




1 引 言
随着Web2.0时代的发展, 为满足用户交流、分享、合作、协调一致行动的本能需求[1], 网络社交平台不断兴起, 如豆瓣网、微博、QQ等, 网络用户根据工作需要或兴趣爱好加入不同网络社群, 在社群中进行交流与合作, 网络社群已经成为互联网用户最主要的交流组织方式。然而, 网络社群的多样性与复杂性使得用户在选择中遇到困难, 用户通常不知道某一社群所关注的重点, 只能根据一些片面的相关信息先加入大量相关社群, 经过了解后再进行有重点的选择, 这造成用户信息获取困难、效率低下等问题。目前, 主流社交平台通过社群管理员自定义标签的方式进行组织, 标签准确性不高, 不能较为准确地揭示社群特征。因此, 如何使用户能够清楚、及时地了解不同社群特征, 帮助用户快速选择感兴趣的社群成为研究热点。
国内外针对网络社群的研究主要集中在网络社群的运作机制、用户行为与关系和知识传播三个方面, 较少有将标签生成方法应用在网络社群中, 当前的标签生成研究主要集中在社群资源的标签标注上, 对社群整体标签方面的研究较少。如Hiltz等认为知识的流动是维系网络社群的重要因素, 因此知识与学习应该是社群活动的一部分[2]; Liu等基于视觉与语义相似性消除嘈杂标签, 并且通过WordNet使用同义词或者上位词扩展己观察到的标签以确定准确的标签[3]; 陈烨等提出一种新颖的基于社群隐含主题挖掘和多社群信息融合的自动图像标注算法, 该算法采用LDA挖掘社群中的隐含主题, 借此过滤相似图片标签传播过程中的“噪音”, 最终对多个社群的图像进行标注[4]; 吴丹等基于模拟实验探究社群与非社群在协同信息检索中的推荐行为、在检索式构造上对检索系统依赖以及协作方式等方面的区别, 认为社群与非社群的协同信息检索行为差异较大, 但在专业社群与兴趣社群则差异不显著[5]; 滕广青等从Folksonomy社群中的“用户-标签”关系出发, 基于后结构主义网络分析的思想, 进一步构建“用户-标签”2-模网络, 对社群知识的“自组织”问题进行深入剖析, 揭示用户主观认知对社群知识组织结构的影响以及对用户认知的塑形[6]; 崔芳等从社会交换的观点出发, 探究社群成员持续知识分享的成因, 认为社群成员间的关系属于“快速关系”, 社群投入与成员间的共同愿景都对该关系具有较大的预测力度[7]; 李文根基于社群问答系统提出一种相似度推荐的方法用于标签生成, 将聚合文本及问答对作为独立文档, 挖掘文档主题进而从主题层面计算文档间相似度, 最终利用相似文档标签集确定目标文档的标签[8]。
综上, 本文在当前研究基础上从宏观视角对社群整体进行标签生成研究, 将主题模型与复杂网络相关方法技术相结合发现社群特征。通过对网络社群的分析发现网络社群特征及整体兴趣可以从两方面表征:
(1) 社群讨论的话题, 社群成员通过各种方式针对某些问题进行讨论与交流, 代表着社群主要的关注点;
(2) 社群活跃用户的近期兴趣, 社群活跃用户是社群成员的主体, 其近期浏览的资源类型能够较好地表征用户近期兴趣, 同时全体活跃成员的兴趣也能够代表社群整体的近期兴趣。
因此, 本文提出从社群话题及社群活跃成员兴趣标签两个维度对社群标签进行动态生成。通过BTM主题模型(Biterm Topic Model)从社群话题中提取社群特征关键词作为话题预选标签; 再通过活跃用户近期浏览资源的标签作为兴趣标签, 基于兴趣标签网络的特征选取高Hub节点作为兴趣预选标签, 最后整合两个维度的预选标签确定社群动态标签。
2 社群标签动态生成模型
网络社交平台中的社群一般是以用户需求或兴趣为导向的用户自组织群体, 本文整合网络社群中两种最主要的表现方式: 社群话题与活跃用户近期兴趣, 构建社群动态标签生成模型, 如图1所示。该模型包括两个子模型: 社群话题动态标签子模型与社群成员兴趣动态标签子模型。模型自动从社群中收集近期社群成员发表的讨论话题及参与话题成员近期观看资源标签。在子模型数据预处理的基础上, 对社群话题数据进行BTM主题模型训练后提取相应阈值的主题语词作为话题预标签; 对社群成员近期兴趣数据运用复杂网络的思想构建兴趣标签网络, 据此计算网络中高Hub节点, 再根据标签特点进行数据清洗后作为成员兴趣预标签; 最后, 将两个子模型的预标签进行综合处理, 确定社群标签。同时, 该模型在一段周期内不断更新话题与成员兴趣信息, 动态更改社群标签, 最大程度表征社群特点及近期关注情况, 及时、准确地表征社群特征, 方便用户清楚地了解不同社群特点。
图1
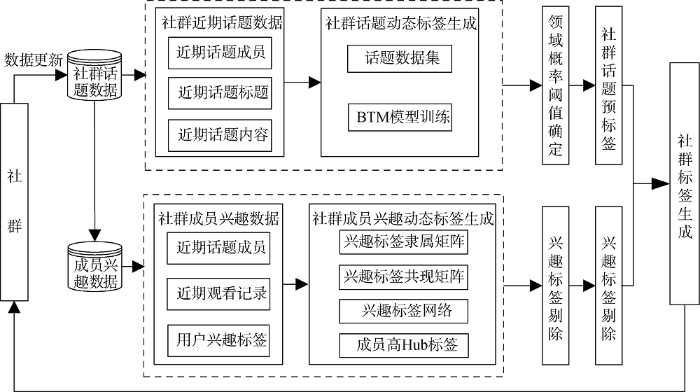
2.1 社群话题动态标签生成子模型
在社群话题动态标签生成模型中, 根据社群话题的特征, 主要采用短文本主题模型BTM对近期话题标题及其内容进行主题提取。BTM是由Cheng等提出的专用于短文本的主题挖掘模型, 该模型通过词共现的模式加强主题模型的学习, 并利用整个语料库的丰富信息抽样主题, 推断整个语料库全局的主题分布, 能够有效解决文档级别的数据稀疏性问题。其模型计算方法如公式(1)所示[9]。
其中, K表示主题数, P(ZK)表示主题K的概率, NK表示主题K的主题词数, P(Wi|ZK)表示主题K下第i个主题词的概率, N表示该文档集中的所有语词数。同时, 因为针对每个词都进行计算, 词频因素包含在其中, 故公式中并未单独设定词频变量。
在确定主题数K后, 经过1 000次以上的迭代即可得到每一个子文档集下的主题-语词概率分布。该分布即为社群话题预标签。
2.2 社群活跃成员兴趣动态标签生成子模型
同一社群成员的主要兴趣是相似的, 因此活跃社群成员的近期兴趣会存在相当大的部分重合, 通过不同用户兴趣间的关联能够构建出社群成员的兴趣网络。该网络中将会存在一些能够表征多数用户共同兴趣的节点, 这些节点具有较多的连接; 也会存在一些只有较少用户感兴趣的节点, 即节点的连接较少, 一般而言这两种节点数量符合齐普夫定律(Zipf’s Law)[12,13]。由于节点分布呈现出很大的异质性, 并且节点的度也服从幂率分布, 这样的网络符合复杂网络的特征。该子模型将根据社群成员兴趣网络这一特点, 利用资源标签表征用户兴趣, 通过网络度量指标——点度中心度动态地挖掘社群成员的兴趣中心, 即那些具有大量连接并主导网络运行的节点。这类节点被称为高Hub节点。
公式(3)以绝对中心度除以该节点最大可能的连接数G-1, 得到与节点i有直接联系的网络节点比例。这个比例取值范围是0~1, 0表示与任何节点都没有联系即一个孤点, 1表示与每一个节点都有直接联系。因此${{{C}'}_{D}}({{N}_{i}})$越接近1, 越是网络中的高Hub节点。
根据社群活跃用户资源标签, 利用R语言编写程序构建“资源-标签隶属矩阵”, 在隶属矩阵的基础上, 根据同一资源下共同出现的标签间的共现关系构建标签共现矩阵。最后利用标签共现矩阵绘制出标签网络, 并根据公式(3)计算出社群兴趣标签网络中各标签的标准化中心度, 以此进行从高到低排序, 作为社群成员兴趣预标签。
2.3 社群动态标签生成
在得到的子模型预标签基础上进行整合, 生成社群动态标签。在社群话题预标签提取中, 笔者认为针对不同领域需要设置不同的概率阈值进行预选标签的提取, 以保证预选标签的语词与其他语词相比具有显著性差异, 且较为稳定; 同时, 对于生成的社群活跃成员兴趣动态标签, 根据社群成员兴趣标签的标准化中心度排序, 选取Top10再剔除对社群表征意义不大的标签后作为成员兴趣预选标签。
由于社群话题标签主要表征社群整体特征, 其变化程度较低, 而社群成员兴趣标签表征用户近期兴趣其随时间变化程度较高。为使社群标签能够更加准确地表征社群的整体特征及近期关注点, 需根据不同领域设定两类标签整合的分配比例, 笔者认为一般社群整体特征标签变化较小且数量较少; 而成员兴趣标签变化较大且数量也较多, 一般社群标签数量均在5个左右, 因此为兼顾两类标签的因素将比例设定为2:3能够适合大多数领域。若话题预标签数量较少, 则由成员兴趣标签进行补充; 若话题预选标签与成员兴趣预选标签存在重叠情况, 则将该标签设定为Top1成员兴趣, 其他标签选取顺序依次顺延。据此, 生成最终社群动态标签。
3 实证研究
选取豆瓣小组这一典型网络社群作为实证研究的对象, 豆瓣小组一直定位于“对同一个话题感兴趣的人的聚集地”[16], 已创建30多万个小组社群, 月独立用户超过5 500万, 内容包括娱乐、美容、时尚、旅行等生活的方方面面。通过社群话题及活跃用户兴趣, 能够准确发现社群关注点, 便于用户的选择与加入。
3.1 实证数据
(1) 数据收集
笔者分别于2018年1月25日、2月6日、2月20日、3月6日四个时间节点, 利用Python爬虫从豆瓣兴趣小组“佳片推荐”抓取小组话题列表中最近的 50篇话题内容, 同时为验证实证结果, 爬取该小组据上述时间间隔较远的2017年1月25日数据, 以及相同类型的小组“一个人看电影”2018年1月25日、2月6日、2月20日、3月6日的数据, 及不同类型的小组“买书 读书 一起来吧”2019年2月18日、3月6日的数据, 部分数据如表1所示。
表1 部分小组话题数据
| 用户昵称 | 话题主题 | 话题内容 |
|---|---|---|
| 细嗅蔷薇。 | 你们看过的最好的日本电影是什么? | 有时候挺喜欢看日本片 个人认为看过的比较好的日本片子有: 松子 燕尾蝶(这是我唯一一口气看完的岩井俊二的片子) 恋空(连哭三遍) |
| 一只帅熊 | 求解|嘤嘤嘤咋收藏影人呀跟关注不 是一回事? | 一个傻问题: 突然发现关注影人跟收藏影人不是一个事T^T T^T嘤嘤嘤之前不是关注就能在收藏影人里看到么, 怎么关注了在收藏的影人里看不到呢, 在app里咋收藏影人呀只能网页收藏么[捂脸][捂脸] |
| 粒粒安然 | 2018奥斯卡提名 | 最佳影片《请以你的名字呼唤我》《至暗时刻》《敦刻尔克》《逃出绝命镇》《伯德小姐》《霓裳魅影》《华盛顿邮报》… |
| 丛虫 | 截猜线上活动, 截猜小能手快来 | 截猜不是一个人的武林而是一群人的江湖刀光剑影醉生梦死 |
| 混斗(FRQ) | 有标记电影五百部及以上的么求互关 | 就是关注一下, 与广告和刷评无关。 |
同时获取发起话题用户近3个月内看过资源的常用标签, 部分数据如表2所示。
表2 部分活跃用户近期资源标签数据
| 用户昵称 | 资源名 | 标签 |
|---|---|---|
| 小鱿 | 勇往直前 | 真实事件改编 灾难 美国 消防 传记 剧情 2017年 森林火灾 |
| 相爱相亲 | 家庭 亲情 温情 爱情 文艺 2017年 剧情 台湾 | |
| 佛罗里达乐园 | 美国 儿童 成长 2017年 剧情 社会 独立电影 戛纳电影节 | |
| 至暗时刻 | 丘吉尔 英国 二战 传记 历史 战争 剧情 2017年 | |
| 敦刻尔克 | 二战 战争 历史 英国 真实事件改编 军事 2017年 剧情 | |
| … | … | … |
| 遇到西西 | 那些年, 我们一起追的女孩 | 青春 台湾 爱情 校园 成长 文艺 感动 2011年 |
| 丹麦女孩 | 传记 变性 剧情 文艺 美国 同性 2015年 LGBT | |
| 东方快车谋杀案1974 | 悬疑 阿加莎·克里斯蒂 英国 推理 侦探 经典 犯罪 英国电影 | |
| 尼罗河上的惨案 | 悬疑 英国 推理 侦探 阿加莎 经典 犯罪 英国电影 | |
| 盗墓笔记 | 盗墓 冒险 小说改编 2016年 中国 悬疑 奇幻 剧情 | |
| … | … | … |
| 菲尼克斯 | 海洋帝国 | 历史 海洋史 日本 东亚史 世界史 2018年 白石隆 |
| … | … | … |
(2) 数据整理
实证数据是通过爬虫自动抓取, 数据类型多样化, 因此存在以下问题:
①存在不同外文资源但中文名称相同或同名资源的现象, 整理过程中通过在资源名称后加注年份进行区别;
②存在社群成员参与最近的话题讨论, 但在3个月内没有观看任何资源的现象, 即缺少该成员的资源标签数据, 针对这部分数据在整理中保存话题但在资源数据中去除。
经过对数据进行补充和梳理, 共有583篇话题讨论, 涉及286名成员, 共2 326个资源, 5 590个资源标签, 如表3所示。
表3 实证数据统计
| 豆瓣小组名称 | 数据时间 | 话题数 | 用户数 | 资源数 | 标签数 |
|---|---|---|---|---|---|
| 佳片推荐 | 2017/01/25 | 50 | 12 | 104 | 263 |
| 2018/01/25 | 50 | 35 | 440 | 858 | |
| 2018/02/06 | 50 | 31 | 387 | 754 | |
| 2018/02/20 | 50 | 31 | 327 | 599 | |
| 2018/03/06 | 50 | 34 | 392 | 813 | |
| 一个人看电影 | 2018/01/25 | 50 | 23 | 129 | 401 |
| 2018/02/06 | 50 | 14 | 106 | 338 | |
| 2018/02/20 | 50 | 14 | 104 | 317 | |
| 2018/03/06 | 50 | 18 | 144 | 432 | |
| 买书 读书 一起来吧 | 2019/02/18 | 36 | 24 | 51 | 265 |
| 2019/03/06 | 83 | 50 | 142 | 550 | |
| 总计 | 569 | 286 | 2 326 | 5 590 | |
经过对话题发布时间的统计, 发现话题发布时间主要集中于数据收集前5天, 其他时间的话题主要是以前的话题有了新回复, 因此实证社群活跃度较高, 每天都有人进行话题讨论, 社群内容更新较为快速, 具有较好的研究价值。
3.2 社群话题动态预标签生成
(1) 数据预处理
在对话题数据生成预标签之前, 需要对其进行预处理。
①去除特殊字符。由于网络环境下表情符号、特殊字符较为丰富, 如“╭(╯^╰)╮”等, 这些对主题提取并无意义, 因此予以去除。
②中文分词。为使从文本话题中提取的社群主题更能准确表征社群兴趣, 需对话题文本进行分词处理。利用Python、ICTCLAS中文分词系统, 在以文本特征构建自定义词典的基础上, 对每篇去除特殊字符后的话题文本进行分词。由于自定义词典的原因, 定义涉及到的资源名、人名, 大大提高了话题文本分词的准确性。
③去停用词。经分词处理后依然存在一些没有意义的符号、字词及非主题词的动词、数量词等, 如“《、?、有、那个、看过、一部”等。这些停用词与研究并无关系, 通过哈尔滨工业大学停用词表及自定义词表予以去除。
④语义映射。对相似语义的标签进行归一化处理, 提高其后分析的准确性。部分结果如表4所示。
表4 “佳片推荐”话题预处理部分结果
| 用户昵称 | 话题分词 |
|---|---|
| 细嗅蔷薇 | 最好 日本 电影 喜欢 日本 个人 日本 片子 松子燕尾蝶 唯一 一口气 岩井俊二 片子 恋空 三遍 |
| 一只帅熊 | 求解 收藏 影人 关注 问题 关注 影人 收藏 关注 收藏 影人 关注 收藏 影人 app 收藏 影人 网页 收藏 捂脸 |
| 粒粒安然 | 2018 奥斯卡 提名 最佳影片 请以你的名字呼唤我 至暗时刻 敦刻尔克 逃出绝命镇 伯德小姐 霓裳魅影 华盛顿邮报 水形物语 三块广告牌 导演 吉尔 莫德尔 托罗 水形物语 格蕾塔葛 韦格 伯德小姐 保罗 托马斯… |
| 丛虫 | 活动 能手 一个人的武林 江湖 刀光剑影 醉生梦死 |
| 混斗(FRQ) | 标记 电影 五百 求互关 关注 广告 刷评 无关 |
(2) 预标签生成
在数据预处理的基础上, 将话题数据作为社群文档集合W, 并将每个时间段的社群话题数据作为一个子文档集wi, i表示不同子文档集, 其中每一个文档都是一个话题。对分词编码, 并将每篇文档的分词结果用编码进行表示, 如表5所示。
表5 文档分词编码表示
| 文档 | 原标签 | 标签编码 |
|---|---|---|
| D1 | 最好 日本 电影 喜欢 日本 个人 日本 片子 松子燕尾蝶 唯一 一口气 岩井俊二 片子 恋空 三遍 | 3 4 0 5 4 6 4 7 8 9 10 11 7 12 13 |
| D2 | 求解 收藏 影人 关注 问题 关注 影人 收藏 关注 收藏 影人 关注 收藏 影人 app 收藏 影人 网页 收藏 捂脸 | 14 15 16 17 18 17 16 15 17 15 16 17 15 16 19 15 16 20 15 21 |
| D3 | 2018奥斯卡 提名 最佳影片 请以你的名字呼唤我 至暗时刻 敦刻尔克 逃出绝命镇 伯德小姐 霓裳魅影 华盛顿邮报 水形物语 三块广告牌 导演 吉尔 莫德尔 托罗 水形物语 格蕾塔葛 韦格 伯德小姐 保罗 托马斯… | 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 33 39 40 30 41 42… |
| D4 | 活动 能手 一个人的武林 江湖 刀光剑影 醉生梦死 | 209 210 211 212 213 214 |
| D5 | 标记 电影 五百 求互关 关注 广告 刷评 无关 | 215 0 216 217 17 218 219 220 |
表6 w1主题困惑度值
| 主题数 | $-\left\{ \sum\limits_{K}{P}({{Z}_{K}})\sum\nolimits_{i=1}^{{{N}_{K}}}{\mathrm{log}P({{W}_{i}}\text{ }\!\!|\!\!\text{ }{{Z}_{K}})} \right\}\text{/}N$ | 主题困惑度 | 主题数 | $-\left\{ \underset{K}{\mathop \sum }\,P({{Z}_{K}})\sum\nolimits_{i=1}^{{{N}_{K}}}{\mathrm{log}P({{W}_{i}}\text{ }\!\!|\!\!\text{ }{{Z}_{K}})} \right\}\text{/}N$ | 主题困惑度 |
|---|---|---|---|---|---|
| 1 | 0.018396830 | 1.018567094 | 11 | 0.015326789 | 1.015444847 |
| 2 | 0.017716041 | 1.017873901 | 12 | 0.015465664 | 1.015585876 |
| 3 | 0.017102683 | 1.017249771 | 13 | 0.015168573 | 1.015284200 |
| 4 | 0.016967775 | 1.017112545 | 14 | 0.015100700 | 1.015215292 |
| 5 | 0.016421836 | 1.016557415 | 15 | 0.015071742 | 1.015185894 |
| 6 | 0.016135249 | 1.016266125 | 16 | 0.014855438 | 1.014966328 |
| 7 | 0.015785420 | 1.015910668 | 17 | 0.015044306 | 1.015158041 |
| 8 | 0.016071002 | 1.016200835 | 18 | 0.014927471 | 1.015039442 |
| 9 | 0.015731518 | 1.015855909 | 19 | 0.014662723 | 1.014770748 |
| 10 | 0.015669250 | 1.015792656 | 20 | 0.018396830 | 1.018567094 |
表7 子文档集主题-语词概率分布
| 语词 | 概率 | 语词 | 概率 | 语词 | 概率 | 语词 | 概率 | 语词 | 概率 | 语词 | 概率 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文档集w1 | 文档集w2 | 文档集w3 | 文档集w4 | 验证文档集w5 | 验证文档集w6 | |||||||||||
| 电影 | 0.032301 | 电影 | 0.056503 | 电影 | 0.032147 | 电影 | 0.029478 | 电影 | 0.013089 | 孩子 | 0.019891 | |||||
| 水形物语 | 0.009645 | 推荐 | 0.023672 | 水形物语 | 0.014985 | 推荐 | 0.010106 | 影片 | 0.005582 | 工作 | 0.006816 | |||||
| 上映 | 0.008626 | 影片 | 0.016057 | 推荐 | 0.010033 | 16 | 0.008888 | 故事 | 0.004329 | 电影 | 0.006445 | |||||
| 2018 | 0.008484 | 劳拉 | 0.010815 | 黑帮 | 0.009520 | 2013 | 0.007673 | 生活 | 0.004076 | 父母 | 0.006057 | |||||
| 敦刻尔克 | 0.007489 | 经典 | 0.009270 | 敦刻尔克 | 0.008709 | 故事 | 0.006394 | 时间 | 0.004004 | 水形物语 | 0.005922 | |||||
| 推荐 | 0.006778 | 游戏 | 0.007725 | 三块广告牌 | 0.008282 | 女主 | 0.006075 | 投影仪 | 0.003975 | 方式 | 0.005686 | |||||
| 喜欢 | 0.006351 | 爱情 | 0.007449 | TVB | 0.007855 | 喜欢 | 0.005998 | 上映 | 0.003931 | 老师 | 0.004724 | |||||
| 原创 | 0.005972 | 丽影 | 0.007173 | 至暗时刻 | 0.007172 | 美国 | 0.005512 | 美国 | 0.003649 | 方法 | 0.004724 | |||||
| 日期 | 0.005972 | 古墓 | 0.007118 | 银翼杀手2049 | 0.007130 | 影片 | 0.005346 | 创作 | 0.003569 | 爸爸 | 0.004707 | |||||
| 三块广告牌 | 0.005830 | 2018 | 0.006622 | 霓裳魅影 | 0.006959 | 导演 | 0.004885 | 小帅 | 0.002918 | 老板 | 0.004252 | |||||
| 语词 | 概率 | 语词 | 概率 | 词语 | 概率 | 词语 | 概率 | 词语 | 概率 | |||||||
| 验证文档集w7 | 验证文档集w8 | 验证文档集w9 | 验证文档集w10 | 验证文档集w11 | ||||||||||||
| 电影 | 0.023764 | 电影 | 0.023439 | 电影 | 0.025442 | 书籍 | 0.083162 | 买书 | 0.036611 | |||||||
| 生活 | 0.012067 | 星座 | 0.011123 | 瑜伽 | 0.021329 | 买书 | 0.030079 | 书籍 | 0.031007 | |||||||
| 王彩玲 | 0.011156 | 年龄 | 0.010329 | 喜欢 | 0.008265 | 书店 | 0.012621 | 京东 | 0.025381 | |||||||
| 热爱 | 0.008766 | 歌舞片 | 0.010329 | 老师 | 0.008226 | 阅读 | 0.012007 | 活动 | 0.023510 | |||||||
| 柏舟 | 0.006517 | 最近 | 0.009676 | 挽回 | 0.005308 | 优惠券 | 0.011461 | 自营 | 0.020566 | |||||||
| 感动 | 0.005578 | 花名 | 0.007945 | 视频 | 0.004936 | 京东 | 0.010916 | 优惠券 | 0.019501 | |||||||
| 影片 | 0.005464 | 10 | 0.007775 | 分手 | 0.004642 | 宇宙 | 0.010234 | 参加 | 0.018948 | |||||||
| 进群 | 0.005408 | 心情 | 0.007151 | 学习 | 0.004524 | 封面 | 0.009551 | 世界 | 0.013345 | |||||||
| 喜欢 | 0.005208 | 11 | 0.006839 | 济公 | 0.004407 | 外星 | 0.009347 | 名著 | 0.010556 | |||||||
| 分享 | 0.004668 | 观影 | 0.006498 | 故事 | 0.004309 | 印刷 | 0.009142 | 中国 | 0.010247 | |||||||
表7展示了“佳片推荐”5个时间段(w1-5)、“一个人看电影”4个时间段(w6-9)及“买书 读书 一起来吧”2个时间段(w10-11)子文档集的“主题-语词”概率分布, 其中每一行表示一个子文档集的主题-语词及其概率, 如第1行文档集w1中, 该主题下共有10个语词, 其中“电影”这一语词表征该文档集的主题概率为0.032301。通过对各文档子文档集的主题-语词概率进行比较, 发现“佳片推荐”社群中“电影”、“推荐”等语词的概率与其他语词相比具有较为明显的差别, 而文档集w10“书籍”、“买书”语词概率也具有显著区别, 且在同一社群不同的子文档集中概率都比较高, 较为稳定, 表征了社群的主要特征。
3.3 社群活跃成员兴趣动态预标签生成
(2) 构建资源-标签隶属矩阵
(3) 构建标签共现矩阵
表10 资源-标签隶属矩阵部分结果
| 美国 | 剧情 | 爱情 | 2017年 | 喜剧 | 动作 | 人性 | 科幻 | 文艺 | 成长 | … | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 圣鹿之死 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | … |
| 我和厄尔以及将死的女孩 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | … |
| 别让我走 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | … |
| 欢乐谷 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | … |
| 幻体: 续命游戏 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | … |
| 生存回圈 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | … |
| 猩球崛起3: 终极之战 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | … |
| … | … | … | … | … | … | … | … | … | … | … | … |
表11 标签共现矩阵部分结果
| 西部 | 美国 | 动作 | 牛仔 | 2016年 | 翻拍 | 犯罪 | 剧情 | 悬疑 | 人性 | 中国大陆 | … | 卑鄙的我 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 西部 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | … | 0 |
| 美国 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | … | 1 |
| 动作 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | … | 0 |
| 牛仔 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | … | 0 |
| 2016年 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | … | 0 |
| 翻拍 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | … | 0 |
| 犯罪 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | … | 0 |
| 剧情 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | … | 0 |
| 悬疑 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | … | 0 |
| 人性 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | … | 0 |
| 中国大陆 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | … | 0 |
| … | … | … | … | … | … | … | … | … | … | … | … | 0 | 0 |
| 卑鄙的我 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … | 0 |
(4) 预标签生成
图2

表12 标签绝对中心度及标准化中心度部分结果
| 标签 | 美国 | 剧情 | 2017年 | 爱情 | 喜剧 | 犯罪 | 电视剧 | 悬疑 | … |
|---|---|---|---|---|---|---|---|---|---|
| 绝对中心度${{C}_{D}}({{N}_{i}})$ | 313 | 312 | 279 | 277 | 229 | 195 | 185 | 183 | … |
| 标准化中心度${{{C}'}_{D}}({{N}_{i}})$ | 0.36523 | 0.36406 | 0.32555 | 0.32322 | 0.26721 | 0.22754 | 0.21587 | 0.21354 | … |
表13 “佳片推荐”不同时间段标签标准化中心度部分结果
| 17.1.25 | ${{{C}'}_{D}}({{N}_{i}})$ | 18.2.6 | ${{{C}'}_{D}}({{N}_{i}})$ | 18.2.20 | ${{{C}'}_{D}}({{N}_{i}})$ | 18.3.6 | ${{{C}'}_{D}}({{N}_{i}})$. |
|---|---|---|---|---|---|---|---|
| 美国 | 0.504 | 美国 | 0.368 | 美国 | 0.450 | 美国 | 0.401 |
| 剧情 | 0.447 | 爱情 | 0.338 | 剧情 | 0.383 | 剧情 | 0.302 |
| 2016年 | 0.321 | 剧情 | 0.335 | 爱情 | 0.333 | 喜剧 | 0.278 |
| 人性 | 0.313 | 喜剧 | 0.250 | 2017年 | 0.321 | 爱情 | 0.260 |
| 爱情 | 0.302 | 2017年 | 0.249 | 喜剧 | 0.308 | 2017年 | 0.240 |
| 喜剧 | 0.275 | 动画 | 0.227 | 人性 | 0.261 | 香港 | 0.204 |
| 经典 | 0.225 | 经典 | 0.219 | 经典 | 0.258 | 经典 | 0.190 |
| 悬疑 | 0.221 | 人性 | 0.214 | 美国 电影 | 0.209 | 中国 | 0.182 |
| 美国 电影 | 0.206 | 悬疑 | 0.189 | 动画 | 0.202 | 悬疑 | 0.182 |
| 英国 | 0.206 | 美国电影 | 0.186 | 科幻 | 0.201 | 人性 | 0.179 |
表14 “一个人看电影”不同时间点标签标准化中心度部分结果
| 18.1.25 | ${{{C}'}_{D}}({{N}_{i}})$ | 18.2.6 | ${{{C}'}_{D}}({{N}_{i}})$ | 18.2.20 | ${{{C}'}_{D}}({{N}_{i}})$ | 18.3.6 | ${{{C}'}_{D}}({{N}_{i}})$ |
|---|---|---|---|---|---|---|---|
| 美国 | 0.033 | 剧情 | 0.027 | 美国 | 0.034 | 剧情 | 0.028 |
| 剧情 | 0.031 | 美国 | 0.025 | 剧情 | 0.028 | 美国 | 0.025 |
| 爱情 | 0.029 | 爱情 | 0.024 | 喜剧 | 0.024 | 爱情 | 0.023 |
| 喜剧 | 0.023 | 2017年 | 0.022 | 爱情 | 0.024 | 2017年 | 0.022 |
| 2017年 | 0.021 | 人性 | 0.018 | 2017年 | 0.021 | 喜剧 | 0.022 |
| 人性 | 0.017 | 动画 | 0.018 | 英国 | 0.020 | 人性 | 0.017 |
| 文艺 | 0.015 | 文艺 | 0.017 | 青春 | 0.017 | 电视剧 | 0.015 |
| 经典 | 0.014 | 悬疑 | 0.017 | 人性 | 0.016 | 犯罪 | 0.012 |
| 动作 | 0.013 | 喜剧 | 0.016 | 动作 | 0.015 | 香港 | 0.012 |
| 英国 | 0.013 | 中国大陆 | 0.014 | 科幻 | 0.014 | 动画 | 0.012 |
表15 “买书 读书 一起来吧”不同时间点标签标准化中心度部分结果
| 19.2.18 | ${{{C}'}_{D}}({{N}_{i}})$ | 19.3.6 | ${{{C}'}_{D}}({{N}_{i}})$. |
|---|---|---|---|
| 历史 | 0.031 | 文学 | 0.032 |
| 文学 | 0.019 | 小说 | 0.027 |
| 中国 | 0.018 | 外国文学 | 0.026 |
| 外国文学 | 0.018 | 历史 | 0.015 |
| 小说 | 0.010 | 随笔 | 0.010 |
| 随笔 | 0.011 | 中国文学 | 0.011 |
| 2018年 | 0.011 | 国学 | 0.010 |
| 近代史 | 0.010 | 写作 | 0.009 |
| 读库 | 0.010 | 古典文学 | 0.009 |
| 文化 | 0.009 | 日本 | 0.009 |
3.4 社群动态标签生成
将3.2节生成的社群话题动态标签与3.3节生成社群活跃成员兴趣动态标签进行整合, 生成社群动态标签。
而该小组原标签为: 电影、电视、导演、编剧、演员。通过两组标签的对比分析可以看到, 动态生成的标签既能够较为准确地反映出社群的特征, 同时对社群短期的兴趣也有较好的揭示, 方便用户的社群选择。
4 实证研究结果验证
本文抓取“佳片推荐” 5个时间点, “一个人看电影”4个时间点, “买书 读书 一起来吧”2个时间点, 同一社群不同时间点、同类型社群相同时间点及不同类型社群的豆瓣兴趣小组话题及活跃成员兴趣标签数据。比较分析这三种情况, 并验证模型效果。各社群动态标签生成结果如表16所示。
表16 社群标签动态生成结果
| 社群名称 | 原标签 | 数据日期 | 社群动态标签 | ||||
|---|---|---|---|---|---|---|---|
| 佳片推荐 | 电影 电视 导演 编剧 演员 | 2017.1.25 | 电影 | 人性 | 爱情 | 喜剧 | 悬疑 |
| 2018.1.25 | 电影 | 爱情 | 喜剧 | 犯罪 | 悬疑 | ||
| 2018.2.06 | 电影 | 推荐 | 爱情 | 喜剧 | 动画 | ||
| 2018.2.20 | 电影 | 水形物语 | 爱情 | 喜剧 | 人性 | ||
| 2018.3.06 | 电影 | 推荐 | 喜剧 | 爱情 | 悬疑 | ||
| 一个人看电影 | 电影 一个人 生活 单身 | 2018.1.25 | 孩子 | 爱情 | 喜剧 | 人性 | 文艺 |
| 2018.2.06 | 电影 | 生活 | 爱情 | 人性 | 动画 | ||
| 2018.2.20 | 电影 | 星座 | 喜剧 | 爱情 | 青春 | ||
| 2018.3.06 | 电影 | 瑜伽 | 爱情 | 喜剧 | 人性 | ||
| 买书 读书 一起来吧 | 买书 读书 聊天 书友 书讯 | 2019.2.18 | 书籍 | 买书 | 历史 | 文学 | 小说 |
| 2019.3.06 | 买书 | 书籍 | 文学 | 小说 | 历史 | ||
通过表16可以发现, 不同类型社群间主要特征并不相同, “佳片推荐”与“一个人看电影”主要关注的是电影, 而“买书 读书 一起来吧”关注的是书籍与买书。其中, “佳片推荐”长期的兴趣点为爱情和喜剧电影, 但随着时间的变化, 社群的关注重点也会发生改变。如2017年较多关注“人性”方面的电影, 在2018年2月主要关注“水形物语”, 在3月除爱情喜剧外更多的关注“悬疑”主题电影。
查询2017年1月25日之前热映的电影, 结果如表17所示, 笔者发现自从2016年年中韩国电影《我们的世界》、《釜山行》热映, 引起观众对有关人性电影的喜爱热潮, 在2016年下半年, 陆续有如《血战钢锯岭》、《萨利机长》等拷问人性的著名电影上映, 使得社群成员持续关注人性电影, 因此在2017年1月的社群动态标签中“人性”标签突出。
表17 2017年1月25日前热映的电影
| 电影 | 上映日期 |
|---|---|
| 我们的世界 | 2016.06.16 |
| 釜山行 | 2016.07.20 |
| 潘多拉 | 2016.12.07 |
| 血战钢锯岭 | 2016.12.08 |
| 萨利机长 | 2016.12.09 |
| 太空旅客 | 2017.01.13 |
| 降临 | 2017.01.20 |
而2017年12月29日上映的热播电影 《前任3: 再见前任》引起观众对“爱情”电影的追捧, 之后爱情电影《水形物语》获第90届奥斯卡金像奖最佳影片, 因此在2018年1月“爱情”为主要标签, 2月“水形物语”、“爱情”为主要标签, 之后随着贺岁档喜剧片的开始, 社群主要标签在3月转变为“喜剧”。
同时, 根据同类型不同社群同一时间点的对比, 可以看出两个社群的关注点和兴趣点是有所不同的, “一个人看电影”更加关注“人性”方面的电影, 也更具生活气息, 如“孩子”、“生活”、“瑜伽”等标签, 都体现了这点。而针对不同类型的社群模型也能准确识别, “买书 读书 一起来吧”模型识别其主要特征为“书籍”、“买书”并在动态标签中将其社群成员对书籍的兴趣点进行表征。
综上所述, 本文所提模型将社群话题表征的社群长期特征与社群活跃成员兴趣标签表征的社群短期兴趣结合, 能够较好地揭示社群关注的特点。对社群标签的动态生成提高网络社群定义的及时性与准确性, 方便用户能够清楚地了解不同社群特点, 解决用户获取信息、选择社群困难等问题。但是, 由于豆瓣用户多是使用概括性或反映整体感受、评价的标签[17], 因此在表征社群成员兴趣时有些标签的区分度不高, 但依然能够依据现实情况及时对社群成员兴趣予以表征。经过上述分析有理由相信, 在数据更为合理的情况下, 模型能够为社群更准确及时地生成表征其特点兴趣的标签。
5 结 语
本文将社群作为标签的生成对象, 提出基于社群话题及社群成员兴趣的社群标签动态生成模型, 通过社群话题与社群成员兴趣标签网络挖掘社群特点及近期兴趣关注, 利用BTM模型对社群话题短文本进行主题抽取, 并采用社会网络的分析方法提取社群成员兴趣标签网络的中心节点即高Hub节点, 将两者综合表征社群的特点与兴趣。同时, 将提出的模型应用于真实数据集, 通过不同社群、不同时间间隔的社群标签生成结果, 证明了模型的有效性及准确性。
为更加清晰的描述模型, 本文并未从多个数据源的社群进行数据采集, 样本数据集具有一定局限性, 不能完全涵盖所有网络社群领域, 仅从豆瓣社群验证了模型的准确性与有效性。同时, 针对具体领域话题语词的提取概率阈值研究未来将进一步深入, 并收集更加细致的数据, 通过实证结果继续完善模型的相关算法, 提高模型的有效性与准确性, 促使模型从理论走向实际应用。
作者贡献声明
蒋武轩: 模型构建, 实证分析, 论文撰写和修订;
熊回香: 提出研究方向和方法;
叶佳鑫, 安宁: 论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: jiangchair@mails.ccnu.edu.cn。
[1] 蒋武轩, 熊回香. 实验数据集数据预处理数据.xlsx. 豆瓣小组话题数据.
[2] 蒋武轩, 熊回香. 实验数据集数据预处理数据.xlsx. 豆瓣小组成员兴趣标签数据.
[3] 蒋武轩, 熊回香. 实验数据及数据预处理数据.xlsx. 话题分词词频结果数据.
[4] 蒋武轩, 熊回香. 实验数据及数据预处理数据.xlsx. 话题去停用词词频结果数据.
[5] 蒋武轩, 熊回香. 社群话题处理数据.xlsx. BTM预处理数据.
[6] 蒋武轩, 熊回香. 社群话题处理数据.xlsx. BTM结果数据.
[7] 蒋武轩, 熊回香. 社群成员处理数据.xlsx. 成员兴趣标签统计.
[8] 蒋武轩, 熊回香. 社群成员处理数据.xlsx. 电影-标签隶属矩阵.
[9] 蒋武轩, 熊回香. 社群成员处理数据.xlsx. 标签共现矩阵.
[10] 蒋武轩, 熊回香. 社群成员处理数据.xlsx. 兴趣标签中 心度.
[11] 蒋武轩, 熊回香. 模型结果.xlsx. 各时间间隔小组标签动态生成结果.
参考文献
Web 2.0环境下网络社群理论研究综述
[J].
Review on Online Community Theory in Web 2.0 Environment
[J].
Learning Together Online: Research on Asynchronous Learning Networks
[M].
Tag Ranking
[C]//
基于社群隐含主题挖掘和多社群信息融合的自动图像标注
[J].
DOI:10.11834/jig.20100614
Magsci
[本文引用: 1]

在Flickr图像共享网站上,大量无标签或者缺少标签的图像往往会因为标签信息的不完整,以致无法被有效地利用和检索。为了有效地进行图像检索,从Flickr用户经常会根据上传图像所隐含的主题而将其推荐到多个相关社群的特点出发,提出了一种新颖的基于社群隐含主题挖掘和多社群信息融合的自动图像标注算法。与传统的自动图像标注方法不同,该算法首先采用隐Dirichlet分配模型(latent Dirichlet allocation,LDA)对单个社群里的隐含主题(topic)进行挖掘,并利用隐含主题对由相似图像标签传播产生的初始“噪音”标签进行过滤;然后对同属于多个社群的图像,通过多社群信息融合来生成最终标注结果。实验结果显示了该新算法的有效性。
Automatic Image Annotation Using Social Group Latent Topic Mining and Multi-Group Information Fusion
[J].
DOI:10.11834/jig.20100614
Magsci
[本文引用: 1]
在Flickr图像共享网站上,大量无标签或者缺少标签的图像往往会因为标签信息的不完整,以致无法被有效地利用和检索。为了有效地进行图像检索,从Flickr用户经常会根据上传图像所隐含的主题而将其推荐到多个相关社群的特点出发,提出了一种新颖的基于社群隐含主题挖掘和多社群信息融合的自动图像标注算法。与传统的自动图像标注方法不同,该算法首先采用隐Dirichlet分配模型(latent Dirichlet allocation,LDA)对单个社群里的隐含主题(topic)进行挖掘,并利用隐含主题对由相似图像标签传播产生的初始“噪音”标签进行过滤;然后对同属于多个社群的图像,通过多社群信息融合来生成最终标注结果。实验结果显示了该新算法的有效性。
社群环境下的协同信息检索行为实验研究
[J].
An Experimental Study on Collaborative Information Seeking Behavior in Community Environment
[J].
基于“用户-标签”关系的社群知识自组织研究
[J].
Study on Self-Organization of Community Knowledge Based on "User-Tag" Relationship
[J].
基于快速“关系”的虚拟社群成员持续分享知识的动机研究
[J].
The Motivations of Virtual Community Members’ Continuous Sharing of Knowledge, Based on Swift “Guanxi”
[J].
基于社区问答系统的中文短文本标签生成研究
[D].
Research on Tag Generation for Chinese Short Text Based on Community Question Answering System
[D].
BTM: Topic Modeling over Short Texts
[J].
社会网络中基于U_BTM模型的主题挖掘
[J].
Topic Mining Based on U_BTM Model in Social Networks
[J].
基于话题标签的微博主题挖掘
[J].
DOI:10. 3969/ j. issn. 1000-3428. 2015. 04. 006
Magsci
[本文引用: 1]
随着互联网的发展,微博已成为人们获取信息的主要平台,为从海量微博中挖掘出有价值的主题信息,结合微博中的会话、转发和话题标签,将微博划分为用户兴趣、用户互动和话题微博3 类,提出基于作者主题模型(ATM)的话题标签主题模型HC-ATM,使用Gibbs 抽样法对模型进行推导,获取微博主题结构。在Twitter 数据集上的实验结果表明,与ATM 模型和基于潜在狄利克雷分布的微博生成模型相比,HC-ATM 模型的主题困惑度更小、差异度更大,并且能有效挖掘出不同微博类型的主题分布。
Microblog Topic Mining Based on Hashtag
[J].
DOI:10. 3969/ j. issn. 1000-3428. 2015. 04. 006
Magsci
[本文引用: 1]
随着互联网的发展,微博已成为人们获取信息的主要平台,为从海量微博中挖掘出有价值的主题信息,结合微博中的会话、转发和话题标签,将微博划分为用户兴趣、用户互动和话题微博3 类,提出基于作者主题模型(ATM)的话题标签主题模型HC-ATM,使用Gibbs 抽样法对模型进行推导,获取微博主题结构。在Twitter 数据集上的实验结果表明,与ATM 模型和基于潜在狄利克雷分布的微博生成模型相比,HC-ATM 模型的主题困惑度更小、差异度更大,并且能有效挖掘出不同微博类型的主题分布。
Emergence of Scaling in Random Networks
[J].
Statistical Mechanics of Complex Networks
[J].
Factoring and Weighting Approaches to Status Scores and Clique Identification
[J].
Centrality in Social Networks: Conceptual Clarification
[J].
用户认知对标签使用行为的影响分析——基于电影社会化标注数据的实证分析
[J].
Analysis on the Influence of User Cognition on Label Use Behavior-An Empirical Analysis Based on the Social Labeling Data of Movies
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}