【目的】通过调研和梳理文献,总结基于图神经网络的知识图谱补全方法。【文献范围】以“Knowledge Graph Completion”、“知识图谱补全”作为检索词在Web of Science、DBLP和CNKI数据库中进行检索,共筛选出79篇文献。【方法】分别归纳总结图卷积神经网络、图注意力网络、图自动编码网络三种基于图神经网络的知识图谱补全方法类别,并对每种类别的技术脉络、典型方法、模型框架优缺点等进行对比论述。【结果】运用知识图谱补全任务的常用数据集和评价指标,从MRR、MR、Hit@k等性能评价角度对各类模型的效果进行对比分析,并对未来研究提出展望。【局限】在实验结果对比中,只讨论了FB15K-237和WN18RR数据集上部分应用较广的模型的评估结果,缺乏全部模型在同一数据集上的对比。【结论】相比基于表示学习模型和基于神经网络模型,基于图神经网络模型具有更好的图谱补全性能,但模型关系复杂性高、过平滑、可扩展性通用性差,这也是未来研究要解决的问题。
【目的】对国内外语义新颖性研究相关进展进行归纳整理,总结相关技术,为后续研究提供参考。【文献范围】利用“novelty of the literature”“semantic novelty”“文献新颖性”等关键词及“语义新颖性and文献评价”等检索式在Web of Science、Elsevier、Springer、谷歌学术及中国知网、万方、维普等数据库中进行文献检索,经过阅读整理并对具有代表性的相关理论进行溯源,最终筛选出70篇文献进行评述。【方法】对国内外语义新颖性相关研究进行梳理,围绕新颖性定义、新颖性评价指标和不同评价方法等分析科技文献语义新颖性评价的发展现状及未来趋势。【结果】语义新颖性评价逐渐受到学界的广泛关注,已有相关研究对语义内容进行挖掘评价,但尚未形成统一的度量指标。【局限】现有的文献新颖性多从外部特征进行评价,直接以语义新颖性为主题的研究文献数量较少,在支撑综述方面存在局限性。【结论】科技文献的语义新颖性评价根本在于语义内容的新颖性,定量研究已成为主流研究方法,但评价指标的计算方式尚需明确,未来的新颖性评价发展方向应结合定性与定量方法全面分析,实现科学、合理的综合学术评价。
【目的】本研究旨在探讨构建抑郁严重度预测模型及其解释性问题,通过分析互联网用户生成的内容,进一步发展抑郁症风险预测研究,从而提高抑郁症自动检测模型的可靠性和实用性。【方法】通过收集“好大夫在线”平台上的抑郁症医疗咨询文本记录,构建了一个语料库。利用心理学词典,从中提取了患者的心理特征,并采用梯度提升树算法预测患者的病情,同时引入可解释机器学习方法SHAP解读模型,借助SHAP独特的可视化图表剖析患者年龄、性别、认知、情感、感知、社会家庭及个人得失与抑郁症发生之间的复杂关系。【结果】抑郁症患者心理状态能反馈患者病况,利用从患者问诊记录中提取的心理特征能够有效检测重度抑郁,准确率达到86%。可解释机器学习模型SHAP解释了模型的预测结果,揭示出患者各层面心理特征对抑郁症发生产生的多重效应。【局限】受语料集所限,仅利用单次问诊记录对抑郁程度做预测;而模型特征基于心理学词典,更多与抑郁症发生风险有关的要素可纳入建模考虑中。【结论】影响抑郁症产生及发展的因素复杂。个体差异致使各项特征对于疾病预测产生不同效应。构建抑郁症的自动诊断模型,不仅要关注模型的精准度,更需增强对模型预测的理解。
【目的】利用在线健康社区文本依存句法结构中蕴含的情感知识进行情感分析,提出一种基于情感增强和知识融合的在线健康社区情感分析模型WoBEK-GAT。【方法】首先,采用WoBERT Plus实现动态词嵌入;其次,利用卷积神经网络(CNN)和双向长短时记忆网络(BiLSTM)提取语义特征;最后,通过情感增强和知识融合策略将剪枝依存句法树中的关键句法信息与外部情感知识充分融合,并输入图注意力网络(GAT)中进而输出情感类别。【结果】在构建的中文数据集上进行对比实验,实验结果表明WoBEK-GAT模型MacroF1值达到88.48%,较基准模型CNN、BiLSTM和GAT分别提升15.49、14.15和13.15个百分点。【局限】未考虑图片和语音等多模态信息中的情感知识。【结论】依存句法信息的加入以及情感增强策略和知识融合策略的结合能够有效提升模型的情感分析能力。
【目的】探究威胁评估对用户防御性隐私保护行为意愿的影响机理,有助于企业制定合理的隐私管理决策,进而营造健康的企业数字生态。【方法】基于保护动机理论并聚焦威胁评估,创新性地引入“信息隐私焦虑”作为情感中介变量,将情境的信息敏感度作为调节变量,构建威胁评估对用户防御性隐私保护行为意愿的影响机理模型。运用SEM-PLS对收集的金融情境183份和电子商务情境200份数据进行实证分析。【结果】信息隐私焦虑是影响用户产生防御性隐私保护行为意愿的关键情感因素,信息隐私焦虑在感知威胁和防御性隐私保护行为意愿之间起部分中介作用;情境的信息敏感度正向调节信息隐私焦虑与防御性隐私保护行为意愿的关系;情境的信息敏感度仅对感知脆弱性与感知威胁的关系具有调节作用,而对感知严重性与感知威胁的关系没有调节作用。【局限】第一,探究的是行为意愿而非实际行为;第二,在信息敏感度对比方面,仅选取具有代表性的金融和电子商务两种情境。【结论】本研究补充和发展了保护动机理论,对企业采取合适的管理措施以减少用户防御性隐私保护行为提供理论指导。
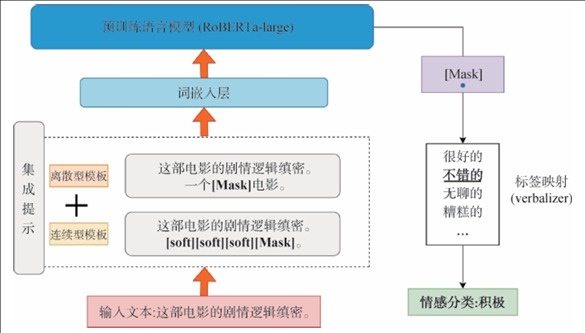
【目的】解决在样本量不足的情况下,使用预训练模型进行情感分类准确率偏低的问题。【方法】提出一种基于提示学习增强的情感分类模型Pe-RoBERTa,以RoBERTa模型为基础,使用不同于传统微调方法的集成提示方法,通过提示帮助模型进一步理解下游任务,改善模型对文本情感特征的提取能力。【结果】在多个公开的中英文情感分类数据集上的实验表明,少样本场景下模型的平均情感分类准确率为93.2%,相较于传统微调和离散型提示,准确率分别提升13.8%和8.1%个百分点。【局限】处理的数据模态仅限于文本形式,目标任务主要为情感二分类任务,没有做细粒度更高的情感分类任务。【结论】Pe-RoBERTa模型能够有效地进行文本情感特征的提取,在多个情感分类任务中取得较高的准确率。
【目的】基于多模态学习方法,对新闻中文本和图片相结合内容,构建多模态主题模型,自动挖掘新闻中的潜在主题。【方法】采用结合词嵌入的主题模型,从图片和文本两方面进行主题建模,并且使用多模态联合表征学习和协同表征学习的方法进行特征融合。最后,对发现的多模态新闻主题进行可视化分析,结合N15News数据集进行实证研究。【结果】实验结果表明,相对于仅使用文本特征的Label-ETM,多模态主题建模方法可以获得更好的主题的可解释性和多样性。这说明多模态主题建模方法具有一定的可行性与合理性。【局限】本文假设新闻中的图片和文字在语义和主题上是相关的,在弱相关和不相关领域多模态融合方法仍需要改善。【结论】多模态主题建模可以发现不同模态数据之间的联系,提高发现主题的多样性。
【目的】改进SCCL模型在文本深度聚类任务上的效果,提出一种新的基于SCCL的文本深度聚类模型ISCCL。【方法】ISCCL模型基于句向量预训练语言模型对输入文本进行数据增强和编码获取两组增强表征,在SCCL模型的基础上增加两层非线性网络,将增强表征降维到维度与聚类数量相同的类簇特征空间。从列空间的角度构造正负簇对进行对比学习,引导模型挖掘对聚类任务有用的特征,并减少假正样本产生的影响。【结果】在AgNews、Biomedical、StackOverflow、20NewsGroups和zh10共5种基准数据集中,ISCCL模型的聚类准确率分别达到88.89%、48.74%、78.17%、56.97%和86.42%,较SCCL模型提升0.69%~2.67%。【局限】需要预先设定类簇特征空间维度(与聚类数目K值相同),然而在实际应用中往往很难明确原始数据的具体聚类数目,应当根据数据情况适当调整。【结论】ISCCL模型能够有效提取类簇特征,在SCCL模型的基础上提升了文本深度聚类效果。
【目的】为解决现有根据单一文本特征生成的中文摘要质量不佳问题,提出一种融合内容和图片特征的中文摘要生成方法。【方法】使用BERT提取文本特征,使用ResNet提取图片特征,该特征能够对文本特征进行补充与验证,并利用注意力机制将两种模态特征进行融合,最终将融合后的特征送入指针生成网络模型进一步生成质量更高的中文摘要。【结果】实验结果表明,所提方法相较于仅使用单一文本模态生成中文摘要的方法,在ROUGE-1、ROUGE-2和ROUGE-L指标上分别有1.9、1.3和1.4个百分点的提升。【局限】实验数据主要来源于新闻领域,在其他领域中的效果有待验证。【结论】加入图片信息能够使融合后的特征保存更多重要信息,帮助模型更好地定位关键内容,使生成的摘要更具有概括性和可读性。
【目的】针对当前阅读理解类问答推理过程中传统无监督检索方式句子关联性不足的问题,设计一种检索模型,研究问答任务的推理过程,探求问答任务的可解释性。【方法】提出一种新型无监督检索模型ISR,模型中融合皮尔逊相关系数、GloVe词嵌入、IDF加权等主要模块,ISR模型通过多轮迭代方式细粒度检索推理句。【结果】对比模型MSSwQ,ISR模型在MultiRC数据集上进行实验,P、R、F1指标平均高出2.4、1.8、2.1个百分点;在HotPotQA数据集上进行实验,P、R、F1指标平均高出4.8、2.6、3.7个百分点。【局限】检索采用硬匹配,可能存在过分匹配的情形。【结论】本文模型能够提升检索推理句的准确性,检索的推理句能够有效应用于问答任务的推理过程。
【目的】本研究提出一种针对科研团队的深度学习组推荐模型,旨在满足科研团队招聘科研人员的需求,提高推荐效率。【方法】首先应用自注意力机制学习团队的语义表示,接着采用神经协同过滤模型学习团队与科研人员间的非线性关系,最终得到团队与人员的契合程度作为推荐的依据。【结果】实验结果显示,在公共数据集上,与基线模型相比,本文模型在推荐正确率和F1值上分别提高10.22和10.25个百分点,在实际推荐场景中表现优异。【局限】深度学习模型的参数量较小,仍有优化空间。【结论】本文模型可以有效提高科研人员招聘的效率,有助于科研服务机构提升服务水平,满足科研团队招聘人员的需求。
【目的】为传承和弘扬印章文化,提升对复杂情境下印章的识别效果,结合知识图谱和可视化技术对识别结果及相关知识进行结构化展示。【方法】提出一种融合多特征的深度学习模型。首先,提取印章图像的颜色特征图、边缘特征图和灰度特征图;其次,将三种特征图输入深度学习模型进行识别;再次,将识别结果与知识图谱中的节点进行比对;最后,对相关知识进行可视化展示。【结果】采集并标注《寒食帖》等13幅字画上所含的印章,将其中两幅作品作为测试集。与VGG16模型相比,本文模型的精确率、召回率、F1值分别提高28.40、28.67和28.54个百分点。在未融合多特征的情况下,精确率、召回率、F1值分别下降24.30、20.16和22.74个百分点。【局限】本文模型仅能对印章的全局特征进行提取和识别,缺少对印章局部语义信息的识别和推理能力。【结论】本文方法在印章识别任务上具有良好的效果,其中多维度的特征图可以提升模型对复杂情境的识别能力和鲁棒性。
【目的】为弥补当前视觉情感分析研究的不足,构建基于ResNet34改进的情感分析模型,分析和提高图像情感分类的精度。【方法】首先基于ResNet34架构建立视觉情感识别模型,然后通过融合CBAM模块和Non-Local模块,对情感特征进行学习、表示,最后利用以上模型对情感特征进行分类识别,并且与VGG16和ResNet50模型进行对比以验证构建模型的优越性及精度。【结果】通过实验验证所构建的模型的识别效果,研究结果表明模型的准确率、精确率、召回率和F1值分别达到84.42%、84.10%、83.70%和83.80%。与基线模型进行对比,所提模型的准确率相比于VGG16和ResNet50模型分别提升4.17和3.44个百分点,F1值分别提升4.20和3.30个百分点。【局限】测试的数据集规模相对不大,未采用皮尔曼系数等计算标注的效果,未将基于视觉的情感分类算法进行比较。【结论】从视觉情感分析视角对情感识别模型进行优化,补充了情感计算的分析模态,为舆情信息情感特征提取和分析提供了支撑。

