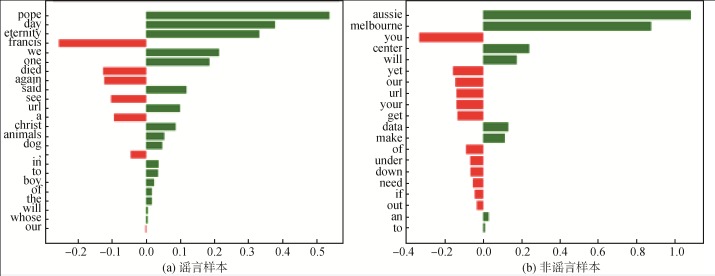
【目的】 探究基于内容的深度谣言检测模型能否真正识别谣言的关键语义。【方法】 基于谣言检测任务的中英文基准数据集,本文分别利用基于局部代理模型的可解释工具LIME和基于合作博弈论的可解释工具SHAP,分析BERT模型所识别出的关键特征,并判断其是否能反映谣言特性。【结果】 可解释工具在不同模型与数据集上计算得出的关键特征差异性较大,无法辨别模型识别的重要特征和谣言之间的语义关系。【局限】 本文验证的数据集和模型数量都十分有限。【结论】 基于深度学习的谣言检测模型仅拟合了训练集的特征,面向多样的真实场景缺少足够的泛化性和可解释性。
【目的】 针对专利技术功效实体的自动识别问题,智能感知生成专利文献中的关键技术功效,辅助专利技术功效矩阵高质量构建。【方法】 本文提出将ChatGPT应用于专利技术功效实体抽取任务的新思路,使用ChatGPT+Prompt的方法实现专利技术词、功效词以及技术-功效二元组的识别、提取和生成。【结果】 本文识别生成了4个领域、三种语言的专利技术功效实体,跨领域、跨语言、提示样本数量对比的实验结果(ROUGE值)表明,该方法能够较为准确地识别技术功效二元组。新能源汽车领域效果最佳,英文专利表现最优,跨域能力和跨语言能力显著,给予One-Shot显著提升模型性能。【局限】 本文方法仍存在Prompt不标准、生成内容重复、单轮或多轮问答的选择困难等问题。【结论】 本文方法具备合理性和可行性,有效降低技术功效实体生成的人力成本和任务门槛,拓展AIGC的应用场景,释放ChatGPT在专利文献挖掘的潜力。
【目的】 解决序列建模对触发词之间的长距离依赖关系和触发词与论元实体关系捕获不足的问题,提升事件抽取任务上的效果。【方法】 提出一种基于预训练模型XLNET和图注意力网络GAT的句法信息增强事件抽取模型SEM-XG ,通过预训练语言模型进行文本表示,引入依存句法树中依赖弧增强信息流,将单词看作图中的节点,使用图注意力网络进行图信息建模,得到融入句法信息的单词表示,从而联合抽取句子中的事件触发词和论元角色。在CNC数据集和ACE2005数据集上,开展实证研究。【结果】 在CNC数据集上,SEM-XG在触发词分类任务上的F1值为94.4%,在论元分类任务上的F1值为94.0%。在ACE2005数据集上,SEM-XG在触发词分类任务上的F1值为76.7%,在论元分类任务上的F1值为66.3%。实验结果表明,本文模型能够有效提升事件抽取的效果。【局限】 尚未探究联合事件抽取模型迁移到搜索引擎、智能问答等任务上的效果。【结论】 通过句法信息增强以及图注意力网络建模,能够显著提升联合事件抽取的效果。本文对于触发词分类和论元分类,提升事件抽取在科技文献分析、信息检索等领域的应用效果具有重要参考意义。
【目的】 针对知识图谱补全任务,挖掘语义与结构信息,完善知识图谱并提升质量与可靠性。【方法】 提出一种融合语义与结构信息的知识图谱补全模型,通过预训练语言模型增强知识图谱内文本及上下文数据的嵌入表示,捕获实体与关系的语义信息,并构建实体-关系矩阵映射知识图谱网络结构,获取实体的邻域信息与关系约束,进一步融合潜在数据,进行模型训练并预测丢失实体,最终达成知识图谱补全任务。【结果】 与基线方法性能相比,该模型的Hits@3评测指标在FB15k-237、WN18RR和UMLS数据集上分别提升0.5、0.6和0.6个百分点。【局限】 受限于语言模型的基础表示能力,未能结合多模态数据进一步提升补全任务效果。【结论】 该模型具有较好的补全性能,融合语义与结构信息的方式对比其他方法具有一定优势,能够较好地完成知识图谱补全任务,对知识图谱及其下游应用的发展具有重要意义。
【目的】 梳理归纳多模态命名实体识别研究成果,为后续相关研究提供参考与借鉴。【文献范围】 在Web of Science、IEEE Xplore、ACM Digital Library、中国知网数据库中,以“多模态命名实体识别”“多模态信息抽取”“多模态知识图谱”为检索词进行文献检索,共筛选出83篇代表性文献。【方法】 从概念、特征表示、融合策略和预训练模型4个方面对多模态命名实体识别研究进行总结论述,指出现存问题和未来研究方向。【结果】 多模态命名实体识别目前主要围绕模态特征表示和融合两个方面展开且在社交媒体领域取得了一定进展,需要进一步改进多模态细粒度特征提取和语义关联映射方法以提升模型的泛化性和可解释性。【局限】 直接以多模态命名实体识别为研究主题的文献数量较少,在支撑综述结果方面存在局限性。【结论】 针对多模态命名实体识别亟需解决的问题展望未来发展趋势,为进一步拓宽多模态学习在下游任务应用的研究范畴、破解模态壁垒和语义鸿沟提供了新思路。
【目的】 梳理深度学习模型在术语识别中的研究现状与面临挑战。【文献范围】 在中国知网和Web of Science中,分别以主题=“术语识别”+“术语抽取”、主题=“(extract terms OR term recognition OR technology detection OR relation classification) AND deep learning AND ner”作为检索式进行检索,共筛选73篇文献进行述评。【方法】 对基于深度学习的术语识别一般框架、模型的选择及各模型的优缺点、未来发展趋势进行综述。【结果】 基于深度学习的术语识别方法可划分为使用单一神经网络模型、复合神经网络模型和结合深度学习模型的术语识别三大类。从方法使用来看,以BiLSTM-CRF为核心及延伸的模型是术语识别的主流方法;BERT及BERT的优化模型是近年来的研究热点;在特定领域倾向于使用多任务模型代替神经网络模型;迁移学习以及主动学习的应用成为新的研究方向。【局限】 仅对已有研究的不同模型及训练结果进行结构化分析,缺少对不同模型在同一数据集上的训练效果对比,待未来进一步研究。【结论】 基于深度学习的术语识别未来可在术语标注模式、融合术语的多维特征、小数据集或零数据集的术语识别技术、跨领域模型泛化、结果可解释性和完善评价方法等方面深入研究。
【目的】 实现地图的多重语义分类,满足地图精准检索与情报分析的需求。【方法】 设计地图类目体系,提出地图多标签分类策略,基于AlexNet卷积神经网络分类模型实现南海地图多标签自动分类。【结果】 南海地图多标签自动分类模型的F1值为0.979,模型能够有效实现南海地图的多标签自动分类。【局限】 多标签标注数据集的深层次类目有待补充。【结论】 研究内容为基于语义的地图科学分类、精准检索与跨类关联提供了参考。

【目的】 综合考虑论文的创新性和影响力,提出一种新的论文代表作遴选方法。【方法】 基于论文创新性和影响力测度指标,设计代表性指数,遴选代表性指数靠前的论文作为学者的论文代表作。以诺贝尔物理学奖获得者为例,遴选其论文代表作,将平均排名和准确率作为评价指标检验遴选方法的有效性和准确性。选取张涛院士和Hirsch J E教授进行案例分析,使用代表性指数遴选其论文代表作。【结果】 实证结果表明,与其他6种遴选方法对比,使用代表性指数遴选论文代表作在平均排名(2.838)和准确率(63.158%)两个指标上均排名第一。【局限】 使用的测度指标需要一定的引文积累,可能无法有效选出学者新近做出的重要工作。【结论】 所提论文代表作遴选方法具备可行性。
【目的】 充分挖掘科学知识网络社群多元特征,提升领域新兴趋势预测效果。【方法】 基于e-Health领域新兴社群到热点社群的成长路径回溯,本文提出一种融合词汇功能属性的新兴趋势多元特征预测模型。【结果】 在e-Health领域,所融合的主题、技术等词汇功能属性特征能够提升新兴趋势预测性能,综合结构、影响、序列和属性4组特征的RF算法模型效果最佳。词汇功能属性规模大、密度低、中介中心性高、波动率大的社群更有可能成为新兴社群。序列特征对新兴社群预测效果欠佳,可能受到新兴社群的前瞻性影响。【局限】 词汇功能识别结果存在一定领域依赖,结论扩展到其他领域的有效性需进一步验证。【结论】 充分挖掘科学文本词汇细粒度语义特征,能够有效提升新兴趋势预测性能,对科学内容评价和科技决策支持具有一定参考意义。
【目的】 克服论文与专利之间语言特征差异的障碍,将论文和专利数据按照研究主题集成融合。【方法】 以维基百科为基本分类体系,通过半自动方式构建少量标注集,设计半监督深度文本聚类模型,将相似主题的论文与专利聚类融合,设计指标评估数据融合结果的质量。【结果】 所提模型在两个数据集上的聚类准确率比其他基线模型提升了2.4~11.9个百分点,数据融合结果的质量评估得分超过0.9,优于基线模型,可以在已知主题的基础上补充研究主题。【局限】 未利用融合数据开展实证分析,聚类数目需要人工确定。【结论】 所提模型可以从论文和专利差异化的文本中提取与主题相关的特征,有效地实现数据融合。
【目的】 针对目前的谣言检测方法未能充分考虑评论间的转发关系特征和文本语义特征,提出一种基于图卷积网络和注意力机制的谣言检测方法。【方法】 首先,对评论间转发和回复关系特征进行分析,构建评论关系特征图,充分挖掘评论间的关联特性。然后,根据评论间的文本语义相似性,使用BERT模型生成句子的向量化表示并通过计算余弦相似度构建评论的语义特征图,充分提取评论的语义相关性。最后,基于图卷积网络完成不同节点之间的信息传递,并在各节点信息传输过程中使用注意力机制区分源评论和其他评论对谣言检测的影响,进而得到评论节点的准确表示。【结果】 在公开数据集上进行实验,结果显示所提方法在Twitter15和Twitter16数据集上的准确率分别达到0.860和0.870,F1均值分别为0.858和0.866。与BiGCN方法相比,准确率分别提升了5.1%和1.5%,F1均值分别提升了5.0%和1.9%。【局限】 仅使用文本数据进行谣言检测,未结合图片、用户属性及时间属性等特征。【结论】 在公开数据集上进行应用,验证了所提方法可以有效地提升谣言检测性能,为谣言识别与检测任务提供有价值的参考。
【目的】 为信贷欺诈检测提供兼具空间和邻域自适应性的图卷积神经网络模型。【方法】 提出双曲跳跃图卷积神经网络。在空间自适应方面,将节点属性表示为双曲空间可训练曲率,从而完成欺诈网络的低失真嵌入表示;在邻域自适应方面,定义双曲跳跃连接框架(HJK-Net)框架,通过双曲层间聚合机制对邻域表示结果进行融合。从而为关系网络提供融合空间和邻域自适应性的图表示学习结果,进而完成信贷欺诈检测任务。【结果】 通过在公开且来源于实际业务场景的大型社交网络中部署实验,所提模型的AUC指标达到0.833 5,相比于以GraphSAGE(NS)为代表的基线模型提升0.059 4。【局限】 浅层社交网络对邻域自适应性的优势略有限制,所提模型在大型复杂深度网络结构中优势更加明显。【结论】 空间自适应为节点属性相关性提供更准确描述,邻域自适应为图表示学习选择最优的邻域聚合范围;融合空间和邻域自适应的模型在大型欺诈关系网中具备更好的识别效果。
【目的】 通过选取新分类特征,提高探索式与查找式意图自动识别的准确度。【方法】 在AOL查询日志中,选取1 805个查询并对其进行人工标注;在采莓模型的启示下,分别从查询性质、搜索过程与信息来源三个层面提出分类特征;进一步比较所提出特征在朴素贝叶斯、SVM、决策树、随机森林与神经网络5种分类模型中的分类效果;最后分析不同特征集合以及每个特征的分类效果。【结果】 三种分类特征均能对探索式与查找式意图进行有效区分,其中查询性质相关特征的识别效果最佳;在5种分类模型中,采用神经网络算法的分类模型性能最佳(Accuracy=0.817 2,Precision=0.849 4,Recall=0.774 7,F1=0.810 3)。【局限】 未在多个数据集中验证新提出的分类特征的性能;未充分挖掘用户搜索行为以此形成更多有效的分类特征;由于人工标注存在高耗时、高人力成本等问题,使得最终应用于探索式/查找式意图识别的数据集有限。【结论】 基于采莓模型启示提出的特征能对探索式与查找式意图进行有效区分。

