王雪颖 , 张紫玄, 王昊, 邓三鸿
, 张紫玄, 王昊, 邓三鸿
Wang Xueying, Zhang Zixuan, Wang Hao, Deng Sanhong
中图分类号: G252
通讯作者:
收稿日期: 2017-05-17
修回日期: 2017-06-27
网络出版日期: 2017-07-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】通过分析中国农产品品牌评价领域的文献题名总结该领域的研究现状。【方法】对该领域的文献题名进行K-means聚类, 分析每簇研究的重点内容, 分别使用因子分析、多维尺度分析和层次聚类分析进一步解析聚类得到的每簇文献的特点。【结果】文献数量总体呈现“M”型趋势, 文献多采用模糊综合法, 从多个评价角度集中探讨评价指标体系、评价模型、影响因素等方面。【局限】仅针对题名进行分析, 未涉及关键词与摘要文本。【结论】聚类结果较好地揭示了中国该领域的研究现状, 但没有反映出种类农产品、Interband品牌评估法相关内容。
关键词:
Abstract
[Objective] This paper analyzes titles of research evaluating brands of agriculture products in China, aiming to summarize the latest developments in this field. [Methods] First, we used the k-means to cluster the retrieved titles. Then, we employed factor analysis, multidimensional scale analysis, and hierarchical clustering analysis to examine the data. [Results] We found the total number of articles published each year, as well as research topics, brand types, evaluation methods and perspectives, and impact factors of these studies. [Limitations] We did not examine keywords and abstracts of the selected literature. [Conclusions] The results of clustering reveals the developments of related research. However, our study does not discuss types of products and methods of interband evaluations.
Keywords:
中国是一个农业大国, 农业是国民经济的支柱产业之一, 其发展一直受到各级政府的高度重视[1]。随着市场经济不断发展、产业结构不断调整, 大量农产品实现了产业化并创立品牌。农产品从性质上主要分为区域农产品、企业农产品、种类农产品三类。区域农产品指某个区域的农产品, 以县为单位申报, 具有鲜明的地域性, 可以视作地理标志[2], 比较著名的有新疆农产品[3]、安化黑茶[4]等。企业农产品顾名思义是指企业生产的农产品, 如光明乳品、鲁花花生油等。种类农产品指某一种类的农产品, 如红富士苹果等。与发达国家、先进地区的农产品品牌相比, 中国农产品品牌建设起步晚, 有关评价指标体系的研究还比较滞后[5]。在2016年“全球最有价值的品牌”排行榜中, 前100强的品牌基本来自美国、日本、韩国、欧洲; 在2016年“中国最有价值品牌”排行榜中, 只有茅台、伊利、蒙牛、双汇、洋河、青岛啤酒、张裕等7个农产品品牌上榜。这说明中国的品牌竞争力在国际范围内较弱, 并且农产品品牌在国内市场中占的份额较小。
本文统计中国农产品品牌评价领域相关文献的年度发文趋势, 分析相关政策对研究的影响; 对题名分词并去掉停用词, 形成文献-术语矩阵(Document- Term Matrix, DTM), 使用MATLAB对DTM进行K-means聚类, 分析每簇研究的内容并与综述比较; 对每个簇分别进行因子分析、多维尺度分析和层次聚类分析, 探讨每簇的重点内容。通过对研究内容的总结、分析, 希望可以为今后农产品品牌评价方面的研究提供参考。
本文基于文献分析法讨论目前中国农产品品牌评价的研究现状。相关研究包括两方面: 农产品品牌评价领域的研究; 相关方法的探讨。
(1) 在农产品品牌评价领域, 根据评价的角度, 可以将评价标准分为以下三类:
①评价方法角度。不同的品牌类型有不同的评价方法, 在研究企业农产品时, 主要采用模糊综合评价法[6-9]和Interband品牌评估法[10-14]。在研究区域农产品和种类农产品时, 主要采用模糊综合评价法和灰色层次模型[5,15]。
②影响因素角度。影响因素是评价体系的一部分, 有些文献着重研究了影响品牌评价的因素, 将这些因素构成评价体系, 分别打分来确定品牌价值[11, 16-17]。
③评价模型角度。学者提出很多测评模型评价农产品的品牌价值, 包括多元回归模型[18]、TOPSIS模型[19]、结构方程模型[20]、品牌资产十要素模型[21]等。
(2) 对文献进行分析时常采用文献计量学方法[22], 分析时首先要进行文献统计, 统计的对象为文献或作者具备的某些特征[23], 如标题、关键词、合著者、引文、注释等[24-25], 或者是因对象而产生的某些行为[26], 如阅读量、被引情况、被收录情况等[27-28]。本文重点使用文献聚类方法。文献聚类通常针对题名或关键词进行[29], 传统的文献聚类方法主要分为两类: 层次聚类[30-31]和划分聚类[32-33]。层次聚类的主要思想是将分析对象按照某种规则聚集为一棵聚类树[34-36]; 划分聚类的主要思想是将分析对象划分为多个簇, 每个簇中的对象高度相似, 并且簇间尽量保持不一致, 如K-means算法[37-38]。随着人工智能的兴起, 模糊聚类、人工神经网络聚类和演化式聚类法等其他聚类方法也被应用到文献聚类中[39]。
本文的数据来源于CNKI(中国知网)的中国学术期刊网络出版总库, 调查文献的范围为“农产品品牌评价”, 检索时间为2016年10月17日。使用检索式“篇名=农产品 and 篇名=品牌 and 篇名=评价”, 共得到27篇文献, 由于文献数目过少不利于后续分析, 将检索式调整为“主题=农产品 and 主题=品牌 and 主题=评价”, 最终得到360篇文献, 但经人工检查发现这些文献有很大一部分与主题关联性较小, 故考虑使用中图分类号检索扩大文献范围。前期调研中发现相关文献的分类号主要有“F224经济数学方法”、“F323.5农业商品生产及农业劳动生产率”、“F326农业部门经济”三种, 因此使用高级检索式“CLC=F224+F323.5+F326 AND TI=‘品牌*评价’ ”, 最终得到153篇文献。为了确保检索式覆盖较为全面, 将这153篇文献与使用最初检索检索式得到的27篇文献进行比对, 发现共有22篇重合, 去除重合文献后共得到158篇文献。在这158篇文献中, 去除1篇重复投稿的文献, 1篇由于来源库不一样被重复收录的文献以及2篇新闻稿, 最终得到有效的文献数据154条, 以这154篇文献的题名作为原始数据进行具体分析。
本文对所有文献进行数据清洗以去除重复文献及新闻稿等题材不符合要求的文章, 利用ICTCLAS软件对题名进行分词, 得到397个词汇; 根据哈尔滨工业大学的停词表去除停用词后可获得350个有效词汇, 运用这些数据, 将文献包含的词汇赋为1, 不包含的赋为0, 形成一个154×350的文献-术语矩阵(Document- Term Matrix, DTM), 再对DTM进行K-means聚类解析各簇的研究内容。K-means是质心的聚类技术, 其聚类效率高, 可以有效处理大文本集。接着对聚类得到的7个簇进行因子分析(Factor Analysis, FA)、多维尺度分析(Multidimensional Scaling Analysis, MSA)和层次聚类(Hierarchical Clustering, HC), 深入探究各簇特点。因子分析是指从变量群中提取共性因子的统计技术, 旨在以较少的因子反映原资料的大部分信息[40]。多维尺度分析通过低维空间展示研究对象间的联系, 利用平面距离反映研究对象之间的相似程度[41]。层次聚类试图在不同层次对数据集进行划分, 从而形成树形的聚类结构[42]。
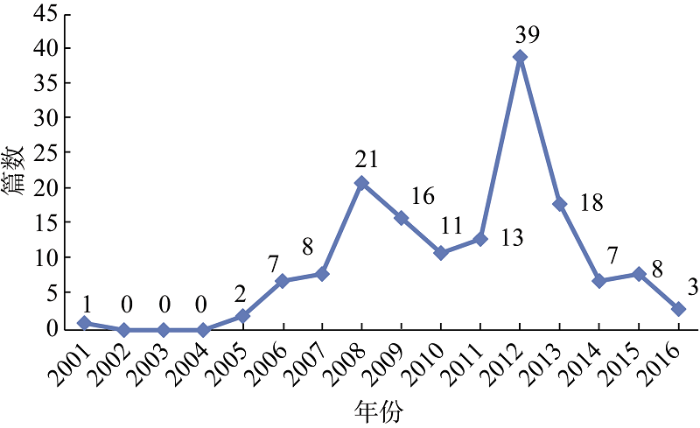
对所有文献的年度分布进行分析, 如图1所示。
(1) 该领域的文献数量变化总体呈现“M”型趋势。
(2) 该领域在2001年首次出现相关文献但只有1篇, 且2002年-2004年期间无相关文献, 表明实际上该领域的研究在这一时期并未完全起步。
(3) 文献数量自2005年起迅速增加, 说明研究热度迅速上升, 可能是由于国家重视农业的发展, 颁布了一系列相关政策, 如“三农政策”和“十一五”规划, 使得学者开始关注农产品品牌的评价。
(4) 文献数量在2008年达到一个小高峰, 之后开始缓慢回落, 这表明当时研究热度开始减退。
(5) 到了2012年, 该领域的发文数量出现了一个井喷式的高峰, 达到39篇, 原因可能为2011年起出台了一系列政策加大对农业的扶持力度。在此之后文献数量快速减少, 可能是该研究已经过了热门期, 但由于文献数量只统计到2016年10月17日, 未来的文献数量变化还有待后续观察。
本文用ICTCLAS①(①http://ictclas.nlpir.org/.)对检索所得的154篇文献的题名进行分词并去除停用词, 获得350个有效词汇, 运用这些数据, 将文献提及的词汇赋为1, 未提及的赋为0, 形成一个154×350的DTM, 并使用MATLAB对DTM进行K-means聚类。聚类时由于类数是人为设定的, 可能和实际适合的类数并不一致, 且初始的聚类中心是随机的, 所以虽然聚类得到的类别不变, 但是每类的文献数量会随机变化; 如果设置的类目数过多, 部分类目只有少量文章, 不利于展开分析; 如果类目数过少, 每类的文章数都较多, 聚类效果不明显。考虑到本实验数据量以及方便后续分析, 将154个题名分为7类, 并针对其中一次随机的聚类结果进行分析。
K-means聚类情况如图2所示。
通过对聚类结果进行分析, 得到各簇的聚类中心词, 如表1所示。
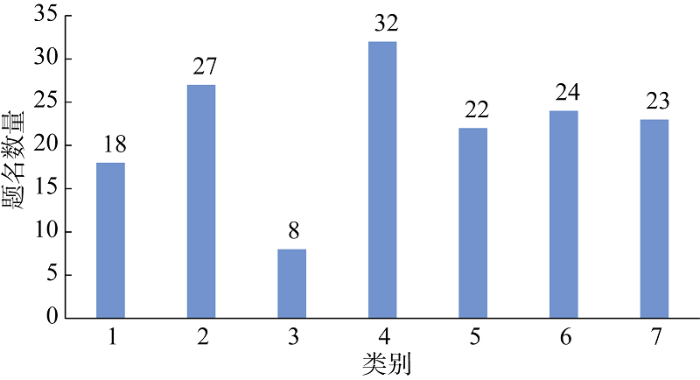
表1 农产品品牌价值研究的题名聚类结果
| 簇编号 | 篇数 | 聚类中心词 |
|---|---|---|
| C_1 | 18 | 体系; 指标; 研究; 竞争力; 构建 |
| C_2 | 27 | 竞争力; 研究; 农产品; 模型; 企业 |
| C_3 | 8 | 例; 农产品; 城市; 分析; 关联; 灰色 |
| C_4 | 32 | 研究; 影响; 方法; 联合; 模糊; 模式 |
| C_5 | 22 | 消费者; 研究; 延伸; 影响; 产品; 实证 |
| C_6 | 24 | 模糊; 综合; 法; 研究; 竞争力; 农产品 |
| C_7 | 23 | 模型; 价值; 研究; 视角; 消费者; 理论 |
(1) C_1的主要研究内容为农产品品牌评价指标体系的构建, 这些文献基本都使用层次分析法将目标分解为不同层次的多个指标, 分别赋予权重以进行定性或定量分析。
(2) C_2共含27篇文献, 约占总体的17.5%, 是该领域的一个研究热点。该簇研究了农产品品牌竞争力的评价模型, 多数研究从案例出发对企业的品牌竞争力进行评价。C_2与C_1由于使用不同术语“评价指标体系”与“评价模型”而被分为两簇, 实际研究内容相近。
(3) C_3的聚类中心词中出现了“城市”和“灰色”,是因为该簇多以城市为案例进行品牌评价分析, 聚类词中的“灰色”除灰色评价外还涉及灰色关联、灰色系统等概念, 灰色是指系统具有的层次或结构关系的模糊性、动态变化的随机性、指标数据的不完备或不确定性。该簇大部分文献为区域农产品的实证研究。
(4) C_4主要研究了影响品牌评价方法的因素。影响因素是评价体系的一部分, 该簇文献着重研究了影响品牌评价的因素, 将这些因素构成评价体系, 分别打分来确定品牌价值。C_4与农产品品牌评价联系最紧密, 但内容相对分散, 以影响品牌评价方法的因素为研究内容, 特征并不突出。
(5) C_5研究了消费者角度的品牌延伸评价, 该簇包含一些以非农产品为评价对象的文献, 原因是检索式包含的中图分类号“F224经济数学方法”无法将研究对象完全限制在农产品领域, 但这些文献可以为农产品品牌评价提供借鉴; 该簇对品牌评价的研究切入点相对较小, 包括部分实证研究。
(6) C_6主要使用模糊综合法对农产品竞争力进行评价, 部分文献也构建了层次分析模型, C_6较其他簇而言内容更集中。
(7) C_7着重研究了消费者视角的品牌价值模型, 突出了消费者在品牌价值评价中的地位。
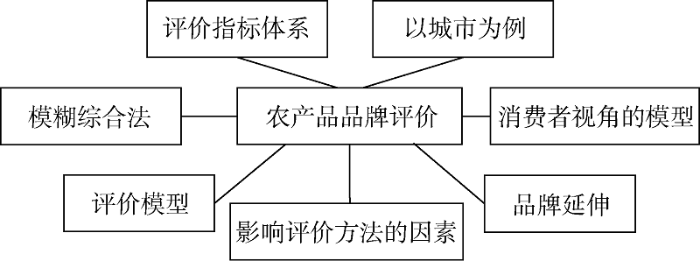
结合聚类中心词和上述分析对每簇内容进行总结, 得到的聚类标签如图3所示。
可以发现, 该领域的研究集中在评价指标体系、评价模型、影响因素等方面。与综述中主观总结的研究现状相比, 聚类结果存在以下差异:
(1) 品牌类型。聚类结果未体现出对种类农产品的评价, 原因为相关文献的题名往往会涉及种类农产品的具体名称, 且由于品牌名称之间差异较大, 或题名本身并未包含研究对象, 无法通过题名聚为一类, 形成聚类标签; 此外, 由于种类农产品这一概念与区域农产品、企业农产品存在交叉重叠, 当某一品牌可以看做区域或企业农产品进行分析时, 研究者一般很少选择将其看为种类农产品进行研究。
(2) 评价方法。Interband品牌评价法是评价企业农产品最常用的方法之一, 但聚类结果则未体现这一特点, 主要原因是该领域文献在命名时(如《卷烟品牌评价体系实证研究——以G和Z卷烟品牌为例》)未涉及评价所使用的具体方法名称; 农产品品牌评价的方法有很多, 从聚类结果看, 实际使用最多的为模糊综合法。
(3) 评价视角。聚类结果更突出消费者的作用, 其中C_5和C_7两簇(共计45篇文献)涉及了消费者角度的品牌评价。
(4) 涉及因素。从聚类结果可以看出品牌评价的侧重点更多样化, 除了品牌竞争力之外, 不少文献涉及品牌延伸、品牌价值等, 说明研究者常使用它们替代品牌评价的概念。
(5) 文献研究层次。聚类结果体现出农产品品牌评价并不局限于理论, 相当一部分研究对构建的模型进行了实践, 这对建立一个普适性的农产品品牌评价的模型有一定的参考价值。
以术语为案例, 文献为变量, 将DTM转化为文献- 文献矩阵(Document-Document Matrix,DDM)。按照4.2节的聚类结果, 对每个簇分别进行因子分析、多维尺度分析和层次聚类分析, 抽取每个簇的重点探讨内容, 并将其与上文设定的聚类标签比较、分析, 以深入研究各簇特点。多维尺度分析的结果中有两个参数: Stress和RSQ, 前者表示信度, 后者表示拟合效果。本文所有的Stress值均在0.2左右, RSQ值均在0.8以上, 拟合效果较好。
(1) C_1的内容解析
在C_1的因子分析中, 将负载临界值设定为0.4, 以较好地反映主要成分, 另外6类也是如此, 结果如表2所示。
表2 C_1的因子分析结果(负载值>0.4)
| 1 | 2 | 3 | |
|---|---|---|---|
| K_36 | 0.799 | ||
| K_103 | 0.754 | ||
| K_101 | 0.712 | ||
| K_146 | 0.706 | ||
| K_17 | 0.703 | ||
| K_102 | 0.701 | ||
| K_58 | 0.697 | ||
| K_56 | 0.691 | ||
| K_154 | 0.538 | ||
| K_70 | 0.438 | ||
| K_92 | 0.400 | 0.716 | |
| K_122 | 0.700 | ||
| K_79 | 0.610 | ||
| K_39 | 0.590 | ||
| K_60 | 0.511 | 0.585 | |
| K_29 | 0.715 | ||
| K_89 | 0.578 | ||
| K_32 | 0.563 | 0.574 |
①因子1为评价指标体系, 研究对象主要为企业农产品、区域农产品, 该因子在大多数文献中均有涉及, 是主要因子。
②因子2为评价模型的构建, 文献基本都结合了具体案例, 主要针对区域农产品进行研究。
③因子3为评价体系与评价模型的相关内容, 比较松散。
C_1文献的内容大多较为集中, 只有3篇分散在2个因子上: K_92与K_60同时出现在了因子1、2中, K_92在因子1(评价指标体系)上的负载值比因子2(评价模型的构建)低, 其题名为《农产品品牌竞争力评价指标体系及评价方法的构建》, 该文献研究了评价指标体系以及评价模型的构建, 更偏重于构建评价模型(评价方法); K_60题名为《品牌综合评价指标体系及方法》, 主要运用因子分析法提出品牌综合评价的指标体系, 由于题名同时出现了“评价指标体系”和“方法”, 所以在2个因子负载值相对较为均衡, 实际上“评价指标体系”与“评价模型”概念上有重叠, 只是使用术语不同。负载值最高的文献K_36题名为《基于Dirichlet模型的品牌竞争力综合评价指标体系研究》, 从品牌的市场表现、品牌的管理能力、品牌的基础能力和宏观环境要素4方面建立了品牌竞争力综合评价指标体系, 研究对象为马氏、金地、费列罗三个企业品牌, 与因子1的内容高度契合。
C_1的文献主要运用层次分析法, 从品牌的不同评价方面提出指标构建评价指标体系。部分文献对已构建的评价指标体系做了实证研究, 并采用专家打分法、问卷调查法或访谈的方式, 对每个指标赋予一定权重, 最终得出该品牌的测算值。半数文献构建模型或采用某种分析方法以辅助测算品牌价值, 如Dirichlet模型、KANO模型、因子分析法等。值得注意的是题名不能完全揭示文章内容, 如K_70题名为《卷烟品牌评价体系实证研究——以G和Z卷烟品牌为例》, 使用了评价企业农产品最常用的方法之一的Interband评价法, 而题名并未体现这一内容。
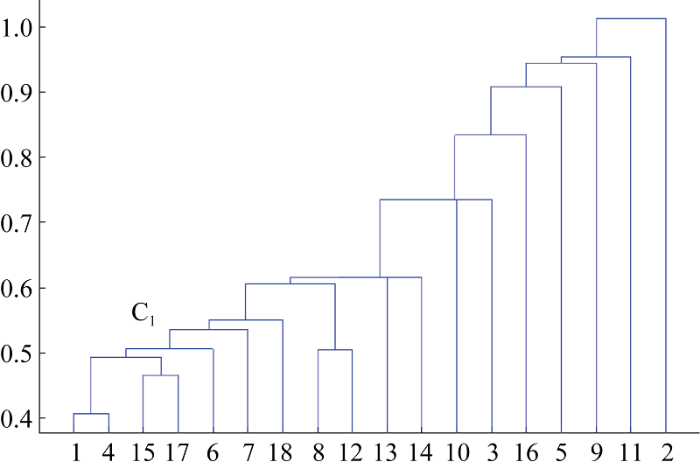
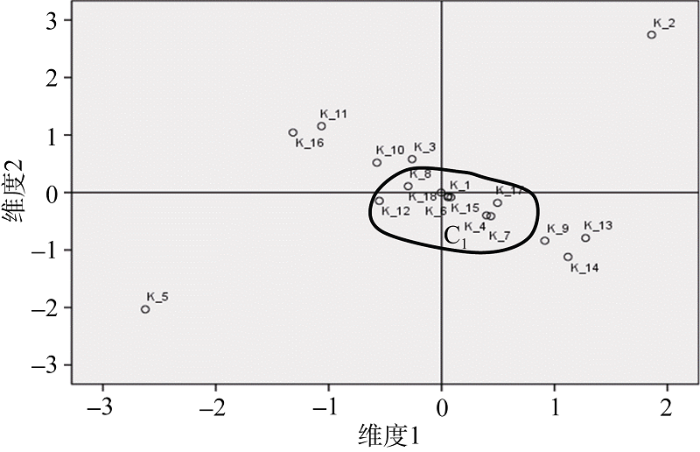
随后对C_1进行层次聚类和多维尺度分析, 并将文献较为集中的部分记作C1, 结果如图4和图5所示。
C1包含的文章集中探讨了品牌评价指标体系, 2篇在题名中指出了具体模型, 4篇是综述性文献, 1篇是河北省农产品的品牌评价指标体系研究。总体上看, 该簇主要从宏观角度进行具体研究, 部分文献结合实例进行定性分析。另外, 有2篇文章与聚类中心距离较远, 其题名分别为《服装品牌竞争优势评价体系各维度的权重分布设计》和《电信企业服务质量感知的评价指标体系和方法——以重庆市某运营商A品牌为例》, 从题名看虽然都提及了“评价指标体系”, 但是评价对象分别为服装品牌、运营商品牌, 与农产品品牌差距较大。
(2) 其他簇的内容解析
前文以C_1为例详细分析了因子分析、层次聚类、多维尺度分析结果, 受篇幅限制, 本小节对其他6簇的分析结果进行总结, 不展开详细描述, 着重探讨各簇的特点.
①评价角度。农产品品牌的评价主要从品牌竞争力、品牌强度(C_4部分文献的研究重点)、品牌联合(C_4)、品牌延伸(C_5)、品牌价值(C_7)等方面进行, 大部分簇(C_1、C_2、C_3、C_6)着重研究了品牌竞争力, 说明品牌竞争力是评价的重点, 但学者也会使用品牌强度等概念来替代竞争力。
②品牌类型。研究主要针对区域农产品和企业农产品进行, C_2着重研究了某省市的农产品品牌和林果、蔬菜、乳制品、食品等行业的企业品牌; C_3主要研究了城市中的一些企业品牌; C_4的研究对象主要为区域农产品品牌; C_2和C_6分别有一篇文献研究了种类农产品。
③研究角度。C_1、C_2和C_6侧重于模型使用, 模型比较多样化; C_3的文献基本都结合具体案例进行实证; C_4的研究基本为综述性的, 部分文献进行实证。
④题名。由于C_4主要进行综述性研究, 其包含的文献题名都较为概括, 未指出使用的方法和评价角度; 而C_1、C_2、C_6、C_7所含的文献基本都指明了模型和具体评价对象。
⑤评价方法。C_6中包含的文献基本都使用了模糊综合法, 这些文献还将该方法与其他模型相结合以辅助分析, 如AHP与模糊层次综合分析法结合、灰色模型与模糊层次分析法结合。
⑥离散程度。C_3和C_7较为分散, 其他几簇都较为集中: C_3仅包含8篇文献, 数量较少, 这些文献探讨了品牌的形成要素、竞争力、名称等多个方面, 内容丰富、相距较大; C_7除农产品品牌外还包含建筑企业品牌、国际知名品牌等, 使用的模型、评价的角度差距较大, 因此内容较为分散; 簇C_4集中研究了评价方法的影响、评价的影响因素、品牌的某个方面的评价(例如影响力、满意度、配送模式等); C_5突出了消费者的地位, 评价角度基本为品牌延伸, 研究基本围绕消费者对品牌延伸的评价(结合实证)和消费者视角的品牌延伸的影响因素进行; C_6的文献针对品牌竞争力使用模糊综合法评价。
本文统计了中国农产品品牌评价领域相关文献的年度发文趋势, 分析了相关政策、自然灾害等因素对农产品品牌评价研究的影响; 使用MATLAB对DTM进行K-means聚类, 分析了每簇研究的内容并与综述比较; 对每个簇分别进行因子分析、多维尺度分析和层次聚类分析, 探讨了每簇的特点。
从分析结果可以看出, 中国农产品品牌评价领域的文献数量总体呈现“M”型趋势。对题名进行K-means聚类, 划分为7类, 研究的主要内容分别为: 农产品品牌竞争力评价体系的构建、品牌竞争力评价模型、品牌评价的实证研究、影响品牌评价的因素、消费者视角的品牌延伸研究、基于模糊综合法和层次分析模型的品牌评价、消费者视角的品牌价值模型研究。
经过分析发现该领域的研究集中在评价指标体系、评价模型、影响因素等方面。与综述中主观总结的研究现状相比, 聚类结果存在以下差异: 品牌类型方面, 聚类结果中未体现出对种类农产品的评价; 评价方法方面, 聚类结果并未体现出Interband品牌评价法, 此外, 实际研究中使用最多的方法为模糊综合法; 评价视角方面, 聚类结果更突出消费者的作用; 涉及因素方面, 品牌评价的侧重点更多样化, 学者经常使用品牌延伸、品牌价值等替代品牌评价的概念; 文献研究层次方面, 相当一部分研究对品牌评价模型进行实证, 这对建立一个普适性的农产品品牌评价的模型有一定的参考价值。同时, 对各簇进行多维尺度分析、层次聚类后分别从评价角度、品牌类型、研究角度、题名、评价方法、离散程度解析了每簇特点。
本文还存在以下问题: 分析仅针对题名进行。这是由于摘要文字较多, 对其聚类计算量较大, 用短文本替代较为科学。对题名和关键字的对比研究笔者已另行撰文, 作为本文的后续研究。
王雪颖: 提出研究思路, 采集、清洗和分析数据, 起草论文;
王雪颖, 张紫玄: 进行实验;
王昊: 设计研究方案;
邓三鸿: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: mg1614024@smail.nju.edu.cn。
[1] 王雪颖. K均值结果统计.xlsx. K-means聚类结果统计表.
[2] 王雪颖. 停词后数据.xlsx. 对文献题名去除停用词后得到的数据.
[3] 王雪颖. 文档词矩阵.xlsx. 文档-术语矩阵.
[4] 王雪颖. DDM.xlsx. 文献-文献矩阵.
[5] 王雪颖. k1.sav. 簇1的文档-术语矩阵.
[6] 王雪颖. k2.sav. 簇2的文档-术语矩阵.
[7] 王雪颖. k3.sav. 簇3的文档-术语矩阵.
[8] 王雪颖. k4.sav. 簇4的文档-术语矩阵.
[9] 王雪颖. k5.sav. 簇5的文档-术语矩阵.
[10] 王雪颖. k6.sav. 簇6的文档-术语矩阵.
[11] 王雪颖. k7.sav. 簇7的文档-术语矩阵.
[12] 王雪颖. data.dbf. 相关文献的题名.
[13] 王雪颖. stopword.dbf. 停用词表.
| [1] |
农产品区域品牌竞争力评价研究 [D].Research on Competitiveness Evaluation of Agricultural Products Regional Brand [D]. |
| [2] |
农产品区域品牌竞争力提升研究 [J].Research on Competitiveness Promotion of Agricultural Products Regional Brand [J]. |
| [3] |
新疆特色农产品品牌竞争力评价研究——基于模糊层次分析法 [J].
品牌竞争力评价是品牌价值评价的重要途径,也是农产品核心竞争力的主要体现,文章在提出农产品品牌竞争力因素指标体系的基础上,建立了基于模糊层次分析法的新疆农产品品牌竞争力评价模型,并利用这一评价模型对新疆特色农产品品牌竞争力进行了评定,评定结果为新疆特色农产品品牌竞争力处于一般,接近于较好状态.通过该模型明确了提升新疆特色农产品品牌竞争力努力的方向,进而又提出了提升其竞争力的策略,以期其获得更大的竞争优势.
Research on Brand Competitiveness Evaluation of Characteristic Agricultural Products in Xinjiang: Based on Fuzzy Analytic Hierarchy Process [J].
品牌竞争力评价是品牌价值评价的重要途径,也是农产品核心竞争力的主要体现,文章在提出农产品品牌竞争力因素指标体系的基础上,建立了基于模糊层次分析法的新疆农产品品牌竞争力评价模型,并利用这一评价模型对新疆特色农产品品牌竞争力进行了评定,评定结果为新疆特色农产品品牌竞争力处于一般,接近于较好状态.通过该模型明确了提升新疆特色农产品品牌竞争力努力的方向,进而又提出了提升其竞争力的策略,以期其获得更大的竞争优势.
|
| [4] |
安化黑茶区域公用品牌价值评估研究 [D].Evaluation of Area Public Brand Value of Anhua Black Tea [D]. |
| [5] |
福建农产品品牌竞争力评价 [D].Evaluation on the Competitiveness of Agricultural Products in Fujian [D]. |
| [6] |
基于模糊综合评价模型的区域农产品品牌建设水平研究 [D].Study on the Brand Building Level of Regional Agricultural Products Based on Fuzzy Comprehensive Evaluation Model [D]. |
| [7] |
我国农产品品牌结构评估模型及影响因子研究——基于AHP-模糊综合评价法的实证分析 [J].URL 摘要
文章通过主成分分析,找到影响农产品品牌结构形成的关键因素,在此基础上形成评估模型,并采用德尔菲法对模型进行完善。其次,基于AHP-模糊综合评价法,对福建省四个地级市液态奶市场的调查数据进行数据处理,验证模型。最后通过变化假设,对检验过的模型进行应用验证。结果显示:在影响农产品品牌结构评价因子中,"企业实力"、"与目标群的契合度"、"现有科研能力"、"客户成熟度"、"消费者主观认知创新"是最核心影响因子。表明,农产品品牌应从以上5个指标提高品牌能力,并配合其他指标提高品牌结构的科学性,才能建构品牌结构的竞争力,形成强势品牌资产。
Study on Evaluation Model and Influencing Factors of Agricultural Product Brand Structure in China: An Empirical Analysis Based on AHP-Fuzzy Comprehensive Evaluation Method [J].URL 摘要
文章通过主成分分析,找到影响农产品品牌结构形成的关键因素,在此基础上形成评估模型,并采用德尔菲法对模型进行完善。其次,基于AHP-模糊综合评价法,对福建省四个地级市液态奶市场的调查数据进行数据处理,验证模型。最后通过变化假设,对检验过的模型进行应用验证。结果显示:在影响农产品品牌结构评价因子中,"企业实力"、"与目标群的契合度"、"现有科研能力"、"客户成熟度"、"消费者主观认知创新"是最核心影响因子。表明,农产品品牌应从以上5个指标提高品牌能力,并配合其他指标提高品牌结构的科学性,才能建构品牌结构的竞争力,形成强势品牌资产。
|
| [8] |
内蒙古农产品区域品牌竞争力提升研究 [D].
Study on Advancing Competitiveness of Regional Brand of Agricultural Products in Inner Mongolia [D].
|
| [9] |
新疆特色农产品品牌竞争力提升研究). [J].
特色农产品指的是区域特征明显,存在多元化特点,同时为众多领域生产提供原材料的服务型农产品.尤其在新疆,更富含了资源丰富产品,但是长时间来,由于销售、加工与储备等很多因素影响,其农业生产仍然长时间处在附加值低、规模小及投入少阶段,就会对其产业式经营构成阻碍.追根溯源,主要是因为其品牌经营模式不够成熟所致.品牌经营核心之处就在于对品牌的创造与运作.而营销学角度则指的是把品牌看作独立资本与资源,同时由此主导,对其它资本与资源进行整合,进一步收获最大社会与经济效益.
Research on the Enhancement of Brand Competitiveness of Characteristic Agricultural Products in Xinjiang [J].
特色农产品指的是区域特征明显,存在多元化特点,同时为众多领域生产提供原材料的服务型农产品.尤其在新疆,更富含了资源丰富产品,但是长时间来,由于销售、加工与储备等很多因素影响,其农业生产仍然长时间处在附加值低、规模小及投入少阶段,就会对其产业式经营构成阻碍.追根溯源,主要是因为其品牌经营模式不够成熟所致.品牌经营核心之处就在于对品牌的创造与运作.而营销学角度则指的是把品牌看作独立资本与资源,同时由此主导,对其它资本与资源进行整合,进一步收获最大社会与经济效益.
|
| [10] |
中国农产品品牌价值评估实证分析——以伊利、蒙牛、光明三家上市企业为例 [J].An Empirical Analysis on the Evaluation of Chinese Agricultural Products’ Brand Value - A Case Study of Erie, Mengniu and Guangming Listed Companies [J]. |
| [11] |
河北省农产品品牌价值评价指标体系研究 [D].Study on Evaluation Index System of Agricultural Products Brand Value in Hebei Province [D]. |
| [12] |
基于Interbrand模型的品牌价值研究 [D].
Research on Brand Value Based on Interbrand Model [D].
|
| [13] |
基于Interbrand模型的山西农产品地理标志品牌价值评估 [J].https://doi.org/10.13872/j.1000-0275.2015.0037 URL 摘要
品牌能兴农,商标能富农,发展农产品地理标志对优化农业结构,提升农业竞争力有重要作用。以山西省某地理标志农产品为例,基于2008-2012年农产品地理标志使用企业的生产销售数据和基层管理部门的宏观数据,采用Interbrand模型测算了农产品地理标志价值。结果表明,该农产品地理标志价值2849.8万元,品牌处于成长期;沉淀收益增长趋势良好,销售量成为其增长的关键因素,但品牌强度实力中等偏弱,市场地位、行销范围、品牌趋向的竞争优势发挥有限。随着沉淀收益较好增长势头继续保持,品牌强度中不足因素逐步完善,品牌价值具有较大提升空间。据此,提出了企业应发挥现有贸易格局优势,优选品牌化战略,提升品牌竞争力;政府应提供"订制式"服务,完善政策支持体系,企业完善品牌保护体系等政策建议。
Evaluation of Brand Value of Geographical Indications of Shanxi Agricultural Products Based on Interbrand Model [J].https://doi.org/10.13872/j.1000-0275.2015.0037 URL 摘要
品牌能兴农,商标能富农,发展农产品地理标志对优化农业结构,提升农业竞争力有重要作用。以山西省某地理标志农产品为例,基于2008-2012年农产品地理标志使用企业的生产销售数据和基层管理部门的宏观数据,采用Interbrand模型测算了农产品地理标志价值。结果表明,该农产品地理标志价值2849.8万元,品牌处于成长期;沉淀收益增长趋势良好,销售量成为其增长的关键因素,但品牌强度实力中等偏弱,市场地位、行销范围、品牌趋向的竞争优势发挥有限。随着沉淀收益较好增长势头继续保持,品牌强度中不足因素逐步完善,品牌价值具有较大提升空间。据此,提出了企业应发挥现有贸易格局优势,优选品牌化战略,提升品牌竞争力;政府应提供"订制式"服务,完善政策支持体系,企业完善品牌保护体系等政策建议。
|
| [14] |
Interbrand品牌评估法评介 [J].Review of Interbrand Brand Evaluation [J]. |
| [15] |
山东省农产品品牌竞争力评价研究 [D].Study on Evaluation of Brand Competitiveness of Agricultural Products in Shandong Province [D]. |
| [16] |
影响农产品区域品牌形成的要素评价——以河南省为例 [J].https://doi.org/10.15889/j.issn.1002-1302.2016.08.151 URL [本文引用: 1] 摘要
由于农产品销售领域的竞争日益激烈,已从简单的价格竞争转向了复杂的品牌竞争,又因农产品具有的地域依赖性,使得培育农产品区域品牌成为必然趋势.通过构建影响农产品区域品牌形成的要素评价体系,运种分析方法,并基于对我国农业大省河南省农产品区域品牌的抽样调查问卷数据,找出影响农产品区域品牌形成要要素.结果表明,市场需求、农业科技、资金这3个要素对农产品区域品牌形成起着决定性影响作用.在此基提出促进农产品区域品牌形成的对策建议.
An Evaluation of the Factors Affecting the Formation of Regional Brand of Agricultural Products - Taking Henan Province as an Example [J].https://doi.org/10.15889/j.issn.1002-1302.2016.08.151 URL [本文引用: 1] 摘要
由于农产品销售领域的竞争日益激烈,已从简单的价格竞争转向了复杂的品牌竞争,又因农产品具有的地域依赖性,使得培育农产品区域品牌成为必然趋势.通过构建影响农产品区域品牌形成的要素评价体系,运种分析方法,并基于对我国农业大省河南省农产品区域品牌的抽样调查问卷数据,找出影响农产品区域品牌形成要要素.结果表明,市场需求、农业科技、资金这3个要素对农产品区域品牌形成起着决定性影响作用.在此基提出促进农产品区域品牌形成的对策建议.
|
| [17] |
关于农产品品牌价值评价体系构建及分析 [J].https://doi.org/10.3969/j.issn.1003-0662.2012.03.014 URL [本文引用: 1] 摘要
一、品牌价值的内涵 20世纪70年代以来,品牌价值一直是西方营销学者和企业家共同关注的焦点领域,被视为竞争优势的新来源。不同的学者从不同的角度对品牌价值进行了界定,赋予了不同的涵义,归纳起来,主要有以下观点。
Construction and Analysis of Brand Value Evaluation System of Agricultural Products [J].https://doi.org/10.3969/j.issn.1003-0662.2012.03.014 URL [本文引用: 1] 摘要
一、品牌价值的内涵 20世纪70年代以来,品牌价值一直是西方营销学者和企业家共同关注的焦点领域,被视为竞争优势的新来源。不同的学者从不同的角度对品牌价值进行了界定,赋予了不同的涵义,归纳起来,主要有以下观点。
|
| [18] |
如何评估农产品品牌竞争力 [J].https://doi.org/10.3969/j.issn.1002-6487.2007.02.020 URL [本文引用: 1] 摘要
本文以农产品的品牌竞争力为研究对象,结合中国农产品品牌的发展现状,在提出农产品品牌竞争 力概念的基础上,分析影响农产品品牌竞争力的因素,突破国内现有对品牌竞争力评价的方法,利用主成分分析法对影响农产品品牌竞争力的因素的历史资料进行收 集,并在此基础上提出了评价农产品品牌竞争力的多元回归模型。
How to Evaluate the Competitiveness of Agricultural Products [J].https://doi.org/10.3969/j.issn.1002-6487.2007.02.020 URL [本文引用: 1] 摘要
本文以农产品的品牌竞争力为研究对象,结合中国农产品品牌的发展现状,在提出农产品品牌竞争 力概念的基础上,分析影响农产品品牌竞争力的因素,突破国内现有对品牌竞争力评价的方法,利用主成分分析法对影响农产品品牌竞争力的因素的历史资料进行收 集,并在此基础上提出了评价农产品品牌竞争力的多元回归模型。
|
| [19] |
基于熵权-灰色关联-TOPSIS的达州特色农产品品牌综合评价 [J].Comprehensive Evaluation of Dazhou Characteristic Agricultural Products Brand Based on Entropy Weight- Gray Relation-TOPSIS [J]. |
| [20] |
新疆特色农产品区域品牌:形成机理、效应及提升对策研究 [D].Regional Brand of Xinjiang Characteristic Agricultural Products: Mechanism, Effect and Countermeasures [D]. |
| [21] |
基于“十要素模型”的嘉和一品公司品牌资产评估实证研究 [C]//An Empirical Study on Brand Equity Evaluation of JiaheYipin Company Based on “Ten Factors Model” [C]// |
| [22] |
文献计量与内容分析——文献群中隐含信息的挖掘 [J].https://doi.org/10.3969/j.issn.0252-3116.2005.06.004 URL [本文引用: 1] 摘要
在对文献计量和内容分析进行特征归纳与比较的基础上,提出这两种研究方法所具备的一致性逻辑,即:通过借助于某种直观的或选定的形式化体系及定义在此形式化体系之上的运算集,对文献的某些外部特征与粗略内容特征进行量化统计,力图发现附着在大量文献群背后的隐含信息;探讨这两种方法在应用中必须满足的、隐含的预设前提;认为文献计量和内容分析都可以归并到信息计量与分析的类属下,发挥各自优势,进行理论、方法与应用的综合.
Bibliometrics and Content Analysis - Mining of Implicit Information in Literature Group [J].https://doi.org/10.3969/j.issn.0252-3116.2005.06.004 URL [本文引用: 1] 摘要
在对文献计量和内容分析进行特征归纳与比较的基础上,提出这两种研究方法所具备的一致性逻辑,即:通过借助于某种直观的或选定的形式化体系及定义在此形式化体系之上的运算集,对文献的某些外部特征与粗略内容特征进行量化统计,力图发现附着在大量文献群背后的隐含信息;探讨这两种方法在应用中必须满足的、隐含的预设前提;认为文献计量和内容分析都可以归并到信息计量与分析的类属下,发挥各自优势,进行理论、方法与应用的综合.
|
| [23] |
基于文献计量学的我国档案专业核心期刊分析与评价 [D].Analysis and Evaluation of Core Journals of Archives in China Based on Bibliometrics [D]. |
| [24] |
我国产业技术创新战略联盟研究的文献分析(2007-2012) [J].https://doi.org/10.3969/j.issn.1008-0821.2013.03.025 URL [本文引用: 1] 摘要
产业技术创新战略联盟是近年来 我国政府为提高产业技术创新能力而提出并且首倡的一种新型的技术创新合作组织,是实施国家技术创新工程的重要载体。本文对2007-2012年我国产业技 术创新战略联盟研究文献的年度分布、作者情况、发文机构、期刊分布以及主题内容等进行统计与分析,以此了解我国对产业技术创新战略联盟的研究状况,为未来 研究和实践提供参考。
Literature Analysis on the Strategic Alliance of Industrial Technology Innovation in China (2007-2012) [J].https://doi.org/10.3969/j.issn.1008-0821.2013.03.025 URL [本文引用: 1] 摘要
产业技术创新战略联盟是近年来 我国政府为提高产业技术创新能力而提出并且首倡的一种新型的技术创新合作组织,是实施国家技术创新工程的重要载体。本文对2007-2012年我国产业技 术创新战略联盟研究文献的年度分布、作者情况、发文机构、期刊分布以及主题内容等进行统计与分析,以此了解我国对产业技术创新战略联盟的研究状况,为未来 研究和实践提供参考。
|
| [25] |
2005-2014年我国图书馆法研究的文献分析 [J].https://doi.org/10.3969/j.issn.1008-0821.2015.05.022 URL [本文引用: 1] 摘要
通过CNKI检索了2005-2014年关于我国图书馆法研究的相关文献,按照文献年度数量、期刊载文数量、作者发文数量、被引频次等方面进行文献统计,并从5个方面对图书馆法研究的主题内容进行分析,指出几点研究中的不足。
A Literature Analysis of Library Law Research in China from 2005 to 2014 [J].https://doi.org/10.3969/j.issn.1008-0821.2015.05.022 URL [本文引用: 1] 摘要
通过CNKI检索了2005-2014年关于我国图书馆法研究的相关文献,按照文献年度数量、期刊载文数量、作者发文数量、被引频次等方面进行文献统计,并从5个方面对图书馆法研究的主题内容进行分析,指出几点研究中的不足。
|
| [26] |
基于文献分析的国内图书馆大数据应用研究述评 [J].https://doi.org/10.3969/j.issn.1002-1248.2014.11.016 URL Magsci [本文引用: 1] 摘要
大数据在图书馆的应用将是未来图书馆发展的必经之路,关于图书馆应用大数据技术的研究已经展开,现就目前已经出版的研究论文在出版来源、出版年代、引文、内容等方面作出分析,并提出已有研究的不足与对今后的前景展望,为后续深入研究提供参考借鉴。
A Review of the Application of Large Data in Domestic Libraries Based on Literature Analysis [J].https://doi.org/10.3969/j.issn.1002-1248.2014.11.016 URL Magsci [本文引用: 1] 摘要
大数据在图书馆的应用将是未来图书馆发展的必经之路,关于图书馆应用大数据技术的研究已经展开,现就目前已经出版的研究论文在出版来源、出版年代、引文、内容等方面作出分析,并提出已有研究的不足与对今后的前景展望,为后续深入研究提供参考借鉴。
|
| [27] |
基于文献分析的国内图书馆虚拟化技术研究述评 [J].https://doi.org/10.3969/j.issn.1002-1884.2013.05.052 URL [本文引用: 1] 摘要
虚拟化技术在国内图书馆的应用研究还属于探索阶段,以中国知网的 知识发现网络平台为工具,对近6年来发表在图书馆学期刊上的相关研究文章进行分析,从文献来源、发表时间、引文和研究方向等方面介绍了虚拟化技术在图书馆 学领域的应用研究现状,总结了目前研究所取得的主要成果,及存在的一些不足,并展望了未来的研究趋势,为今后的研究提供参考.
A Review of Domestic Library Virtualization Technology Based on Literature Analysis [J].https://doi.org/10.3969/j.issn.1002-1884.2013.05.052 URL [本文引用: 1] 摘要
虚拟化技术在国内图书馆的应用研究还属于探索阶段,以中国知网的 知识发现网络平台为工具,对近6年来发表在图书馆学期刊上的相关研究文章进行分析,从文献来源、发表时间、引文和研究方向等方面介绍了虚拟化技术在图书馆 学领域的应用研究现状,总结了目前研究所取得的主要成果,及存在的一些不足,并展望了未来的研究趋势,为今后的研究提供参考.
|
| [28] |
大数据研究的文献计量分析 [J].
笔者以2002-2012年间CNKI中国学术期刊网络出版总库中收录的大数据方面的论文为研究样本,借助多元统计分析工具Spss17.0中的聚类分析、多维尺度分析和Ucinet6可视化工具,从发文增长规律、作者分布、研究机构分布、期刊分布、以及高频关键词等多角度进行文献计量分析及可视化分析,揭示了我国在大数据领域的研究现状,并总结出研究特点,以期对大数据研究的深入开展和未来大数据的发展提供参考信息。
Bibliometric Analysis of Large Data Research [J].
笔者以2002-2012年间CNKI中国学术期刊网络出版总库中收录的大数据方面的论文为研究样本,借助多元统计分析工具Spss17.0中的聚类分析、多维尺度分析和Ucinet6可视化工具,从发文增长规律、作者分布、研究机构分布、期刊分布、以及高频关键词等多角度进行文献计量分析及可视化分析,揭示了我国在大数据领域的研究现状,并总结出研究特点,以期对大数据研究的深入开展和未来大数据的发展提供参考信息。
|
| [29] |
基于GN算法的文献聚类方法研究 [J].
文献是人类文化传播不可或缺的记录形式,文献结构研究的意义重大,有利于促进信息获取、知识交流和学术研究。本文将GN算法应用于文献聚类的研究当中,介绍了GN算法的步骤和文献聚类的过程,最后进行了聚类模型的演示,实验表明该文献聚类方法是有效的。
Research on Literature Clustering Method Based on GN Algorithm [J].
文献是人类文化传播不可或缺的记录形式,文献结构研究的意义重大,有利于促进信息获取、知识交流和学术研究。本文将GN算法应用于文献聚类的研究当中,介绍了GN算法的步骤和文献聚类的过程,最后进行了聚类模型的演示,实验表明该文献聚类方法是有效的。
|
| [30] |
基于文献聚类的211高校图书馆科研产出态势分析 [J].https://doi.org/10.3969/j.issn.1008-0821.2013.02.024 URL [本文引用: 1] 摘要
本文选择了112所"211工程"高校图书馆作为样本,统计了它们在2000-2010年发 表论文的数量、被引频次、下载频次、CSSCI论文数量、核心作者数、h指数等文献计量学指标;并在此基础上对112所高校图书馆进行聚类,通过分析比较 各类别的计量学指标特征,以期对我国著名高校图书馆的科研产出发展态势提供客观的分析。
A State-and-Trend Analysis on the Scientific Research Outputs of 211 University Libraries Based on Document Clustering [J].https://doi.org/10.3969/j.issn.1008-0821.2013.02.024 URL [本文引用: 1] 摘要
本文选择了112所"211工程"高校图书馆作为样本,统计了它们在2000-2010年发 表论文的数量、被引频次、下载频次、CSSCI论文数量、核心作者数、h指数等文献计量学指标;并在此基础上对112所高校图书馆进行聚类,通过分析比较 各类别的计量学指标特征,以期对我国著名高校图书馆的科研产出发展态势提供客观的分析。
|
| [31] |
基于文献聚类的高校科研成果量化分析 [J].https://doi.org/10.3969/j.issn.1008-0821.2011.06.029 URL [本文引用: 1] 摘要
高校图书馆依托文献资源优势,结合业务工作特点,采用文献计量的方法,从文献的角度对高校科学研究事业进行合理的评价,是高校图书馆开展信息服务、创新服务领域的重要形式之一。本文以湖北民族学院十一五期间发表的科研论文为研究对象,采用频次统计和聚类分析方法对提取出的样本数据进行了定量分析,并藉此为高校科学研究事业的健康发展提供数据支撑和理论支持。
Quantitative Analysis of University Scientific Research Results Based on Literature Clustering [J].https://doi.org/10.3969/j.issn.1008-0821.2011.06.029 URL [本文引用: 1] 摘要
高校图书馆依托文献资源优势,结合业务工作特点,采用文献计量的方法,从文献的角度对高校科学研究事业进行合理的评价,是高校图书馆开展信息服务、创新服务领域的重要形式之一。本文以湖北民族学院十一五期间发表的科研论文为研究对象,采用频次统计和聚类分析方法对提取出的样本数据进行了定量分析,并藉此为高校科学研究事业的健康发展提供数据支撑和理论支持。
|
| [32] |
基于文献聚类的国内外数字图书馆研究的比较分析 [J].A Comparative Analysis of Digital Library Research at Home and Abroad Based on Literature Clustering [J]. |
| [33] |
基于文献聚类的国内外知识传播研究主题分析 [J].An Analysis of the Subject of Knowledge Communication at Home and Abroad Based on Literature Clustering [J]. |
| [34] |
Segmentation of Terahertz Imaging Using K-means Clustering Based on Ranked Set Sampling [J].https://doi.org/10.1016/j.eswa.2014.11.050 URL [本文引用: 1] 摘要
Terahertz imaging is a novel imaging modality that has been used with great potential in many applications. Due to its specific properties, the segmentation of this type of images makes possible the discrimination of diverse regions within a sample. Among many segmentation methods, k -means clustering is considered as one of the most popular techniques. However, it is known that k -means is especially sensitive to initial starting centers. In this paper, we propose an original version of k -means for the segmentation of Terahertz images, called ranked- k -means, which is essentially less sensitive to the initialization of the centers. We present the ranked set sampling design and explain how to reformulate the k -means technique under the ranked sample to estimate the expected centers as well as the clustering of the observed data. Our clustering approach is tested on various real Terahertz images. Experimental results show that k -means clustering based on ranked set sampling is more efficient than other clustering techniques such as the k -means based on the fundamental sampling design simple random sampling technique, the standard k -means and the k -means based on the Bradley refinement of initial centers.
|
| [35] |
文献聚类分析及其在金属矿开采技术发展趋势发掘中的应用研究 [D].
Literature Clustering Analysis and Its Application in the Development of Metal Mining Technology [D].
|
| [36] |
DDBSCAN: Different Densities-Based Spatial Clustering of Applications with Noise [C]// |
| [37] |
Revised DBSCAN Algorithm to Cluster Data with Dense Adjacent Clusters [J].https://doi.org/10.1016/j.chemolab.2012.11.006 URL [本文引用: 1] 摘要
Over the last several years, DBSCAN (Density-Based Spatial Clustering of Applications with Noise) has been widely used in many areas of science due to its simplicity and the ability to detect clusters of different sizes and shapes. However, the algorithm becomes unstable when detecting border objects of adjacent clusters as was mentioned in the article that introduced the algorithm. The final clustering result obtained from DBSCAN depends on the order in which objects are processed in the course of the algorithm run. In this article, a modified version of the DBSCAN algorithm is proposed to solve this problem. It was shown that by using the revised algorithm the clustering results are considerably improved, in particular for data sets containing dense structures with connected clusters.
|
| [38] |
A Comparative Study of Efficient Initialization Methods for the K-means Clustering Algorithm [J].https://doi.org/10.1016/j.eswa.2012.07.021 URL [本文引用: 1] 摘要
Abstract: K-means is undoubtedly the most widely used partitional clustering algorithm. Unfortunately, due to its gradient descent nature, this algorithm is highly sensitive to the initial placement of the cluster centers. Numerous initialization methods have been proposed to address this problem. In this paper, we first present an overview of these methods with an emphasis on their computational efficiency. We then compare eight commonly used linear time complexity initialization methods on a large and diverse collection of data sets using various performance criteria. Finally, we analyze the experimental results using non-parametric statistical tests and provide recommendations for practitioners. We demonstrate that popular initialization methods often perform poorly and that there are in fact strong alternatives to these methods.
|
| [39] |
网络舆情文献聚类分析 [J].https://doi.org/10.3969/j.issn.1672-2272.2012.06.067 URL [本文引用: 1] 摘要
网络舆情的研究对维护当前的社会稳定、保证经济正常发展有着重要的作用。由于网络舆情研究的文献众多,理清其脉络、了解研究的热点和重点是网络舆情研究的基础。对中国知网中核心期刊内与网络舆情相关的论文进行了统计及聚类分析,将网络舆情的研究方向大致分类,并总结出统计规律,为今后的研究提供指引。
Network Public Opinion Literature Clustering Analysis [J].https://doi.org/10.3969/j.issn.1672-2272.2012.06.067 URL [本文引用: 1] 摘要
网络舆情的研究对维护当前的社会稳定、保证经济正常发展有着重要的作用。由于网络舆情研究的文献众多,理清其脉络、了解研究的热点和重点是网络舆情研究的基础。对中国知网中核心期刊内与网络舆情相关的论文进行了统计及聚类分析,将网络舆情的研究方向大致分类,并总结出统计规律,为今后的研究提供指引。
|
| [40] |
|
| [41] |
|
| [42] |
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}