1 引 言
随着网络交互技术和自媒体技术的快速发展,网络上充斥着大量的社会热点话题。网络话题[1 ] 大致分为两类:一类是广泛性话题,这类话题覆盖面广,受众人数多,社会影响大;另一类是地域性话题,这类话题只在小范围内被热烈讨论,具有很强的地域特征。虽然地域性话题范围小,但具有以下特点:小范围内强度大;反映事件的地方性质,凸显社会矛盾的细节;具有演化成广泛性话题的可能,是广泛性话题的一种源头。所以,地域性话题识别对深层次了解社会动态及掌控社会舆情发展脉络具有十分重要的意义。当前的话题识别方法主要集中在挖掘广泛性话题上[2 ] ,不具备地域性话题识别功能,其挖掘结果的弊端是“事后性”,即话题已经发展为广泛的社会舆情事件后才被发现,没有第一时间发现事件的苗头。另外,由于地域性话题文本量相对较小,广泛性话题挖掘方法很难对其有效识别,所以深入开展地域性话题的挖掘研究十分必要。
1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] 。其主要功能是对网络媒体信息流进行话题识别和动态跟踪。话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法。聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别。如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题。文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类。文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点。
为解决复杂网络环境下多话题识别问题,众多学者提出基于概率选择的话题检测识别方法,该方法假设文本、话题和词汇三者之间存在条件依赖关系,以话题作为隐变量,将隐狄利克雷分布作为话题分布的先验分布,用可观测词汇对话题分布进行训练。该方法承认话题是共存的,打破了聚类算法的话题连续假设。如文献[7 ]将LDA模型与生命周期理论相结合,通过维度分析、角色分析和层次分析计算出文档中的主题特征词,有效地挖掘出传播周期内热点主题分布。文献[8 ]提出词嵌入概率主题模型WTM,该方法定义了词嵌入和主题向量条件概率,并最小化分布函数KL散度方式,很好地解决了主题模型缺乏语义信息的难题。文献[9 ]利用LDA模型对每个聚类文本集进行话题建模,并从词长、词跨度和词频三个维度综合计算话题中词的权值,将权重最大的词作为话题标签,同时对话题进行标签去重处理,最后通过话题热度识别热点话题和一般话题。
当前的话题识别研究中,无论是聚类方法还是概率生成方法都只针对全局性话题进行识别,且语料库越大挖掘效果越好,没有考虑到话题的地域和文本量小的情况,无法有效识别地域性话题。针对这个问题,本文将用户的签到信息引入主题模型,提出一种面向地域的网络话题识别方法(Regional Oriented Latent Dirichlet Allocation, RO-LDA),该方法将文本、话题、签到位置及词汇进行联合建模,建立4者之间的依赖关系,生成文本-话题、话题-词汇和(话题,地域)-位置三个分布矩阵。运用吉布斯方法对观测值词汇W 和位置R 进行迭代采样,直到三个分布达到稳定的收敛状态为止。最后,从话题-词汇分布中识别出话题,从(话题,地域)-位置分布中识别出话题地域。另外,该方法将词汇和地域建立约束关系,提高词汇在语料库中的相对比例,实现了小文本量下的话题挖掘。
2 隐狄利克雷分布模型
2.1 模型原理
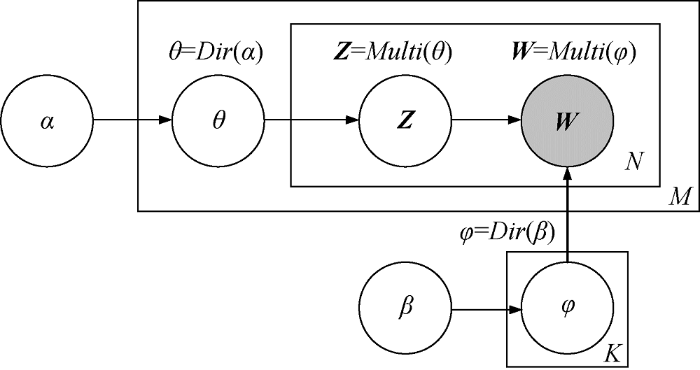
2003年,Blei等[10 ] 在PLSA(Probabilitistic Latent Semantic Analysis)的基础上提出隐狄利克雷分布模型(Latent Dirichlet Allocation, LDA),一种用于识别离散数据集合(如文本语料库)内隐含主题的概率生成模型。其生成过程是:将狄利克雷分布作为文档主题的先验分布,每个文档是K 个主题的多项式混合,每个主题是N 个词汇的多项式混合。本质上说,LDA是一个三层的贝叶斯网络,文本中每个词汇都被建模成一组潜在的主题有限混合,反过来,每个主题又被建模成一组潜在的主题概率无限混合,其生成过程如图1 所示。
图1
图1
LDA模型生成示意[10 ]
Fig.1
Graphical Representation of LDA Model[10 ]
其中,θ 是K 维主题分布矩阵,φ 是N 维词汇分布矩阵,Z 表示主题向量,W 表示词汇向量。Z 是隐含变量,W 是可观测值。LDA生成一个K 维θ 分布,然后生成N 维φ 分布,再生成文档的N 个词汇的联合概率如公式(1)[10 ] 所示。
(1) P ( θ , Z , W | α , β ) = P ( θ | α ) ∏ n = 1 N P ( z n | θ ) P ( w n | z n , β )
求解W 的边缘分布,消去θ 和Z 两个维度,得到词汇w 的一维生成概率,如公式(2)[10 ] 所示。
(2) P ( w | α , β ) = ∫ P ( θ | α ) ( ∏ n = 1 N ∑ z n P ( z n | θ ) P ( w n | z n , β ) ) dθ
LDA运用吉布斯采样训练出文档-主题分布θ 和主题-词汇分布φ ,最后利用最大期望(Expectation-Maximization, EM)算法对参数进行估计[11 ] 。
2.2 最优主题数求解
LDA模型最大的局限性是运算结果严重依赖话题参数K 。K 是人工设定的,设置过大会造成主题粒度过细;设置过小会造成主题融合。为解决此问题,众多学者提出主题数优化方法[12 ] ,其中最具代表性的是基于贝叶斯方法,该方法的核心是信息熵理论,计算方法如公式(3)和公式(4)[12 ] 所示。
(3) P ( w | z ) = ( Γ ( Nβ ) Γ ( β ) N ) K ∑ k = 1 K ∏ w Γ ( β + n z w ) Γ ( Nβ + n z • )
(4) M P ( w | K ) = ∑ m = 1 M 1 P ( w | z m )
公式(3)中,Γ()是标准伽玛函数, n z w w 选择主题z 的次数, n z • z 中词汇总数。公式(4)中,M 代表吉布斯采样次数,采用P (w |K )近似代表P (w |z )的均值,K 最优当且仅当P (w |K )最大。
3 面向地域的网络话题识别方法
位置服务(Location Based Services, LBS)[13 ] 是通信运营商为终端用户提供的与位置有关的服务总称,其核心服务是定位与导航。目前,移动通讯端和计算机终端都具有定位功能。所以,民众在网上表达意见观点时,文本信息中会含有位置属性。位置信息为地域性网络话题挖掘带来了便利,如文献[14 ]提出基于位置的话题识别方法,该方法将网络文本按照区域位置进行划分,再对每个划分内的文档进行话题识别。在该方法中,地域划分是靠人工实现的,划分不当容易造成话题被分割、无话题等情况,使得挖掘效果不佳。所以,本文利用LDA优秀的话题建模能力,在LDA中引入文本位置参数,建立面向地域的网络话题生成模型(RO-LDA)。
3.1 RO-LDA模型建立
设 D = { d 1 , d 2 , ⋅ ⋅ ⋅ , d M } D 中的话题数为K 。 V = { w 1 , w 2 , … , w N } D 中所有单词组成的集合, R = { r 1 , r 2 , … , r G } D 中文本位置标签集合。RO-LDA假设文本以一定的概率选择话题、话题以一定的概率选择词汇、词汇以一定概率选择位置。词汇有位置标签,能对话题与地域进行映射,形成话题的地域性分布。所以,文本、话题、词汇、位置4者之间形成条件概率依赖关系。文本可看作是符合狄利克雷分布的话题多项式混合,话题可看作是符合狄利克雷分布的词汇多项式混合,话题地域可以看作是符合二维高斯分布的位置多项式混合。RO-LDA模型中,话题和地域是隐变量,词汇和位置是可观测值。根据模型假设,定义以下关系。
对于D 中任意文本 d m k 维话题的矩阵向量 A d = < p z 1 , p z 2 , ⋅ ⋅ ⋅ , p zk > p zi = n zi / n z i n zi d m z i n d m z i
(5) P ( z i ) = ∑ m = 1 M P ( z i | d m = m ) P ( d m = m )
对任意话题 z k n 维词汇的矩阵向量 B z = < p w 1 , p w 2 , ⋅ ⋅ ⋅ , p wn > p wi = n wi / n z k w i nwi 表示分配给话题 z k V 中第i 个词数目,n 表示所有分配给话题 z k w i
(6) P ( w i ) = ∑ k = 1 K P ( w i | z k = k ) P ( z k = k )
对任意(话题,地域) l g H z = < p r 1 , p r 2 , ⋅ ⋅ ⋅ , p rn > p ri = n ri / n l g r i n ri r i l g n 表示位置 r i
(7) P ( r i ) = ∑ g = 1 G P ( r i | l g = g ) P ( l g = g )
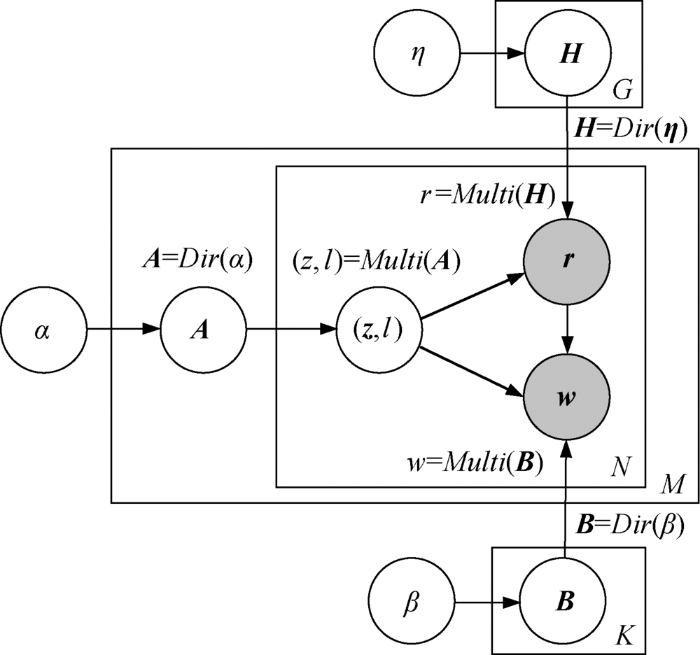
RO-LDA模型的生成过程是:从文档-话题矩阵中抽取一个话题,再从话题-词汇矩阵中抽取一个词汇,最后从(话题,地域)-位置矩阵中抽取一个位置。反复迭代上述过程,直至生成所有词汇及位置。生成过程及变量之间的依赖关系如图2 所示。
图2
图2
RO-LDA模型生成示意
Fig.2
Graphical Representation of RO-LDA Model
RO-LDA模型在LDA模型中加了一个(话题,地域)层,建立词汇w 与位置r 的生成关系。由于话题层与地域层是平行的,所以,RO-LDA仍然是一个三层贝叶斯网络,话题z 和l 是隐变量,词汇w 和位置r 是可观测值,各变量表示的含义如表1 所示。
3.2 模型推导及参数估计
由于RO-LDA模型中存在两个隐含变量z 和l ,文本-话题A 、话题-词汇B 和地域-位置H 三个分布参数无法使用最大似然法估计,只能先求出可观测量w 和r 的后验概率,再通过EM算法对实际值进行采样估计出参数的分布状态。
文本di 可看作是一个服从狄利克雷分布的话题多项式混合,记为 A d z 可以看作是一个服从狄利克雷分布的词汇多项式混合,记为 B z H z H z P 维向量,服从参数为μ 和σ 的高斯分布。根据文本、话题、地域、词汇、位置之间的概率依赖关系,词汇w 和位置r 的生成过程如下:
③从(话题,地域)-位置分布 H z
所以,文本d 、话题z 、词汇w 、(话题,地域)l 、位置r 的吉布斯采样的联合概率如公式(8)所示。
(8) P ( z i = z , l i = l | z - i , l - i , w , r , α , β , η )
其中, z - i l - i d 中第i 个词汇和第i 个位置以外,其他词汇和位置所对应的话题和(话题,地域),公式(8)进一步分解如公式(9)所示。
(9) P ( w , r , l , z , d ) = P ( w , r | l , z , d ) P ( l | z , d ) P ( z | d )
对公式(9)的右边部分继续分解如公式(10)-公式(12)所示。
(10) P ( w , r | l , z , d ) = ∫ P ( w , r | l , z , d , A ) P ( A | α ) dA = ∏ g = 1 G ∏ k = 1 K ∏ m = 1 M Γ αN [ Γ α ] N G × K × M × ∏ g = 1 G ∏ n = 1 N Γ ( α + x ( w , r ) ) Γ ( x + αN )
其中, x ( w , r ) r 内的词汇w 同时分配给(话题,地域)l、 话题z 和文本d 的数量,x 表示同时分配给(话题,地域)l 、话题z 和文本d 的词汇总数,Γ()是标准伽玛函数。
(11) P ( l | z , d ) = ∫ P ( l | z , d , H ) P ( H | η ) dH = ∏ k = 1 K ∏ m = 1 M ∏ l = 1 L Γ ( η + y l ) Γ ( y + ηG ) × Γ ( ηG ) [ Γ ( η ) ] G K × M
其中, y l d 中分配给主题z 的地域数量,y 表示文本d 中话题z 对应的地域总数。
(12) P z , d = ∫ P ( z | d , B ) P ( B | β ) dB = ∏ m = 1 M ∏ k = 1 K Γ ( β + t z ) Γ ( t + βK ) × Γ ( βK ) [ Γ ( β ) ] K
其中, t z d 中话题z 出现的次数,t 表示语料库中文本总数。由公式(10)-公式(12)得到吉布斯采样的联合概率公式如公式(13)所示。
(13) P ( z i = z , l i = l | z - i , l - i , w , r , α , β , η ) ∝ x ( w , r ) + α ∑ w = 1 N ∑ g = 1 G x ( w , r ) + αK × y l + η ∑ l = 1 L y l + ηG × t z + β ∑ k = 1 K t k + βW x w + α ∑ w = 1 N x w + αK × t z + β ∑ k = 1 K t k + βW
RO-LDA模型中,α ,β ,γ 是超参,分别作为A ,B ,H 三个分布的先验,初始值一般取经验值[15 ] ,通过马尔可夫链的多步转移,A ,B ,H 逐步收敛。由于马尔科夫链的初始状态对收敛结果没有影响,所以只须对参数A ,B ,H 进行估计。每次采样中,A ,B ,H 的更新公式如公式(14)-公式(16)所示。
(14) A m , z = α z + x m z α z K + ∑ z = 1 K n m z
(15) B z , n = β n + x z n β n V + ∑ n = 1 V n z n
(16) H z , g = η g + n z g η g G + ∑ g = 1 G n z g
对公式(13)进行多步迭代转移,A ,B ,H 达到稳定状态后,得到最终的A ,B ,H 分布结果。
3.3 算法描述
RO-LDA模型的核心是利用文本、话题、词汇、位置4者之间隐含的依赖关系,建立贝叶斯网络,将狄利克雷分布作为贝叶斯网络的先验分布,通过吉布斯采样,获取稳定的A ,B ,H 状态矩阵,RO-LDA模型的迭代过程描述如下。
初始化(话题,地域)-位置矩阵,使得H ~Dir(η );
在矩阵A 中抽取一个话题zdn ~Multi (θdi );
在矩阵H 中抽取一个位置ri ~Multi (lzn );
4 实 验
4.1 数据来源及预处理
随机抽取2019年5月1日-5月15日新浪微博数据,共计103 982条。使用分词软件ICTCLAS对微博文本逐条进行分词,对分词结果进行清洗,去除停用词、介词、语气词、转折词等,建立文本-分词语料矩阵 M D d i w i r 1 -r 238 ,并为每条微博重置位置标签。
4.2 实验结果分析
RO-LDA模型中,话题数K 的值由话题优化函数返回得到,最优话题K 的值为122。超参α = β /K , β = 0.01, η = 0.01。话题位置的生成概率阈值设定为0.010,且位置个数最大设置为18,以上参数设置均为经验最优[15 ] 。RO-LDA模型在文本-分词矩语料阵 M D A 、B 、H 三个分布。
在B 分布中,选取生成概率TOP15的词汇作为话题特征词。在H 分布中,选择生成概率大于阈值的位置编号作为话题位置。话题特征词及位置信息如表2 所示。由于话题数较多,表2 仅列出8个具有代表性的话题。
根据表2 中的话题特征词,使用人工方法对8个话题进行概括,话题内容概括如下:①话题1:成都市危险废物混入垃圾,将被罚款10万元;②话题2:天津市有奖举报交通违法行为;③话题3:南京市网约车进入道路交通安全条例;④话题4:北京三甲医院实行急诊分级,危重患者优先;⑤话题5:江西省上饶第五小学学生被杀事件;⑥话题6:城镇职工基本养老保险单位缴费比例降低;⑦话题7:武磊出战西甲联赛;⑧话题8:五一旅游。
根据话题生成的位置信息识别出话题的地域,以话题1为例,首先将话题位置代码映射为实际位置。利用每个位置上的话题文本量除以该位置上的总文本量,得到话题在位置上的强度(保留两位小数),话题1的位置映射结果以及话题1在各位置上的强度信息如表3 所示。
根据表3 可知,话题1的发生区域在成都市,话题中心在成都市区,强度随着位置范围的增大而逐渐减弱,可以判断话题1是地域性话题。同样,按照此方法得出话题2、3、4均是地域性话题。话题2的地域在天津,话题3的地域在南京,话题4的地域在北京。
按照上述步骤,话题5的位置映射结果以及话题5在各位置上的强度信息如表4 所示。
从表4 中可知,话题5位置分布在全国各地,位置之间比较松散,关联性不强。话题强度在各位置上呈现类均匀分布,只在江西省上饶及周边位置上强度偏大,可以判断出话题5是广泛性话题,话题的中心在上饶市,且在全国范围内引起强烈的讨论,这种话题叫做“冲击波型”话题[14 ] ,即由地域性话题发展而成的广泛性话题。用同样的方法判断出话题6-话题8均是广泛性话题,但从话题的生成强度来看,话题6-话题8属于普通型话题,即它们没有中心点,话题在信息的接受范围内同时爆发,爆发点之间没有关联。
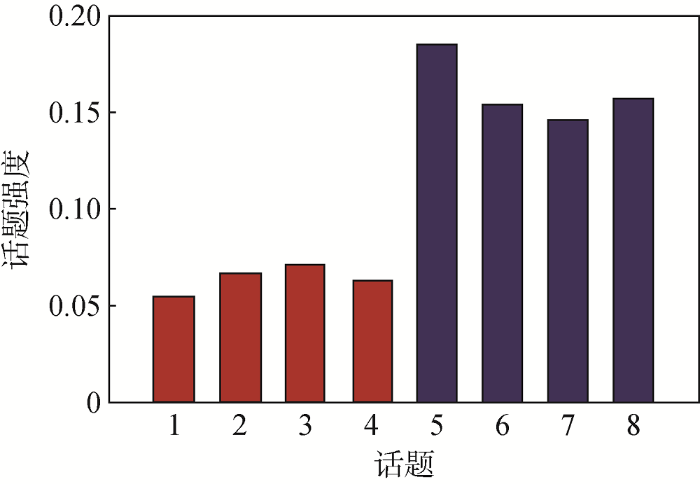
话题的文本数量占语料库文本总量的比值表示话题强度[15 ] 。话题强度反映民众对话题事件的关注程度。在文本-主题分布A 中,“行”代表文本di ,“列”代表di 生成K 个话题的概率,每列的概率加权平均可表示该列话题的强度。8个话题的强度对比如图3 所示。
图3
图3
话题强度对比
Fig.3
Topics Strength Comparison
图3 显示,广泛性话题5-话题8的强度明显高于地域性话题1-话题4,可以判断出话题强度与地域有关,地域越大,话题热度也就越高。原因是地域性话题文本量较少,所以总强度相对较低。这个特征使得基于强度的话题识别方法难以识别地域性话题。
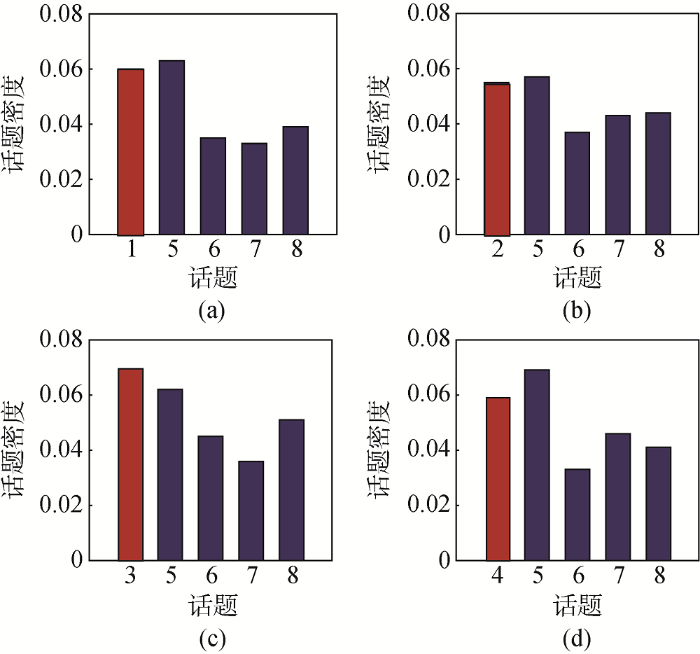
话题密度[16 ] 是区域内话题文本数与区域内文本总数的比值,刻画单位面积上话题强度。表2 中4个地域性话题与其余广泛性话题在重叠区域上的密度对比如图4 所示。
图4
图4
地域性话题与广泛性话题的密度对比
Fig.4
Density for Regional Topics and Wide Topics
4个子图中,只有广泛性话题5的密度与其他地域性话题相当,其余广泛性话题的密度均明显小于地域性话题。说明地域性话题虽然总体文本量较少,但小范围内的强度较强,民众讨论热度较高。
4.3 模型评价
为验证RO-LDA模型的有效性,采用准确率、召回率、F值作为评价指标,以TF-IDF算法、LDA算法、CNN-TTM算法[4 ] 、WTM算法[8 ] 作为对比,在相同的数据集上依次运行这些算法。然后将各模型识别出的话题与新浪微博标注的话题进行对比,评价结果如表5 所示。
在表5 中,RO-LDA模型的综合F值最大,说明其话题识别性能最好。
5 结 语
本文在LDA模型三层框架结构的基础上增加了(话题,地域)层,建立基于地域的话题检测模型RO-LDA。该模型根据语料库中文本、话题、位置、词汇4者之间的依赖关系,推导得到位置、词汇的生成概率。通过对观测词汇和位置的多次采样,生成文档-话题、话题-词汇、(话题,地域)-位置三个稳定的分布矩阵,具备了话题位置识别能力。经过实验验证,并与其他模型进行对比,RO-LDA模型在话题的地域分布识别上达到了良好效果。
由于文本位置标签概化由人工提前设定,标签概化的合理性对话题的地域识别精度具有一定程度的影响,所以,如何找到最优的位置标签是下一步主要的研究方向。
支撑数据
支撑数据由作者自存储,E-mail: lywzyfy@163.com。
[1] 刘玉文.Comment.txt.用户评论分词结果.
[2] 刘玉文.Location.xls.位置映射关系.
参考文献
View Option
[1]
Momtazi S . Unsupervised Latent Dirichlet Allocation for Supervised Question Classification
[J]. Information Processing and Management , 2018 ,54 (3 ):380 -393 .
[本文引用: 1]
[2]
徐月梅 , 吕思凝 , 蔡连侨 , 等 . 结合卷积神经网络和Topic2Vec的新闻主题演变分析
[J]. 数据分析与知识发现 , 2018 ,2 (9 ):31 -41 .
[本文引用: 1]
( Xu Yuemei Lv Sining Cai Lianqiao , et al . Analyzing News Topic Evolution with Convolutional Neural Networks and Topic2Vec
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (9 ):31 -41 .)
[本文引用: 1]
[3]
Chen L Zhang H Z Jose J M , et al . Topic Detection and Tracking on Heterogeneous Information
[J]. Journal of Intelligent Information Systems , 2018 ,51 (1 ):115 -137 .
[本文引用: 1]
[4]
付鹏 , 林政 , 袁凤程 , 等 . 基于卷积神经网络和用户信息的微博话题追踪模型
[J]. 模式识别与人工智能 , 2017 ,30 (1 ):73 -80 .
[本文引用: 2]
( Fu Peng Lin Zheng Yuan Fengcheng , et al . Convolutional Neural Network and User Information Based Model for Microblog Topic Tracking
[J]. Pattern Recognition and Artificial Intelligence , 2017 ,30 (1 ):73 -80 .)
[本文引用: 2]
[5]
周亚东 , 刘晓明 , 杜友田 , 等 . 一种网络话题的内容焦点迁移识别方法
[J]. 计算机学报 , 2015 ,38 (2 ):261 -271 .
[本文引用: 1]
( Zhou Yadong Liu Xiaoming Du Youtian , et al . A Method for Identifying the Evolutionary Focuses of Online Social Topics
[J]. Chinese Journal of Computers , 2015 ,38 (2 ):261 -271 .)
[本文引用: 1]
[6]
何跃 , 朱灿 , 朱婷婷 , 等 . 微博热点话题情感趋势研究
[J]. 情报理论与实践 , 2018 ,41 (7 ):155 -160 .
[本文引用: 1]
( He Yue Zhu Can Zhu Tingting , et al . Research on the Emotional Tendency of Hot Topics in Micro-blogs
[J]. Information Studies: Theory & Application , 2018 ,41 (7 ):155 -160 .)
[本文引用: 1]
[7]
廖海涵 , 王曰芬 , 关鹏 . 微博舆情传播周期中不同传播者的主题挖掘与观点识别
[J]. 图书情报工作 , 2018 ,62 (19 ):77 -85 .
[本文引用: 1]
( Liao Haihan Wang Yuefen Guan Peng . Topic Mining and Viewpoint Recognition of Different Communicators in the Transmission Cycle of Micro-blog Public Opinion
[J]. Library and Information Service , 2018 ,62 (19 ):77 -85 .)
[本文引用: 1]
[8]
余冲 , 李晶 , 孙旭东 , 等 . 基于词嵌入与概率主题模型的社会媒体话题识别
[J]. 计算机工程 , 2017 ,43 (12 ):184 -191 .
[本文引用: 2]
( Yu Chong Li Jing Sun Xudong , et al . Social Media Topic Recognition Based on Word Embedding and Probabilistic Topic Model
[J]. Computer Engineering , 2017 ,43 (12 ):184 -191 .)
[本文引用: 2]
[9]
方小飞 , 黄孝喜 , 王荣波 , 等 . 基于LDA模型的移动投诉文本热点话题识别
[J]. 数据分析与知识发现 , 2017 ,1 (2 ):19 -27 .
[本文引用: 1]
( Fang Xiaofei Huang Xiaoxi Wang Rongbo , et al . Identifying Hot Topics from Mobile Complaint Texts
[J]. Data Analysis and Knowledge Discovery , 2017 ,1 (2 ):19 -27 .)
[本文引用: 1]
[10]
Blei D M Ng A Y Jordan M I . Latent Dirichlet Allocation
[J]. Journal of Machine Learning Research , 2003 ,3 :993 -1022 .
[本文引用: 5]
[11]
李平 , 张路遥 , 曹霞 , 等 . 基于潜在主题的混合上下文推荐算法
[J]. 电子与信息学报 , 2018 ,40 (4 ):957 -963 .
[本文引用: 1]
( Li Ping Zhang Luyao Cao Xia , et al . Hybrid Context Recommendation Algorithm Based on Latent Topic
[J]. Journal of Electronics and Information Technology , 2018 ,40 (4 ):957 -963 .)
[本文引用: 1]
[12]
Zou Y P Ouyang J H Li X M . Supervised Topic Models with Weighted Words: Multi-Label Document Classification
[J]. Frontiers of Information Technology & Electronic Engineering , 2018 ,19 (4 ):513 -523 .
[本文引用: 2]
[13]
李维皓 , 曹进 , 李晖 . 基于位置服务隐私自关联的隐私保护方案
[J]. 通信学报 , 2019 ,40 (5 ):57 -66 .
[本文引用: 1]
( Li Weihao Cao Jin Li Hui . Privacy Self-Correlation Privacy-Preserving Scheme in LBS
[J]. Journal on Communications , 2019 ,40 (5 ):57 -66 .)
[本文引用: 1]
[14]
鲜学丰 , 崔志明 , 赵朋朋 , 等 . 基于主题模型的位置感知订阅发布系统
[J]. 计算机科学 , 2018 ,45 (3 ):167 -172 .
[本文引用: 2]
( Xian Xuefeng Cui Zhiming Zhao Pengpeng , et al . Location-awareness Publication Subscription System Based on Topic Model
[J]. Computer Science , 2018 ,45 (3 ):167 -172 .)
[本文引用: 2]
[15]
Twinandilla S Adhy S Surarso B , et al . Multi-Document Summarization Using K-Means and Latent Dirichlet Allocation (LDA)-Significance Sentences
[J]. Procedia Computer Science , 2018 ,135 :663 -670 .
[本文引用: 3]
[16]
Chen M L Wang Q Li X L . Patch-based Topic Model for Group Detection
[J]. Science China Information Sciences , 2017 , 60 : Article No. 113101 .
[本文引用: 1]
Unsupervised Latent Dirichlet Allocation for Supervised Question Classification
1
2018
... 随着网络交互技术和自媒体技术的快速发展,网络上充斥着大量的社会热点话题.网络话题[1 ] 大致分为两类:一类是广泛性话题,这类话题覆盖面广,受众人数多,社会影响大;另一类是地域性话题,这类话题只在小范围内被热烈讨论,具有很强的地域特征.虽然地域性话题范围小,但具有以下特点:小范围内强度大;反映事件的地方性质,凸显社会矛盾的细节;具有演化成广泛性话题的可能,是广泛性话题的一种源头.所以,地域性话题识别对深层次了解社会动态及掌控社会舆情发展脉络具有十分重要的意义.当前的话题识别方法主要集中在挖掘广泛性话题上[2 ] ,不具备地域性话题识别功能,其挖掘结果的弊端是“事后性”,即话题已经发展为广泛的社会舆情事件后才被发现,没有第一时间发现事件的苗头.另外,由于地域性话题文本量相对较小,广泛性话题挖掘方法很难对其有效识别,所以深入开展地域性话题的挖掘研究十分必要. ...
结合卷积神经网络和Topic2Vec的新闻主题演变分析
1
2018
... 随着网络交互技术和自媒体技术的快速发展,网络上充斥着大量的社会热点话题.网络话题[1 ] 大致分为两类:一类是广泛性话题,这类话题覆盖面广,受众人数多,社会影响大;另一类是地域性话题,这类话题只在小范围内被热烈讨论,具有很强的地域特征.虽然地域性话题范围小,但具有以下特点:小范围内强度大;反映事件的地方性质,凸显社会矛盾的细节;具有演化成广泛性话题的可能,是广泛性话题的一种源头.所以,地域性话题识别对深层次了解社会动态及掌控社会舆情发展脉络具有十分重要的意义.当前的话题识别方法主要集中在挖掘广泛性话题上[2 ] ,不具备地域性话题识别功能,其挖掘结果的弊端是“事后性”,即话题已经发展为广泛的社会舆情事件后才被发现,没有第一时间发现事件的苗头.另外,由于地域性话题文本量相对较小,广泛性话题挖掘方法很难对其有效识别,所以深入开展地域性话题的挖掘研究十分必要. ...
结合卷积神经网络和Topic2Vec的新闻主题演变分析
1
2018
... 随着网络交互技术和自媒体技术的快速发展,网络上充斥着大量的社会热点话题.网络话题[1 ] 大致分为两类:一类是广泛性话题,这类话题覆盖面广,受众人数多,社会影响大;另一类是地域性话题,这类话题只在小范围内被热烈讨论,具有很强的地域特征.虽然地域性话题范围小,但具有以下特点:小范围内强度大;反映事件的地方性质,凸显社会矛盾的细节;具有演化成广泛性话题的可能,是广泛性话题的一种源头.所以,地域性话题识别对深层次了解社会动态及掌控社会舆情发展脉络具有十分重要的意义.当前的话题识别方法主要集中在挖掘广泛性话题上[2 ] ,不具备地域性话题识别功能,其挖掘结果的弊端是“事后性”,即话题已经发展为广泛的社会舆情事件后才被发现,没有第一时间发现事件的苗头.另外,由于地域性话题文本量相对较小,广泛性话题挖掘方法很难对其有效识别,所以深入开展地域性话题的挖掘研究十分必要. ...
Topic Detection and Tracking on Heterogeneous Information
1
2018
... 1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] .其主要功能是对网络媒体信息流进行话题识别和动态跟踪.话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法.聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别.如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题.文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类.文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点. ...
基于卷积神经网络和用户信息的微博话题追踪模型
2
2017
... 1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] .其主要功能是对网络媒体信息流进行话题识别和动态跟踪.话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法.聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别.如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题.文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类.文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点. ...
... 为验证RO-LDA模型的有效性,采用准确率、召回率、F值作为评价指标,以TF-IDF算法、LDA算法、CNN-TTM算法[4 ] 、WTM算法[8 ] 作为对比,在相同的数据集上依次运行这些算法.然后将各模型识别出的话题与新浪微博标注的话题进行对比,评价结果如表5 所示. ...
基于卷积神经网络和用户信息的微博话题追踪模型
2
2017
... 1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] .其主要功能是对网络媒体信息流进行话题识别和动态跟踪.话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法.聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别.如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题.文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类.文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点. ...
... 为验证RO-LDA模型的有效性,采用准确率、召回率、F值作为评价指标,以TF-IDF算法、LDA算法、CNN-TTM算法[4 ] 、WTM算法[8 ] 作为对比,在相同的数据集上依次运行这些算法.然后将各模型识别出的话题与新浪微博标注的话题进行对比,评价结果如表5 所示. ...
一种网络话题的内容焦点迁移识别方法
1
2015
... 1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] .其主要功能是对网络媒体信息流进行话题识别和动态跟踪.话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法.聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别.如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题.文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类.文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点. ...
一种网络话题的内容焦点迁移识别方法
1
2015
... 1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] .其主要功能是对网络媒体信息流进行话题识别和动态跟踪.话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法.聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别.如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题.文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类.文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点. ...
微博热点话题情感趋势研究
1
2018
... 1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] .其主要功能是对网络媒体信息流进行话题识别和动态跟踪.话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法.聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别.如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题.文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类.文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点. ...
微博热点话题情感趋势研究
1
2018
... 1996年,话题检测与跟踪 (Topic Detection and Tracking, TDT)技术开始兴起,该项技术旨在帮助人们应对日益严重的网络信息爆炸问题[3 ] .其主要功能是对网络媒体信息流进行话题识别和动态跟踪.话题检测与跟踪技术衍生出两个研究方向:一是基于特征度量的聚类方法;另一类是基于概率选择的生成方法.聚类方法假设话题在时间上是顺序排列的,时间是话题的分界线,所以这种方法在连续的话题流模式下挖掘效果较好,但不适合层次化的话题识别.如文献[4 ]提出一种基于卷积神经网络话题模型CNN-TTM,该模型建立了两层卷积网络,以词向量作为输入,追踪短文本特征,解决了微博中特征稀疏以及话题界限模糊对特征抽取影响的问题.文献[5 ]提出一种基于时间流的合并聚类方法,该方法根据特征词的频度、分布和持续时间建立评估函数,对文本流所属话题进行分类.文献[6 ]对时事时滞关系与热点话题进行统计,采用Ward方法对话题情感进行聚类,绘制出8类话题情感演化曲线,最后对情感曲线进行关联分析,识别出话题情感的极性临界点. ...
微博舆情传播周期中不同传播者的主题挖掘与观点识别
1
2018
... 为解决复杂网络环境下多话题识别问题,众多学者提出基于概率选择的话题检测识别方法,该方法假设文本、话题和词汇三者之间存在条件依赖关系,以话题作为隐变量,将隐狄利克雷分布作为话题分布的先验分布,用可观测词汇对话题分布进行训练.该方法承认话题是共存的,打破了聚类算法的话题连续假设.如文献[7 ]将LDA模型与生命周期理论相结合,通过维度分析、角色分析和层次分析计算出文档中的主题特征词,有效地挖掘出传播周期内热点主题分布.文献[8 ]提出词嵌入概率主题模型WTM,该方法定义了词嵌入和主题向量条件概率,并最小化分布函数KL散度方式,很好地解决了主题模型缺乏语义信息的难题.文献[9 ]利用LDA模型对每个聚类文本集进行话题建模,并从词长、词跨度和词频三个维度综合计算话题中词的权值,将权重最大的词作为话题标签,同时对话题进行标签去重处理,最后通过话题热度识别热点话题和一般话题. ...
微博舆情传播周期中不同传播者的主题挖掘与观点识别
1
2018
... 为解决复杂网络环境下多话题识别问题,众多学者提出基于概率选择的话题检测识别方法,该方法假设文本、话题和词汇三者之间存在条件依赖关系,以话题作为隐变量,将隐狄利克雷分布作为话题分布的先验分布,用可观测词汇对话题分布进行训练.该方法承认话题是共存的,打破了聚类算法的话题连续假设.如文献[7 ]将LDA模型与生命周期理论相结合,通过维度分析、角色分析和层次分析计算出文档中的主题特征词,有效地挖掘出传播周期内热点主题分布.文献[8 ]提出词嵌入概率主题模型WTM,该方法定义了词嵌入和主题向量条件概率,并最小化分布函数KL散度方式,很好地解决了主题模型缺乏语义信息的难题.文献[9 ]利用LDA模型对每个聚类文本集进行话题建模,并从词长、词跨度和词频三个维度综合计算话题中词的权值,将权重最大的词作为话题标签,同时对话题进行标签去重处理,最后通过话题热度识别热点话题和一般话题. ...
基于词嵌入与概率主题模型的社会媒体话题识别
2
2017
... 为解决复杂网络环境下多话题识别问题,众多学者提出基于概率选择的话题检测识别方法,该方法假设文本、话题和词汇三者之间存在条件依赖关系,以话题作为隐变量,将隐狄利克雷分布作为话题分布的先验分布,用可观测词汇对话题分布进行训练.该方法承认话题是共存的,打破了聚类算法的话题连续假设.如文献[7 ]将LDA模型与生命周期理论相结合,通过维度分析、角色分析和层次分析计算出文档中的主题特征词,有效地挖掘出传播周期内热点主题分布.文献[8 ]提出词嵌入概率主题模型WTM,该方法定义了词嵌入和主题向量条件概率,并最小化分布函数KL散度方式,很好地解决了主题模型缺乏语义信息的难题.文献[9 ]利用LDA模型对每个聚类文本集进行话题建模,并从词长、词跨度和词频三个维度综合计算话题中词的权值,将权重最大的词作为话题标签,同时对话题进行标签去重处理,最后通过话题热度识别热点话题和一般话题. ...
... 为验证RO-LDA模型的有效性,采用准确率、召回率、F值作为评价指标,以TF-IDF算法、LDA算法、CNN-TTM算法[4 ] 、WTM算法[8 ] 作为对比,在相同的数据集上依次运行这些算法.然后将各模型识别出的话题与新浪微博标注的话题进行对比,评价结果如表5 所示. ...
基于词嵌入与概率主题模型的社会媒体话题识别
2
2017
... 为解决复杂网络环境下多话题识别问题,众多学者提出基于概率选择的话题检测识别方法,该方法假设文本、话题和词汇三者之间存在条件依赖关系,以话题作为隐变量,将隐狄利克雷分布作为话题分布的先验分布,用可观测词汇对话题分布进行训练.该方法承认话题是共存的,打破了聚类算法的话题连续假设.如文献[7 ]将LDA模型与生命周期理论相结合,通过维度分析、角色分析和层次分析计算出文档中的主题特征词,有效地挖掘出传播周期内热点主题分布.文献[8 ]提出词嵌入概率主题模型WTM,该方法定义了词嵌入和主题向量条件概率,并最小化分布函数KL散度方式,很好地解决了主题模型缺乏语义信息的难题.文献[9 ]利用LDA模型对每个聚类文本集进行话题建模,并从词长、词跨度和词频三个维度综合计算话题中词的权值,将权重最大的词作为话题标签,同时对话题进行标签去重处理,最后通过话题热度识别热点话题和一般话题. ...
... 为验证RO-LDA模型的有效性,采用准确率、召回率、F值作为评价指标,以TF-IDF算法、LDA算法、CNN-TTM算法[4 ] 、WTM算法[8 ] 作为对比,在相同的数据集上依次运行这些算法.然后将各模型识别出的话题与新浪微博标注的话题进行对比,评价结果如表5 所示. ...
基于LDA模型的移动投诉文本热点话题识别
1
2017
... 为解决复杂网络环境下多话题识别问题,众多学者提出基于概率选择的话题检测识别方法,该方法假设文本、话题和词汇三者之间存在条件依赖关系,以话题作为隐变量,将隐狄利克雷分布作为话题分布的先验分布,用可观测词汇对话题分布进行训练.该方法承认话题是共存的,打破了聚类算法的话题连续假设.如文献[7 ]将LDA模型与生命周期理论相结合,通过维度分析、角色分析和层次分析计算出文档中的主题特征词,有效地挖掘出传播周期内热点主题分布.文献[8 ]提出词嵌入概率主题模型WTM,该方法定义了词嵌入和主题向量条件概率,并最小化分布函数KL散度方式,很好地解决了主题模型缺乏语义信息的难题.文献[9 ]利用LDA模型对每个聚类文本集进行话题建模,并从词长、词跨度和词频三个维度综合计算话题中词的权值,将权重最大的词作为话题标签,同时对话题进行标签去重处理,最后通过话题热度识别热点话题和一般话题. ...
基于LDA模型的移动投诉文本热点话题识别
1
2017
... 为解决复杂网络环境下多话题识别问题,众多学者提出基于概率选择的话题检测识别方法,该方法假设文本、话题和词汇三者之间存在条件依赖关系,以话题作为隐变量,将隐狄利克雷分布作为话题分布的先验分布,用可观测词汇对话题分布进行训练.该方法承认话题是共存的,打破了聚类算法的话题连续假设.如文献[7 ]将LDA模型与生命周期理论相结合,通过维度分析、角色分析和层次分析计算出文档中的主题特征词,有效地挖掘出传播周期内热点主题分布.文献[8 ]提出词嵌入概率主题模型WTM,该方法定义了词嵌入和主题向量条件概率,并最小化分布函数KL散度方式,很好地解决了主题模型缺乏语义信息的难题.文献[9 ]利用LDA模型对每个聚类文本集进行话题建模,并从词长、词跨度和词频三个维度综合计算话题中词的权值,将权重最大的词作为话题标签,同时对话题进行标签去重处理,最后通过话题热度识别热点话题和一般话题. ...
Latent Dirichlet Allocation
5
2003
... 2003年,Blei等[10 ] 在PLSA(Probabilitistic Latent Semantic Analysis)的基础上提出隐狄利克雷分布模型(Latent Dirichlet Allocation, LDA),一种用于识别离散数据集合(如文本语料库)内隐含主题的概率生成模型.其生成过程是:将狄利克雷分布作为文档主题的先验分布,每个文档是K 个主题的多项式混合,每个主题是N 个词汇的多项式混合.本质上说,LDA是一个三层的贝叶斯网络,文本中每个词汇都被建模成一组潜在的主题有限混合,反过来,每个主题又被建模成一组潜在的主题概率无限混合,其生成过程如图1 所示. ...
... [
10 ]
Graphical Representation of LDA Model<sup>[<xref ref-type="bibr" rid="b10">10</xref>]</sup> Fig.1 ![]()
其中,θ 是K 维主题分布矩阵,φ 是N 维词汇分布矩阵,Z 表示主题向量,W 表示词汇向量.Z 是隐含变量,W 是可观测值.LDA生成一个K 维θ 分布,然后生成N 维φ 分布,再生成文档的N 个词汇的联合概率如公式(1)[10 ] 所示. ...
... [
10 ]
Fig.1 ![]()
其中,θ 是K 维主题分布矩阵,φ 是N 维词汇分布矩阵,Z 表示主题向量,W 表示词汇向量.Z 是隐含变量,W 是可观测值.LDA生成一个K 维θ 分布,然后生成N 维φ 分布,再生成文档的N 个词汇的联合概率如公式(1)[10 ] 所示. ...
... 其中,θ 是K 维主题分布矩阵,φ 是N 维词汇分布矩阵,Z 表示主题向量,W 表示词汇向量.Z 是隐含变量,W 是可观测值.LDA生成一个K 维θ 分布,然后生成N 维φ 分布,再生成文档的N 个词汇的联合概率如公式(1)[10 ] 所示. ...
... 求解W 的边缘分布,消去θ 和Z 两个维度,得到词汇w 的一维生成概率,如公式(2)[10 ] 所示. ...
基于潜在主题的混合上下文推荐算法
1
2018
... LDA运用吉布斯采样训练出文档-主题分布θ 和主题-词汇分布φ ,最后利用最大期望(Expectation-Maximization, EM)算法对参数进行估计[11 ] . ...
基于潜在主题的混合上下文推荐算法
1
2018
... LDA运用吉布斯采样训练出文档-主题分布θ 和主题-词汇分布φ ,最后利用最大期望(Expectation-Maximization, EM)算法对参数进行估计[11 ] . ...
Supervised Topic Models with Weighted Words: Multi-Label Document Classification
2
2018
... LDA模型最大的局限性是运算结果严重依赖话题参数K .K 是人工设定的,设置过大会造成主题粒度过细;设置过小会造成主题融合.为解决此问题,众多学者提出主题数优化方法[12 ] ,其中最具代表性的是基于贝叶斯方法,该方法的核心是信息熵理论,计算方法如公式(3)和公式(4)[12 ] 所示. ...
... [12 ]所示. ...
基于位置服务隐私自关联的隐私保护方案
1
2019
... 位置服务(Location Based Services, LBS)[13 ] 是通信运营商为终端用户提供的与位置有关的服务总称,其核心服务是定位与导航.目前,移动通讯端和计算机终端都具有定位功能.所以,民众在网上表达意见观点时,文本信息中会含有位置属性.位置信息为地域性网络话题挖掘带来了便利,如文献[14 ]提出基于位置的话题识别方法,该方法将网络文本按照区域位置进行划分,再对每个划分内的文档进行话题识别.在该方法中,地域划分是靠人工实现的,划分不当容易造成话题被分割、无话题等情况,使得挖掘效果不佳.所以,本文利用LDA优秀的话题建模能力,在LDA中引入文本位置参数,建立面向地域的网络话题生成模型(RO-LDA). ...
基于位置服务隐私自关联的隐私保护方案
1
2019
... 位置服务(Location Based Services, LBS)[13 ] 是通信运营商为终端用户提供的与位置有关的服务总称,其核心服务是定位与导航.目前,移动通讯端和计算机终端都具有定位功能.所以,民众在网上表达意见观点时,文本信息中会含有位置属性.位置信息为地域性网络话题挖掘带来了便利,如文献[14 ]提出基于位置的话题识别方法,该方法将网络文本按照区域位置进行划分,再对每个划分内的文档进行话题识别.在该方法中,地域划分是靠人工实现的,划分不当容易造成话题被分割、无话题等情况,使得挖掘效果不佳.所以,本文利用LDA优秀的话题建模能力,在LDA中引入文本位置参数,建立面向地域的网络话题生成模型(RO-LDA). ...
基于主题模型的位置感知订阅发布系统
2
2018
... 位置服务(Location Based Services, LBS)[13 ] 是通信运营商为终端用户提供的与位置有关的服务总称,其核心服务是定位与导航.目前,移动通讯端和计算机终端都具有定位功能.所以,民众在网上表达意见观点时,文本信息中会含有位置属性.位置信息为地域性网络话题挖掘带来了便利,如文献[14 ]提出基于位置的话题识别方法,该方法将网络文本按照区域位置进行划分,再对每个划分内的文档进行话题识别.在该方法中,地域划分是靠人工实现的,划分不当容易造成话题被分割、无话题等情况,使得挖掘效果不佳.所以,本文利用LDA优秀的话题建模能力,在LDA中引入文本位置参数,建立面向地域的网络话题生成模型(RO-LDA). ...
... 从表4 中可知,话题5位置分布在全国各地,位置之间比较松散,关联性不强.话题强度在各位置上呈现类均匀分布,只在江西省上饶及周边位置上强度偏大,可以判断出话题5是广泛性话题,话题的中心在上饶市,且在全国范围内引起强烈的讨论,这种话题叫做“冲击波型”话题[14 ] ,即由地域性话题发展而成的广泛性话题.用同样的方法判断出话题6-话题8均是广泛性话题,但从话题的生成强度来看,话题6-话题8属于普通型话题,即它们没有中心点,话题在信息的接受范围内同时爆发,爆发点之间没有关联. ...
基于主题模型的位置感知订阅发布系统
2
2018
... 位置服务(Location Based Services, LBS)[13 ] 是通信运营商为终端用户提供的与位置有关的服务总称,其核心服务是定位与导航.目前,移动通讯端和计算机终端都具有定位功能.所以,民众在网上表达意见观点时,文本信息中会含有位置属性.位置信息为地域性网络话题挖掘带来了便利,如文献[14 ]提出基于位置的话题识别方法,该方法将网络文本按照区域位置进行划分,再对每个划分内的文档进行话题识别.在该方法中,地域划分是靠人工实现的,划分不当容易造成话题被分割、无话题等情况,使得挖掘效果不佳.所以,本文利用LDA优秀的话题建模能力,在LDA中引入文本位置参数,建立面向地域的网络话题生成模型(RO-LDA). ...
... 从表4 中可知,话题5位置分布在全国各地,位置之间比较松散,关联性不强.话题强度在各位置上呈现类均匀分布,只在江西省上饶及周边位置上强度偏大,可以判断出话题5是广泛性话题,话题的中心在上饶市,且在全国范围内引起强烈的讨论,这种话题叫做“冲击波型”话题[14 ] ,即由地域性话题发展而成的广泛性话题.用同样的方法判断出话题6-话题8均是广泛性话题,但从话题的生成强度来看,话题6-话题8属于普通型话题,即它们没有中心点,话题在信息的接受范围内同时爆发,爆发点之间没有关联. ...
Multi-Document Summarization Using K-Means and Latent Dirichlet Allocation (LDA)-Significance Sentences
3
2018
... RO-LDA模型中,α ,β ,γ 是超参,分别作为A ,B ,H 三个分布的先验,初始值一般取经验值[15 ] ,通过马尔可夫链的多步转移,A ,B ,H 逐步收敛.由于马尔科夫链的初始状态对收敛结果没有影响,所以只须对参数A ,B ,H 进行估计.每次采样中,A ,B ,H 的更新公式如公式(14)-公式(16)所示. ...
... RO-LDA模型中,话题数K 的值由话题优化函数返回得到,最优话题K 的值为122.超参α = β /K , β = 0.01, η = 0.01.话题位置的生成概率阈值设定为0.010,且位置个数最大设置为18,以上参数设置均为经验最优[15 ] .RO-LDA模型在文本-分词矩语料阵 M D A 、B 、H 三个分布. ...
... 话题的文本数量占语料库文本总量的比值表示话题强度[15 ] .话题强度反映民众对话题事件的关注程度.在文本-主题分布A 中,“行”代表文本di ,“列”代表di 生成K 个话题的概率,每列的概率加权平均可表示该列话题的强度.8个话题的强度对比如图3 所示. ...
Patch-based Topic Model for Group Detection
1
2017
... 话题密度[16 ] 是区域内话题文本数与区域内文本总数的比值,刻画单位面积上话题强度.表2 中4个地域性话题与其余广泛性话题在重叠区域上的密度对比如图4 所示. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}