Extracting Entities from Intangible Cultural Heritage Texts Based on Machine Reading Comprehension
Fan Tao1,2,Wang Hao1,2(),Zhang Wei1,2,Li Xiaomin1,2
1School of Information Management, Nanjing University, Nanjing 210023, China 2Jiangsu Key Laboratory of Data Engineering and Knowledge Service, Nanjing 210023, China
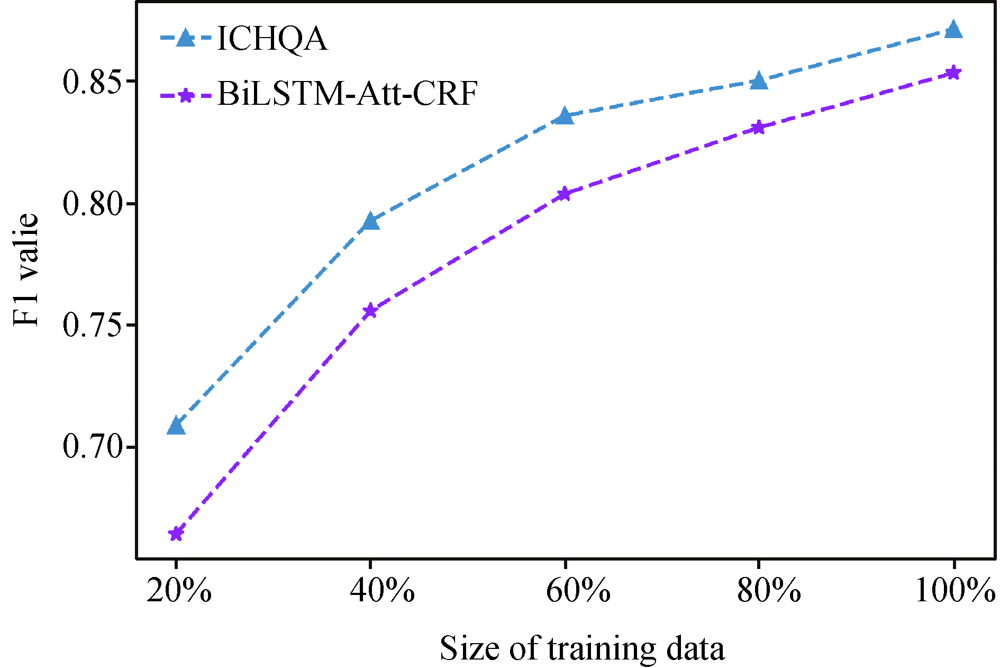
[Objective] This paper proposes a Question-Answering (QA) model based on machine reading comprehension (MRC) to extract entities from Intangible Cultural Heritage (ICH) texts. [Methods] First, we constructed an ICH entity sensitive attention mechanism, which captured the interaction between contexts and questions. The mechanism also helps our model focus on questions and related ICH entities. Then, we built the ICHQA model for entity extraction. [Results] We examined the ICHQA model with the ICH corpus. The ICHQA’s F1 value reached 87.139%, which was better than the existing models. We also performed ablation studies and visualized outputs of the ICHQA. [Limitations] More research is needed to examine the proposed model with other corpus from digital humanities. [Conclusions] The proposed model could effectively extract ICH entities.
范涛, 王昊, 张卫, 李晓敏. 基于机器阅读理解的非遗文本实体抽取研究*[J]. 数据分析与知识发现, 2022, 6(12): 70-79.
Fan Tao, Wang Hao, Zhang Wei, Li Xiaomin. Extracting Entities from Intangible Cultural Heritage Texts Based on Machine Reading Comprehension. Data Analysis and Knowledge Discovery, 2022, 6(12): 70-79.
(Fang Zhiyu, Fang Zhong. Digitalization Constructing the New Model of Intangible Cultural Heritage Inheritance[J/OL]. Chinese Social Sciences Today. (2021-03-09). http://www.cssn.cn/zx/bwyc/202103/t20210309_5316504.shtml. )
(Zheng Haiou. The Protection of Chinese Intangible Cultural Heritage Attracts Much Attention[N/OL]. People’s Daily. (2021-06-12). http://gs.people.com.cn/n2/2021/0612/c183342-34774089.html. )
(Jing Yi, Lin Rui, Liu Junguo, et al. Strengthen the Protection and Inheritance and Let Intangible Cultural Heritage Blossom More Charming[N/OL]. People’s Daily. (2021-02-10). http://hb.people.com.cn/n2/2021/0210/c194063-34575307.html. )
[4]
Dou J H, Qin J Y, Jin Z X, et al. Knowledge Graph Based on Domain Ontology and Natural Language Processing Technology for Chinese Intangible Cultural Heritage[J]. Journal of Visual Languages & Computing, 2018, 48: 19-28.
[5]
Dragoni M, Tonelli S, Moretti G. A Knowledge Management Architecture for Digital Cultural Heritage[J]. Journal on Computing and Cultural Heritage, 2017, 10(3): 1-18.
(Qin Tianyun, Wang Dongbo. Automatic Extraction of Traditional Music Terms of Intangible Cultural Heritage[J]. Data Analysis and Knowledge Discovery, 2020, 4(12): 68-75.)
[8]
Lafferty J D, McCallum A, Pereira F C N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C]// Proceedings of the 18th International Conference on Machine Learning. 2001: 282-289.
[9]
Huang Z H, Xu W, Yu K. Bidirectional LSTM-CRF Models for Sequence Tagging[OL]. arXiv Preprint, arXiv: 1508.01991.
[10]
Li X Y, Feng J R, Meng Y X, et al. A Unified MRC Framework for Named Entity Recognition[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2020: 5849-5859.
[11]
Li X Y, Yin F, Sun Z J, et al. Entity-Relation Extraction as Multi-Turn Question Answering[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2019: 1340-1350.
[12]
Wang Q F, Yang L, Kanagal B, et al. Learning to Extract Attribute Value from Product via Question Answering: A Multi-Task Approach[C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 47-55.
[13]
Sun C, Yang Z H, Wang L, et al. Biomedical Named Entity Recognition Using BERT in the Machine Reading Comprehension Framework[J]. Journal of Biomedical Informatics, 2021, 118: 103799.
doi: 10.1016/j.jbi.2021.103799
[14]
Xu H M, Wang W T, Mao X, et al. Scaling up Open Tagging from Tens to Thousands: Comprehension Empowered Attribute Value Extraction from Product Title[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2019: 5214-5223.
[15]
Noor S, Shah L, Adil M, et al. Modeling and Representation of Built Cultural Heritage Data Using Semantic Web Technologies and Building Information Model[J]. Computational and Mathematical Organization Theory, 2019, 25(3): 247-270.
doi: 10.1007/s10588-018-09285-y
[16]
Dimitropoulos K, Tsalakanidou F, Nikolopoulos S, et al. A Multimodal Approach for the Safeguarding and Transmission of Intangible Cultural Heritage: The Case of I-Treasures[J]. IEEE Intelligent Systems, 2018, 33(6): 3-16.
[17]
Li J, Sun A X, Han J L, et al. A Survey on Deep Learning for Named Entity Recognition[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(1): 50-70.
doi: 10.1109/TKDE.2020.2981314
[18]
Luo Y, Zhao H, Zhan J L. Named Entity Recognition Only from Word Embeddings[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2020: 8995-9005.
[19]
Luan Y, Ostendorf M, Hajishirzi H. Scientific Information Extraction with Semi-Supervised Neural Tagging[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2017: 2630-2640.
(Huang Shuiqing, Wang Dongbo, He Lin. Research on Constructing Automatic Recognition Model for Ancient Chinese Place Names Based on Pre-Qin Corpus[J]. Library and Information Service, 2015, 59(12): 135-140.)
doi: 10.13266/j.issn.0252-3116.2015.12.020
(Li Na. Automatic Extraction of Alias in Ancient Local Chronicles Based on Conditional Random Fields[J]. Journal of Chinese Information Processing, 2018, 32(11): 41-48.)
(Xu Chenfei, Ye Haiying, Bao Ping. Automatic Recognition of Produce Entities from Local Chronicles with Deep Learning[J]. Data Analysis and Knowledge Discovery, 2020, 4(8): 86-97.)
[23]
Reddy S, Chen D Q, Manning C D. CoQA: A Conversational Question Answering Challenge[J]. Transactions of the Association for Computational Linguistics, 2019, 7: 249-266.
doi: 10.1162/tacl_a_00266
[24]
Kwiatkowski T, Palomaki J, Redfield O, et al. Natural Questions: A Benchmark for Question Answering Research[J]. Transactions of the Association for Computational Linguistics, 2019, 7: 453-466.
doi: 10.1162/tacl_a_00276
[25]
Wang W H, Yang N, Wei F R, et al. Gated Self-Matching Networks for Reading Comprehension and Question Answering[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2017: 189-198.
[26]
Levy O, Seo M, Choi E, et al. Zero-Shot Relation Extraction via Reading Comprehension[C]//Proceedings of the 21st Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2017: 333-342.
[27]
Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[OL]. arXiv Preprint, arXiv: 1301.3781.
[28]
Gui T, Ma R, Zhang Q, et al. CNN-Based Chinese NER with Lexicon Rethinking[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. 2019: 4982-4988.
[29]
Wang S, Manning C. Fast Dropout Training[C]// Proceedings of the 30th International Conference on Machine Learning. 2013: 118-126.
[30]
Cao P F, Chen Y B, Liu K, et al. Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2018: 182-192.
[31]
Qin Q L, Zhao S, Liu C M. A BERT-BiGRU-CRF Model for Entity Recognition of Chinese Electronic Medical Records[J]. Complexity, 2021, 2021: 6631837.
[32]
Devlin J, Chang M W, Lee K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. 2019: 4171-4186.