绝大多数不带预训练语言模型的方法。肖宇晗等[27]提出了基于BERT的双特征嵌套注意力模型(Dual Features Attention-Over-Attention with BERT,DFAOA-BERT),该模型将嵌套注意力(Attention-Over-Attention,AOA)与BERT结合,分别抽取全局和局部语义特征,在方面级情感分析领域的多个公开英文数据集上获得了优秀的实验结果。
3 方法介绍
3.1 方法框架
本文提出一种基于方面词的差异化与精细化用户评论分析方法,分为模型训练和需求分析两个主要任务,如图1所示。为避免传统分词方法带来的一系列问题,本文不使用分词工具对文本进行预处理,而将方面词提取任务转化为序列标注任务。为了解决方面词模型和情感模型训练的数据集问题,抽取一定数量的数据进行标注,建立训练集和测试集;然后对提出的CWSA方面词提取模型进行训练,并对适用于方面级情感分析的DFAOA-BERT模型进行训练,使之适用于当前产品评论数据。在分析阶段,直接以经过数据清洗的用户评论作为输入,利用训练好的CWSA模型与DFAOA-BERT模型分别提取方面词和分析方面词的情感态度;最后基于统计方法分析用户需求。
图1
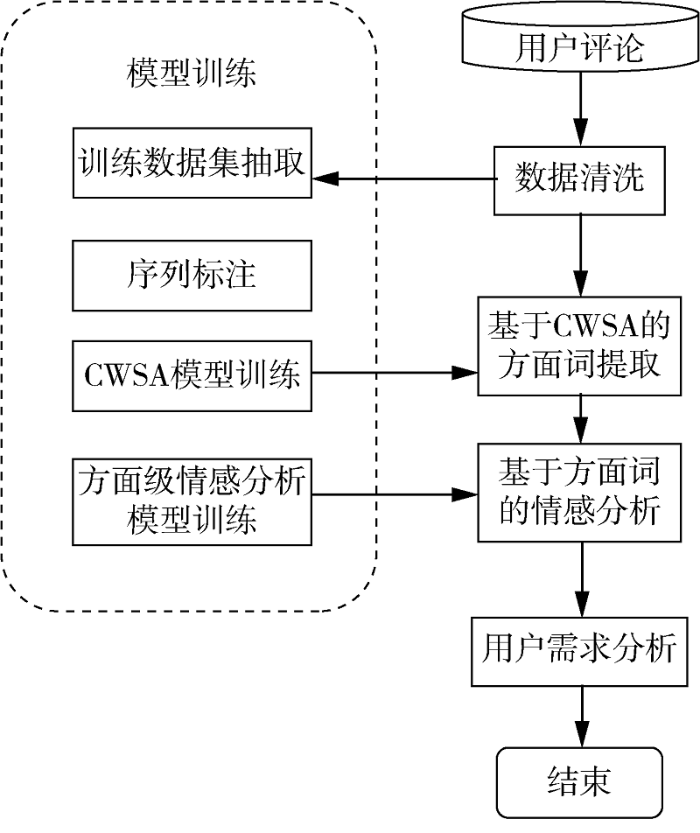
图1
基于CWSA方面词提取模型的需求挖掘方法流程
Fig.1
Flow Chart of Demand Mining Method Based on CWSA Aspect Word Extraction Model
3.2 CWSA模型
给定评论文本序列
图2
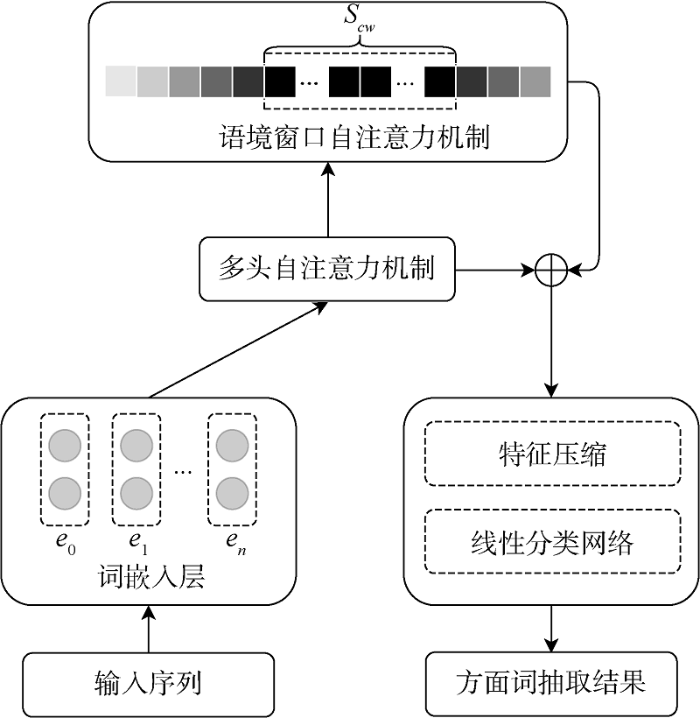
(1) 输入层
CWSA模型在该层预处理输入序列,将文本切分为单字,并处理成“[CLS]+原始输入文本序列”的格式。其中,[CLS]是与BERT相关的特殊分类向量标记符,在处理文本任务时,需要在文本序列前插入一个[CLS]符号,BERT则会将该符号对应的输出向量作为整个文本序列的语义表示。
原始输入序列在该层中被处理为文本序列
(2) 词嵌入层
使用恰当的词嵌入对输入序列进行数字化处理,能够帮助模型更好地捕捉评论文本中的语义特征。本文使用BERT词嵌入将文本序列
相较于Word2Vec和GloVe[34]等传统词嵌入模型,BERT能够生成质量更高的语义特征表示。这是因为Word2Vec等模型本质上是建立了一个词语到词向量的映射矩阵,一旦映射矩阵确定下来,在不同语境下相同的词语或字都只会有相同的对应向量。而BERT则充分运用序列到序列技术,可以根据上下文为词语动态地生成特定语境下的特征向量。尤其是在多义词频繁出现的中文领域,BERT词嵌入因其强大的上下文理解能力,能够获得比传统词嵌入更精准的数字化表示。
(3) 特征提取层
CWSA模型的特征提取层可分为两部分:用于编码词嵌入的多头自注意力机制(Multi-Head Self-Attention,MHSA)[35]以及聚焦于上下文重点信息的语境窗口自注意力机制。
①多头自注意力机制
由于词嵌入本身所描述的语义特征相对粗糙,CWSA模型在本层使用MHSA将词嵌入进一步编码,根据整体文本序列提取出丰富的语义信息,并以此作为语境窗口自注意力机制的输入向量。MHSA应用多个自注意力函数计算每个字所对应的注意力分数,综合考虑多头函数输出生成最后的语义特征表示。在这里使用与BERT较为契合的缩放点乘注意力(Scaled Dot Product Attention,SDA)作为MHSA中的自注意力机制,相较于其他常用注意力机制,SDA的计算更快速高效,同时还具有优秀的特征编码效果[36]。
SDA的计算[35]如公式(1)-公式(4)所示。
其中,
其中,
其中,
②语境窗口自注意力机制
在方面词提取任务中,对每个字的标签进行判定时,邻近语境往往比距离较远的文本具有更重要的参考价值,这是因为方面词一般会被相关修饰词语紧密包围[24]。然而,学界在设计注意力机制解决方面词提取问题时,常常忽视文本位置对序列标注结果的影响。针对以上问题,本文设计了语境窗口自注意力机制,以模型当前进行标签分类的字为中心划定语境窗口,弱化窗口以外文本的权重,聚焦窗口内重点文本的信息。
设当前考查的字为
其中,
其中,
对文本序列中的所有
对所有
(4) 分类层
在特征提取层,模型获得了表征整体文本特征的MHSA输出结果
其中,
由于BERT词嵌入的维数较大,所以先将
其中,
CWSA模型采用AdamW算法[37]进行训练优化,并选取交叉熵损失函数计算训练损失
其中,
3.3 方面级情感分析
本文采用DFAOA-BERT模型[27]获得方面级情感分析结果。
DFAOA-BERT模型的任务是对于包含方面词的文本序列和方面词序列对
4 实验结果及分析
4.1 实验数据集
本文爬取京东在售手机评论构造实验数据集,其中包括3 148条评论语句,京东购物评分(满分5分)在4分及以上的评论占60%,3分评论占15%,2分及以下的评论占25%。
为了进行方面词提取实验,也为后续的情感分析提供训练方式,采用序列标注方式,同时标注评论中的方面词以及方面词的情感倾向。标注方式如表1所示,其中第一行为评论文本,第二行为单字所对应的方面词BIO标签,第三行则为情感倾向,-2表示该字不在方面词中,-1、0、1分别表示该字在方面词中且用户对该方面词的情感态度为负面、中立、正面。
表1 数据集标注示例
Table 1
| 评论文本 | 这 | 款 | 手 | 机 | 重 | 影 | 严 | 重 | , | 待 | 机 | 时 | 间 | 还 | 不 | 错 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 标签 | O | O | O | O | B | I | O | O | O | B | I | I | I | O | O | O |
| 情感倾向 | -2 | -2 | -2 | -2 | -1 | -1 | -2 | -2 | -2 | 1 | 1 | 1 | 1 | -2 | -2 | -2 |
由于手机相关的方面词存在领域特点,本文在数据的标注过程中以方面词的定义为原则,同时咨询了手机产品专家的意见,将“老人机”“学生手机”等能够体现产品社会属性的词语视作手机领域方面词,忽略单独出现的“手机”“效果”等词频极高但不体现手机属性的名词。对于描述产品具体方面属性的复杂复合名词,将其视为一个方面词而非多个方面词的组合。例如,将“指纹解锁灵敏度”整体视为一个方面词,而非“指纹解锁”“灵敏度”两个方面词。
随后对数据集随机划分训练集和测试集,训练集有2 518条,测试集有6 30条。数据集中共有方面词6 841个,用户表达正面情感的有4 564个,表达中立情感和负面情感的分别有563和1 324个。
4.2 方面词提取实验结果
(1) 基线模型
本文选用多个基线模型进行实验结果对比,包括普通神经网络模型、神经网络与传统机器学习相结合的模型以及带有预训练语言模型的深度学习模型。
② CNN-CRF[40]:使用多层卷积神经网络(Convolutional Neural Networks,CNN)增强模型的语义理解能力并提取出方面词。
③ BiLSTM-CRF[41]:将双向长短时记忆网络与传统机器学习方法中的条件随机场相结合,常用于处理序列标注任务。
④ 协作图网络(Collaborative Graph Network,CGN)[42]:基于图神经网络的命名实体识别方法,针对中文文本存在的缺少单词边界信息的问题,构建了协作图,并结合词典知识自匹配词汇词以及最接近的上下文词汇词。
⑤BiLSTM-CNN-CRF[43]:序列标注领域表现非常优秀的模型,采用卷积神经网络和双向长短时记忆网络分别学习字符级和词语级特征,经过条件随机场后输出标注结果。
⑥ Seq2Seq4ATE[24]:充分探索了序列到序列技术在方面词提取任务中的应用,在此基础上结合基于文本位置的注意力机制对方面词做出判定。
⑦ BERT-base[26]:基础BERT模型,对其进行序列标注任务的适应性调整后应用于方面词提取任务。
⑧ BERT-BiLSTM-CRF:在BiLSTM-CRF模型的基础上引入了BERT词嵌入,并进行了领域适应性调整。该模型在命名实体识别任务上有着非常突出的效果。
⑨ LCF-ATEPC[26]:方面词提取以及方面级情感分析的多任务联合学习方法,结合了BERT预训练模型。在训练过程中,情感分析与方面词提取网络的参数形成有效交互,提升了模型在方面词提取任务上的表现。
(2) 实验参数与结果对比
CWSA模型的参数设置如下:学习率为2
对于带有预训练BERT模型的基线模型(BERT-base和LCF-ATEPC),词嵌入的选择上与CWSA模型相同,均使用Chinese-BERT-WWM;不带BERT的基线模型使用中文维基百科词嵌入[45],维度为300②(②https://github.com/Embedding/Chinese-Word-Vectors.)。学习率、dropout等其余参数均采用各基线模型原论文中给出的配置。
模型的评价指标采用F1分数,F1分数越高则说明模型的方面词提取能力越强。所有实验均在NVIDIA Tesla V100 SXM2显卡上进行。
实验结果如表2所示。不带预训练语言模型的基线模型中,BiLSTM模型表现相对一般,它通过前向和后向长短时记忆网络分别学习输入文本的上下文信息,但没有设计模块有效整合这些信息,导致方面词提取效果不突出。CNN-CRF和BiLSTM-CRF模型则在使用多层卷积神经网络或BiLSTM提取文本信息后,添加了条件随机场模块。条件随机场本身可以单独设计成一个序列标注模型,具有很强的特征融合能力,接收了上层神经网络挖掘出的语义信息后将其整合提炼,显著提升了模型的方面词提取能力。BiLSTM-CNN-CRF模型更进一步,一方面借助BiLSTM学习了字与字之间的依赖和关联,另一方面又通过卷积神经网络捕捉到待标注单字的卷积核边界内的关键信息,最后再使用条件随机场进行特征综合提取,取得了优于BiLSTM-CRF和CNN-CRF模型的表现。CGN模型构建了编码层、图注意力层、融合层和解码层等4个模块,其中,图注意力层使用三个不同的图网络帮助当前字符捕获相邻上下文的语义信息,获得了字符和语境的整体表示,在京东手机评论数据集上的表现与BiLSTM-CNN-CRF模型几乎相当,但运行速度更快。Seq2Seq4ATE模型则采用了序列到序列的思想,将输入文本视为源序列,文本所对应的BIO标签序列视为目标序列,并设计了基于位置的注意力机制,减小了标签依赖问题[46]带来的负面影响,相对于CGN和BiLSTM-CNN-CRF模型在方面词提取结果,F1分数取得1个百分点以上的提升。
表2 实验结果对比
Table 2
| 模型 | F1/% |
|---|---|
| BiLSTM | 76.46 |
| CNN-CRF | 80.59 |
| BiLSTM-CRF | 81.60 |
| CGN | 82.09 |
| BiLSTM-CNN-CRF | 82.23 |
| Seq2Seq4ATE | 83.44 |
| BERT-base | 87.99 |
| BERT-BiLSTM-CRF | 88.34 |
| LCF-ATEPC | 88.82 |
| CWSA(本文) | 89.65 |
预训练BERT模型的引入,将方面词提取方法的效果提升到新的高度。BERT-base模型通过BERT对文本进行动态编码,能够根据不同语境对同样或相似的文本进行适应性调整,获得符合当前上下文的语义表示,经过多头自注意力模块后输出相应的标注序列。这种兼顾上下文信息的语义表示是提升方面词提取效果的关键性因素。BERT-BiLSTM-CRF模型在BiLSTM-CRF模型的基础上引入BERT词嵌入并进行领域性调整后,能够学习到词语级别的特征、句法结构的特征和语境的信息特征,再通过条件随机场处理相邻标签之间的依赖关系,实验表现提升明显。LCF-ATEPC模型则在方面词领域内专门建立了方面词提取与方面级情感分析的联合学习模型。尽管方面词提取和情感分析是两个不同的任务,在目标结果上存在差异,但都依赖于模型对方面词及其邻近语境信息的把握,训练过程中的参数交互优化,能够有效提升方面词提取的效果。
CWSA模型则取得了优于所有基线方法的成绩。一方面,CWSA模型充分发挥了BERT在序列标注领域的优势,通过词嵌入层以及特征提取层中多头自注意力机制的设计,赋予了模型对文本整体信息的综合理解能力;另一方面,针对方面词提取任务设计的语境窗口自注意力机制的引入,能够使CWSA模型在把握文本综合信息的基础上,根据距离弱化不相关文本的负面干扰,聚焦于当前文本位置所在的语境窗口,从而挖掘出与方面词提取相关的重点信息。模型最后的分类层在对各模块输出的信息进行提炼整合后,使用线性网络进行标签判别,F1值达到89.65%。
4.3 方面级情感分析实验结果
在上述京东手机评论数据集上,DFAOA-BERT模型经过训练后获得了优秀的实验结果,方面词情感判断准确率为89.82%。
5 应用分析
图3
在该数据集上应用CWSA模型,获得方面词提取结果。如图4所示,对比Jieba分词结果和CWSA模型提取出的词的长度分布,基于分词的提取技术更多的是提取出长度为2的简单词语,而CWSA模型则有利于提取更多的复杂复合词,其中,长度为4的词语占38.16%。例如,CWSA模型提取出“前置摄像头”“后置摄像头”“通话音质”“外放声音”等更精细、更有意义的产品特征。了解“前置摄像头”“后置摄像头”等差异化的精细产品特征被用户提及的次数以及对应的正面、负面情感,能够帮助企业更好地分析和改进拍照功能。同样地,“通话音质”“外放声音”等复合词语,相较于描述范围宽泛的“音效”一词,能够更精确地反映用户对手机音效方面的要求。
图4
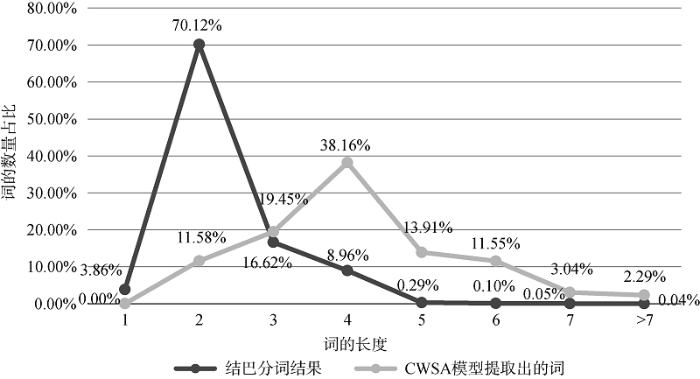
图4
Jieba分词结果和CWSA提取出的词的长度分布对比
Fig.4
Length Distribution of Jieba Segmentation Results and that of Words Extracted by CWSA
从词频方面来看,对方面词集合划定词频区间,词频区间内的方面词词频之和占总词频的比例越大,在一定程度上反映该词频段内的方面词所表征的产品特征越受用户关注。如图5所示,以近90万条用户评论为例①(针对大量文本的挖掘中,极低频词语包含的信息过于琐碎,故本文在进行分析时,过滤了词频低于5的方面词。),词频相对较低的方面词集合也是评论中非常值得研究的需求挖掘对象。词频区间为[5 000,50 000)的方面词词频之和占比超过了25%,词频区间为[100,5 000)的方面词词频之和更是占到27.49%,潜藏着丰富的可挖掘用户需求。如果采用基于关键词的分析方法,这些词频不突出的词语都会被忽略掉。CWSA模型为企业了解细分顾客群体的需求提供了可能。
图5
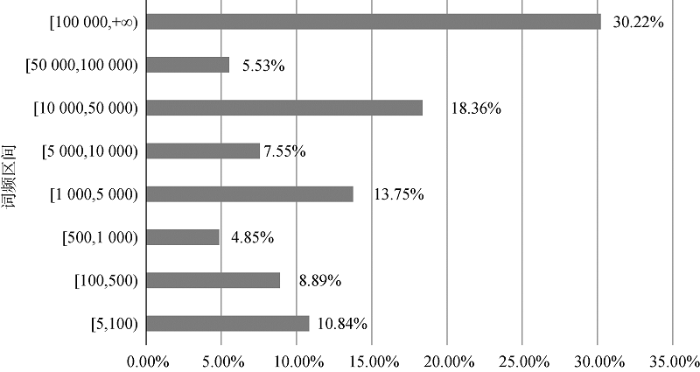
图5
各区间方面词词频之和的占比
Fig.5
Proportion of the Sum of Aspect Word Frequency in Each Interval
表4 京东手机评论中的方面词及其情感态度示例
Table 4
| 方面词 | 总频数 | 正面情感 | 中立情感 | 负面情感 |
|---|---|---|---|---|
| 屏幕 | 250 088 | 176 901 | 47 378 | 25 809 |
| 运行速度 | 248 014 | 203 120 | 13 429 | 21 465 |
| 拍照效果 | 215 501 | 175 628 | 17 103 | 22 770 |
| 音效 | 200 430 | 154 316 | 32 675 | 13 439 |
| … | … | … | … | … |
| 充电速度 | 7 503 | 6 967 | 173 | 363 |
| 发货速度 | 5 764 | 5 223 | 83 | 458 |
| 电池容量 | 5 162 | 4 256 | 340 | 566 |
| … | … | … | … | … |
| 屏幕分辨率 | 3 138 | 2 466 | 287 | 385 |
| 价保 | 1 613 | 35 | 16 | 1562 |
| 客服服务态度 | 1 439 | 1 133 | 45 | 261 |
| … | … | … | … | … |
| 后置摄像头 | 915 | 504 | 89 | 322 |
| 相素 | 432 | 343 | 12 | 77 |
| 120Hz刷新率 | 370 | 347 | 4 | 19 |
| … | … | … | … | … |
| 双立体声扬声器 | 40 | 38 | 2 | 0 |
| 諾基亚 | 6 | 2 | 0 | 4 |
| 超级快冲 | 5 | 5 | 0 | 0 |
此外,CWSA模型对错别字和繁体字也表现出良好的鲁棒性。表4中,词频为432的“相素”(应为“像素”)以及词频为5的“超级快冲”(应为“超级快充”)均含有错别字,“諾基亚”一词中则出现了繁体字“諾”,这类情况往往会严重干扰计算机的判断,导致分词结果产生错误进而影响需求挖掘,但CWSA模型表现良好。
6 结语
本文针对主流需求挖掘方法难以挖掘有效但相对低频的信息以及错别字处理等问题,从方面词角度着手,设计了CWSA模型进行方面词提取,并在此基础上结合方面级情感分析模型,充分挖掘细粒度用户需求。CWSA模型以语境窗口自注意力机制为核心,在把握评论整体语义信息的同时,着重分析语境窗口内以及邻近文本的特征,弱化了不相关文本对模型的负面干扰。为了在中文领域进行模型的训练优化与效果验证,本文基于京东手机在线评论构造了方面词提取与方面级情感分析中文数据集。实验证明,CWSA模型在方面词提取任务上表现优于基线模型可以很好地识别评论中存在的复杂复合名词,并对错别字和繁体字有着优秀的鲁棒性。将其与方面级情感分析模型进行有效结合,能够深入挖掘差异化、精细化的用户需求,兼顾高频和相对低频的产品特征,从而为企业把握市场需求、突破产品同质化困境提供了参考与便利。
考虑到中文领域目前还很缺乏优质的方面词提取和方面级情感分析数据集,本文仅在京东手机评论数据集上验证了方法的有效性。然而,只要能够合理构造相应的训练集和测试集,对CWSA模型完成领域性训练,并基于方面词提取结果进行方面级情感分析,本文方法同样可以适用于其他产品的差异化用户需求挖掘。未来的研究中,会选择其他产品进行精细分析,同时,也会考虑在英文领域数据集上改进实验,拓展本文方法在跨语言任务上的适应能力。
作者贡献声明
肖宇晗:设计实验方案,采集和构造实验数据集,设计并训练CWSA模型,实验结果分析,论文撰写;
林慧苹:提出研究思路,论文撰写与修改。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: yuhanxiao@pku.edu.cn。
[1] 肖宇晗. jingdong_ATE_output.txt. 京东手机评论的CWSA方面词提取结果.
[2] 肖宇晗. jingdong_ABSA_output.txt. 京东手机评论的方面级情感分析结果.
[3] 肖宇晗. jingdong_train.txt. 方面词提取与方面级情感分析中文训练数据集.
[4] 肖宇晗. jingdong_test.txt. 方面词提取与方面级情感分析中文测试数据集.
[5] 肖宇晗. user_ratings.xlsx. 京东手机评论的用户评分分布.
[6] 肖宇晗. user_comment_length.xlsx. 用户评论长度分布.
[7] 肖宇晗. jieba-CWSA.xlsx. Jieba分词结果和CWSA提取出的词的长度分布对比.
[8] 肖宇晗. proportion_of_word_frequency_sum.xlsx. 各区间方面词词频之和的占比.
[9] 肖宇晗. aspect_sentiment.xlsx. 京东手机评论中的方面词及其情感态度.
参考文献
Redesign for Product Innovation
[J].DOI:10.1016/j.destud.2011.08.003 URL [本文引用: 1]
An Optimum Design Selection Approach for Product Customization Development
[J].DOI:10.1007/s10845-010-0473-5 URL [本文引用: 1]
Customer Preference Oriented Product Design Using AHPModified TOPSIS Approach
[J].DOI:10.1108/BIJ-08-2011-0058 URL [本文引用: 1]
Customer Need Identification Methods in New Product Development: What Works “Best”?
[J].DOI:10.1142/S0219877018500086 URL [本文引用: 2]
Identifying Key Product Attributes and Their Importance Levels from Online Customer Reviews
[C]//
Hybrid Association Mining and Refinement for Affective Mapping in Emotional Design
[J].DOI:10.1115/1.3482063 URL [本文引用: 1]
Latent Dirichlet Allocation
[J].
A Statistical Interpretation of Term Specificity and Its Application in Retrieval
[J].DOI:10.1108/eb026526 URL [本文引用: 1]
TextRank: Bringing Order into Text
[C]//
Identification of the ToBeImproved Product Features Based on Online Reviews for Product Redesign
[J].DOI:10.1080/00207543.2018.1521019 URL [本文引用: 3]
The Analytics of ProductDesign Requirements Using Dynamic Internet Data: Application to Chinese Smartphone Market
[J].DOI:10.1080/00207543.2018.1541200 URL [本文引用: 3]
基于LDA主题识别与Kano模型分析的用户需求研究
[J].
User Demand Based on LDA Subject Identification and Kano Model Analysis
[J].
Attentive Aspect Modeling for ReviewAware Recommendation
[J].
Mining and Summarizing Customer Reviews
[C]//
Learning Algorithms for Keyphrase Extraction
[J].DOI:10.1023/A:1009976227802 URL [本文引用: 2]
Extracting Keyphrases from Research Papers Using Citation Networks
[C]//
网络评论方面级观点挖掘方法研究综述
[J].
Survey of Studies on Aspect-Based Opinion Mining of Internet
[J].
SemEval-2014 Task 4: Aspect Based Sentiment Analysis
[C]//
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[C]//
Efficient Estimation of Word Representations in Vector Space
[OL]. arXiv Preprint, arXiv: 1301.3781.
Distributed Representations of Words and Phrases and Their Compositionality
[C]//
特征驱动的关键词提取算法综述
[J].
Features Oriented Survey of State-of-the-Art Keyphrase Extraction Algorithms
[J].
FineGrained Opinion Mining with Recurrent Neural Networks and Word Embeddings
[C]//
Exploring SequencetoSequence Learning in Aspect Term Extraction
[C]//
Sequence to SequenceLearning with Neural Networks
[C]//
A Multitask Learning Model for ChineseOriented Aspect Polarity Classification and Aspect Term Extraction
[J].DOI:10.1016/j.neucom.2020.08.001 URL [本文引用: 3]
基于双特征嵌套注意力的方面词情感分析算法
[J].
An Algorithm for Aspect-Based Sentiment Analysis Based on Dual Features Attention-over-Attention
[J].
面向评论的方面级情感分析综述
[J].
DOI:10.11896/jsjkx.200200127
[本文引用: 1]

Comment-oriented aspect-level sentiment analysis is one of the key issues in text analysis.With the rapid development of social media,the number of online comments has exploded.More and more people are willing to express their attitudes and emotions on the Internet,but the style and quality of online comments are uneven.How to extract the user’s perspective accurately has become a difficulty.At the same time,users also pay more attention to some fine-grained information when browsing comments,and performing aspect-level sentimentanalysis on comments can help users make decisions better.This paper first introduces the related concepts and problem descriptions of aspect-level sentimentanalysis,and then introduces the research status of aspect-level sentiment analysis at home and abroad in recent years from aspects of aspect extraction and aspect-based sentiment analysis.The corpus and sentiment dictionary resources related to the aspect-level sentiment analysis task are shared,and finally the challenges faced by the aspect-level sentiment analysis and the possible future research directions are analyzed.
Review of Comment-Oriented Aspect-Based Sentiment Analysis
[J].
DOI:10.11896/jsjkx.200200127
[本文引用: 1]
Comment-oriented aspect-level sentiment analysis is one of the key issues in text analysis.With the rapid development of social media,the number of online comments has exploded.More and more people are willing to express their attitudes and emotions on the Internet,but the style and quality of online comments are uneven.How to extract the user’s perspective accurately has become a difficulty.At the same time,users also pay more attention to some fine-grained information when browsing comments,and performing aspect-level sentimentanalysis on comments can help users make decisions better.This paper first introduces the related concepts and problem descriptions of aspect-level sentimentanalysis,and then introduces the research status of aspect-level sentiment analysis at home and abroad in recent years from aspects of aspect extraction and aspect-based sentiment analysis.The corpus and sentiment dictionary resources related to the aspect-level sentiment analysis task are shared,and finally the challenges faced by the aspect-level sentiment analysis and the possible future research directions are analyzed.
AspectBased Sentiment Analysis Using Tree Kernel Based Relation Extraction
[C]//
A System for FineGrained AspectBased Sentiment Analysis of Chinese
[C]//
NRCCanada2014:Detecting Aspects and Sentiment in Customer Reviews
[C]//
Interactive Attention Networks for Aspect-Level Sentiment Classification
[C]//
Attentional Encoder Network for Targeted Sentiment Classification
[OL]. arXiv Preprint, arXiv: 1902.09314.
GloVe: Global Vectors for Word Representation
[C]//
Attention is All You Need
[C]//
LCF: A Local Context Focus Mechanism for AspectBased Sentiment Classification
[J].DOI:10.3390/app9163389 URL [本文引用: 1]
Bidirectional Recurrent Neural Networks
[J].DOI:10.1109/78.650093 URL [本文引用: 1]
Learning to Forget: Continual Prediction with LSTM
[J].Long short-term memory (LSTM; Hochreiter & Schmidhuber, 1997) can solve numerous tasks not solvable by previous learning algorithms for recurrent neural networks (RNNs). We identify a weakness of LSTM networks processing continual input streams that are not a priori segmented into subsequences with explicitly marked ends at which the network's internal state could be reset. Without resets, the state may grow indefinitely and eventually cause the network to break down. Our remedy is a novel, adaptive "forget gate" that enables an LSTM cell to learn to reset itself at appropriate times, thus releasing internal resources. We review illustrative benchmark problems on which standard LSTM outperforms other RNN algorithms. All algorithms (including LSTM) fail to solve continual versions of these problems. LSTM with forget gates, however, easily solves them, and in an elegant way.
Double Embeddings and CNNBased Sequence Labeling for Aspect Extraction
[C]//
Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network
[C]//
Reporting Score Distributions Makes a Difference: Performance Study of LSTMNetworks for Sequence Tagging
[C]//
Revisiting Pretrained Models for Chinese Natural Language Processing
[C]//
Analogical Reasoning on Chinese Morphological and Semantic Relations
[C]//
Natural Language Processing (Almost) from Scratch
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}