1 引 言
随着互联网的日益普及和通信技术的不断发展, 上网人群日益增多, 尤其是移动端, 通过手机玩游戏、刷微博、逛贴吧、看新闻的人越来越多。各大电信运营商看到了其中的商机, 为了满足客户的需求、拓宽自己的业务、抢占市场份额, 他们推出了各种优惠政策以吸引用户, 随着用户量不断上升, 投诉量也日益剧增, 因此如何有效地处理投诉文本成为了各界关注的焦点。其实在大量的投诉中有很多大家关注的热点话题, 比如“宽带”、“流量”、“扣费”等等, 如果可以从中发现话题, 并对话题进行追踪, 根据话题的变化趋势了解相关业务的受理情况、了解用户的关注点, 从而对症下药, 就能提高处理投诉的效率。因此对投诉文本进行话题挖掘就显得十分重要。
与新闻报道相比较, 移动投诉文本的结构更加复杂且短小, 这加大了提取话题的难度。本文针对移动投诉文本, 应用“话题识别”的相关知识, 从中识别投诉文本中的热点话题。
2 相关工作
话题识别和跟踪研究中, LDA[1 ] 主题模型是近年来文本挖掘领域的一个热门研究方向, 主题模型具有优秀的降维能力、针对复杂系统的建模能力和良好的扩展性。利用主题建模挖掘出的主题可以帮助人们理解海量文本背后隐藏的语义, 也可以作为其他文本分析方法的输入, 完成文本分类、话题检测、文本自动摘要和关联判断等多方面的文本挖掘任务。
LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力。近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] 。一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本。Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘。Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模。另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] 。Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题。Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型。张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘。文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示。
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂。因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法。首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证。
3 基于LDA模型的移动投诉文本热点话题识别
3.1 文本聚类
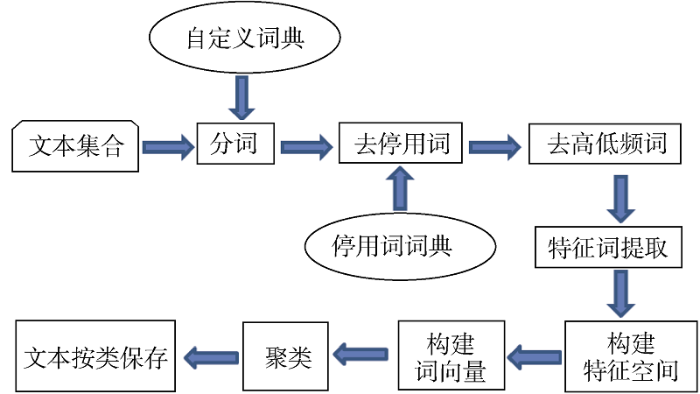
由于投诉文本跟新闻报道不一样, 它的形式简短, 单条文本涵盖内容信息很少。为了更好的提取话题, 首先将文本进行聚类, 这样每一类中的投诉文本不仅存在着共性, 而且内容比较充实, LDA模型抽取话题表达效果就会更好, 针对性更强。
本文采用k-means[15 ] 进行聚类, k-means是经典划分聚类算法。这种方法简单快速, 在对文档进行聚类前需要通过k值来确定簇数量。主要过程是从含n个文本的文档集中随机选择k个文本作为初始的聚类中心, 并通过计算得到其他文本到每个簇中心点的距离, 将文档划分到离它最近的簇中, 用迭代的方式不断重复上述过程, 直到满足准则函数或划分过程中相邻簇的中心不再发生变化为止。通过不断的迭代过程增加簇内的紧凑性, 降低簇间的相似性。图1 为本文聚类的流程。
使用k-means聚类好后, 将投诉文本按各类分别存于一个Txt文件中。
3.2 LDA模型话题抽取
LDA[1 ] 模型中对话题的定义为: 一组语义上相关的词及这些词在该话题上的分布概率。由于无法对LDA模型的未知参数进行求解, 在这里使用Gibbs Sampling的方法近似求解, Gibbs Sampling[16 ] 通过迭代采样达到逼近真实结果的效果, 其关键点在于对当前单词采样概率的求解, 如公式(1)[1 ] 所示。
(1)
其中, w 为词表个数; K 为话题数目; ij 项, 表示第j 个话题中第i 个词出现的次数; CDK 中的第dj 项, 表示第d 篇文档中, 第j 个话题包含的词的数目。通过Gibbs Sampling方法, 可以得到θ 、ϕ 的后验值, 如公式(2)[1 ] 和公式(3)[1 ] 所示。
(2)
(3)
在推导参数之前, 需要预先将话题的数目K设置好, 数值越大则话题越多, 话题的颗粒度越小, 反之亦然。K的取值对LDA模型文本提取和拟合性能影响较大, 其最佳的确定可以通过两种方法: 一种是词汇被选中的概率p (w |T )[17 ] , 另一种是困惑度(perplexity)[17 ] 。本文用困惑度确定K , 困惑度越小, 话题的拟合性就越好。困惑度计算如公式(4)[17 ] 所示。
(4)
其中, M 为文本数, Ni 为文本di 的长度(即单词个数), p (di )为LDA模型产生文本di 的概率。
3.3 热点话题识别
使用Gibbs Sampling抽样可以得到“话题-词语”和“文档-话题”的概率分布。对于“话题-词语”分布, 每个话题z 下分布着词语w 和它在此话题中的概率p (w |z ), 话题z ={(w1 ,p (w1 |z )),L ,(wi ,p (wi |z )),L , (wn ,p (wn |z ))} 对于“文档-话题”分布, 每个文档d下分布着k个话题的概率分布, 形如D ={P (Z1 |d ),L P (zi |d )L ,P (zk |d )} 。
使用Gibbs Sampling抽取的话题数量会比较多, 而且有些话题可能表达的意思十分接近, 有些话题几乎不能表达文档的意思, 所以要进行话题选取。话题的选取就要用到上面的“话题-词语”和“文档-话题”的概率分布。经过话题选取之后, 确定了文本的全局话题, 然后从全局话题中发现热点话题。
(1) 选取话题标签词
文本经过聚类, 得到了H 个类, 每个类使用Gibbs Sampling得到了若干个隐含的话题, 每个话题下分布着n 个话题相关的词, 对每个话题中的词计算其在该话题所在类文本中的词频(count )、词跨度(cover )和词的长度(length ), 则该词的权值(weight )计算公式如(5)所示。
(5)
为了不让词频、词的长度和词跨度的值相差太大, 使三者在权值中的比重相同, 分别对其进行了量化, 具体计算如公式(6)-公式(8)所示。
(6)
(7)
(8)
其中, count (i )为词在文档出现的次数, length (i )为词的长度, max(length (i ))为文档中词的最大长度, last (i )为词在文档中最后一次出现的位置, first (i )为词在文档中第一次出现的位置, ctotal 是文档中最后一个词的位置。计算完话题中词的权值后, 选出权值最大的词作为该话题的标签词。然后存入数据库, 数据表的字段名为标签词(tag )、话题(topic )和话题所表示的类(H )。
(2) 计算话题的文档概率分布均值
通过Gibbs Sampling对每个类抽样后, 各自得到一个“文档-话题”概率分布矩阵, 矩阵表达式如公式(9)所示。
(9)
上述矩阵中有k 个话题和m 条文档, 每行为k 个话题在一条文档中的分布概率, 每列为一个话题在m 个文档中的分布概率。通过上面的矩阵概率分布就可以得出每个话题的分布概率均值, 具体计算如公式(10)所示。
(10)
(3) 话题选取
得到了话题的标签词和话题的文档概率分布均值后, 构建话题矩阵如公式(11)所示。
(11)
矩阵中一共有n 个话题(topic), topici _tag 为topici 的标签词, avg(topici )为topicj 的文档概率分布均值, HI 、HJ 和HK 属于文本类集合H。由于话题标签词存在相同的情况, 所以先以话题标签词分组。认为同一组中的话题表达的意思相近, 如果一组中有多个话题选取其中分布概率均值最大的话题, 将其删除。接下来按每个话题的均值排序, 去除均值极小的话题, 因为均值小的话题不能很好地表达文档的意思, 剩下的话题就是文档的全局话题。
(4) 热点话题识别
根据LDA模型的原理, 每篇文档都是由数个不同的话题按照一定的比例生成的。这里假设一条经过预处理的投诉文本中有不少于话题z 中百分之几的词, 则认为这条投诉文本是话题z 的支持文档。之后使用徐佳俊等[18 ] 的方法计算文档话题支持率, 如公式(12)[18 ] 所示。如果在一个时间段内, 话题的支持文档的数量或者文档话题支持率超过一个设定的阈值, 那么这个话题就是热点话题。
(12)
其中, z 表示话题, t 表示时间段, t 内话题z 的所有支持文档数, |Dt |为时间段t 内所有文档数量。
通过箱型图分析[21 ] 进行话题支持文档数或者文档支持率阈值的设定, 箱型图的结构如图2 所示。
箱型图用来分析数据的分布情况和识别异常值。从图2 中可以看出数据分为4个部分, 位于上边缘之上和下边缘之下的值为异常值, 本文不作考虑。这里将上四分位数这个值设定为支持文档数的阈值, 如果某个话题的支持文档数的值超过这个阈值, 该话题为热点话题。一方面, 箱形图的绘制依靠实际数据, 不需要事先假定数据服从特定的分布形式, 没有对数据作任何限制性要求, 它只是真实直观地表现数据形状的本来面貌; 另一方面, 箱形图判断异常值的标准以四分位数和四分位距为基础, 四分位数具有一定的耐抗性, 多达25%的数据可以变得任意远而不会很大地扰动四分位数, 所以异常值不能对这个标准施加影响, 箱形图识别异常值的结果比较客观。
4 实验及结果分析
4.1 数据来源
本文所使用的数据是某电信公司投诉业务部提供的, 实验部分使用2015年3月-2015年4月的投诉文本, 其中, 3月份有20 000多条, 4月份有50 000多条, 前者用于训练提取话题和识别热点话题, 后者用于验证热点话题抽取的效果。分词使用的是结巴分词工具[20 ] , 停用词词典为哈尔滨工业大学的停用词词典[21 ] 。
4.2 语料预处理
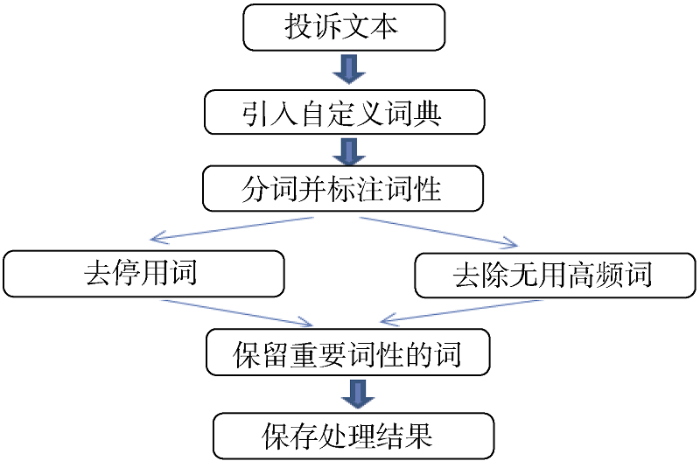
(1) 由于现有的词典无法完全识别投诉业务中的专业术语和业务词, 为了提高分词效果, 在某电信公司业务部员工的协助下手动建立了一个自定义的分词词典, 词典一共包含了1 600个重点业务关键词, 由三元组(词语, 词频, 词性)组成, 其中词性标注集采用的是中国科学院的汉语文本词性标注集。三元组中各个属性以空格分开, 每个三元组独占一行, 保存在Txt文件中。词典实例如表2 所示。
(2) 使用正则表达式去除投诉文本中特有的短语, 例如“手机号码”、“工单号”等由字母和数字组成的字符串。
(3) 引入自定义词典, 使用结巴分词工具进行分词并标注词性, 保留名词、动词等重要的词语, 并去除停用词。
(4) 去除无关的高频词, 由于投诉文本是由专业的服务人员使用软件按照模板格式录入的, 所以会有很多无法反映语义信息的重复词, 例如“诉求”、“用户来电表示”、“客户资产编号”、“请处理”、“谢谢”等, 预处理的流程如图3 所示。
处理结果示例如表3 所示。
4.3 聚 类
通过采用模糊k-means聚类, k设置为200, 并对聚类结果中每类的文本条数进行了统计, 其中条数最少为45条, 最多的有362条。具体如表4 所示。
4.4 全局话题抽取
实验利用Gibbs Sampling方法进行参数推理, 使用基于Java的Gibbs Sampling开源工具包(JGibbLDA- v.1.0)[22 ] , 模型参数α 、β 默认值为50/k 和0.1, 每个话题下的词语个数设置为10。
对于话题个数k , 这里使用公式(4)进行计算, 并对生成的话题进行人工评判。根据每类中文本的条数, 最终认定条数在[0, 50]区间内的类, k 值设置为5; 条数在[51, 100]区间内的类, k 值设置为10; 条数在[101, 200]区间内的类, k 值设置为20; 条数在[201, 300]区间内的类, k 值设置为30; 条数在[301, + ∞)区间内的类, k 值设置为40。
参数α 、β 和k 设置好后, 对每类进行话题的抽取, 得到”话题-词语”和“文档-话题”的概率分布, 如表5 和图4 所示。
表5 和图4 是某个类的“话题-词语”和“文档-话题”的概率分布, 表4 中有每个话题的10个话题词及其词语的话题分布概率p (w |z ), 图4 中每行为5个话题在一条文档中的分布概率, 每列为一个话题在31条文档中的分布概率。
通过话题的选取, 总共抽取了5 130个话题, 然后对每个话题提取它的标签词, 计算文档概率均值, 去除均值极小的话题, 保留相同标签词中均值最大的话题, 剩下299个全局话题, 示例结果如图5 所示。
其中, t_topic为话题标签, topic为话题下的分布词语, theta为话题在文档中分布概率均值。
4.5 热点话题识别实验结果分析
根据第3节的方法, 假设一条经过预处理的投诉文本中有不少于话题z中一定比例的词, 则认为这条投诉文本是话题z的支持文档。这里设置为30%, 因为实验中每个话题的词语个数为10, 即每条预处理后的投诉文本中词语与话题中词语的交集大于等于3个。通过分析话题支持文档数的箱型图如图6 所示。得出结果如表6 所示。
通过上述分析, 这里将支持的文档数不低于3 000的话题定义为热点话题。由于话题个数有299个, 文中分别选取了10个热点话题和10个一般话题进行说明, 如表7 所示。
从表7 中可以看出移动用户对“上网”、“数据流量”、“账单”等比较在意, 这与现实中用户的关注基本符合, 所以本文的话题抽取和热点识别方法是有效的。
4.6 话题测试实验结果分析
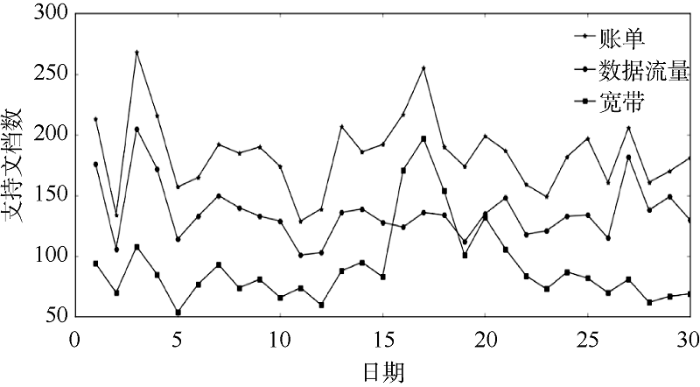
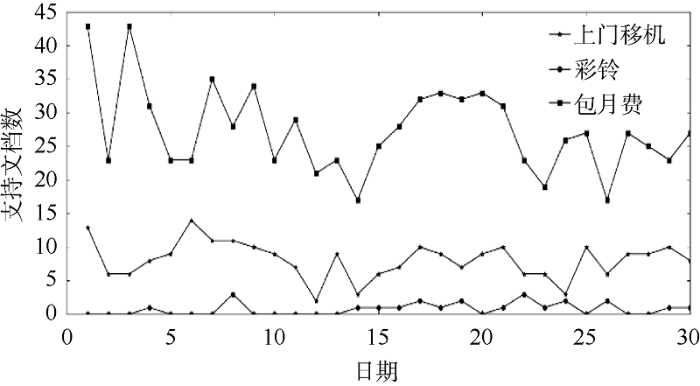
使用2015年4月的语料进行测试本文算法获取的热点话题效果, 先按表7 中话题支持文档数, 从低至高分别选择三个热点话题和三个一般话题进行实验。计算热点话题和一般话题在2015年4月30天中的支持文档数, 其变化趋势如图7 和图8 所示。
对比图7 和图8 可以看出热点话题的每天支持文档数普遍比一般话题高; 图8 中一般话题的变化趋势大部分时间都比较平稳, 有时也会出现急剧的爬升和下落, 但支持文档数还是不高, 最低点到最高点的变化幅度不是十分明显。从图7 可以发现热点话题变化趋势强弱程度比较明显, 最低点到最高点的变化幅度基本上都超过100, 有一个比较突出的峰值, 总体都经历了“开始-高潮-衰落”的过程。
数据出现以上现象, 从现实原因来说, 是因为热点话题与用户的生活息息相关, 都是大部分用户使用非常频繁的业务所出现的问题, 所以它的强度变化趋势就比较明显。通过对不同话题进行趋势分析之后, 可以发现它们的强度变化趋势与现实的实际情况是比较吻合的, 在一定程度上能够反映本文算法获取热点话题的效果。
5 结 语
通过实验说明本文在基于投诉文本的热点话题识别问题研究中取得了一定成果。在预处理阶段, 构建了一个移动领域的词典, 对于今后该领域的语料处理有一定的帮助; 在热点话题发现阶段, 使用了聚类技术, 使得类中的文本联系更加紧密; 再通过LDA模型进行话题抽取, 使话题表达更加细粒化, 针对性更强; 在话题的选取上, 考虑了话题对文档表达能力的强弱以及话题与话题之间的相似性。
本文对移动投诉领域话题识别和追踪的初探, 还存在一定的不足, 没有考虑到话题之间的语义关系, 使用的都是统计学的方法。接下将对此方法做出改善, 把更多的语义信息融合到话题模型中; 并对话题之间的关系进行研究, 发掘话题间的联系以及动态获取话题的演化。
作者贡献声明
黄孝喜, 方小飞, 谌志群: 提出研究思路, 设计研究方案;
方小飞, 黄孝喜, 王荣波: 分析数据, 进行试验, 论文起草;
王小华, 黄孝喜, 谌志群: 论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: 1484514227@qq.com。
[1] 方小飞. mobiledata.zip. 移动投诉文本.
[2] 方小飞. dict.txt. 投诉关键词词典.
参考文献
文献选项
[1]
David M B John D L Dynamic Topic Model
[C]//Proceedings of the 23rd International Conference on M achine Learning. Pittsburgh. 2006 : 113 -120 .
[本文引用: 6]
[2]
张培晶 , 宋蕾 . 基于LDA的微博文本主题建模方法研究述评
[J]. 图书情报工作 , 2012 , 56 (24 ): 120 -126 .
Magsci
[本文引用: 2]
摘要
<p>在介绍概率主题模型发展过程以及概率主题模型的代表性模型LDA基本原理的基础上,分析LDA模型的特征及其用于微博类网络文本挖掘的优势;介绍和评述微博环境下现有的基于LDA模型的文本主题建模方法,并对其扩展方式和建模效果进行总结和比较;最后对微博文本主题建模的发展方向进行展望。</p>
(Zhang Peijing Song Lei Overview on Topic Modeling of Microblogs Text Based on LDA
[J]. Library and Information Service , 2012 , 56 (24 ): 120 -126 .)
Magsci
[本文引用: 2]
摘要
<p>在介绍概率主题模型发展过程以及概率主题模型的代表性模型LDA基本原理的基础上,分析LDA模型的特征及其用于微博类网络文本挖掘的优势;介绍和评述微博环境下现有的基于LDA模型的文本主题建模方法,并对其扩展方式和建模效果进行总结和比较;最后对微博文本主题建模的发展方向进行展望。</p>
[3]
Weng J Lim E P Jiang J et al .TwitterRank: Finding Topic-sensitive Influential Twitterers
[C]//Proceedings of the 3rd ACM International Conference on Web Search and Data Mining. ACM , 2010 : 261 -270 .
[本文引用: 2]
[4]
Hong L Davison B D Empirical Study of Topic Modeling in Twitter
[C]//Proceedings of the 1st Workshop on Social Media Analytics. ACM , 2010 : 80 -88 .
[本文引用: 2]
[5]
Rosen-Zvi M Griffiths T Steyvers M et al .The Author- Topic Model for Authors and Documents
[C]// Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. AUAI Press , 2004 : 487 -494 .
[本文引用: 2]
[6]
Zhao W X Jiang J Weng J et al .Comparing Twitter and Traditional Media Using Topic Models
[C]// Proceedings of the 33rd European Conference on Information Retrieval. Springer Berlin Heidelberg , 2011 : 338 -349 .
[本文引用: 3]
[7]
Ramage D Hall D Nallapati R et al .Labeled LDA: A Supervised Topic Model for Credit Attribution in Multi-labeled Corpora
[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. 2009 : 248 -256 .
[本文引用: 3]
[8]
张晨逸 , 孙建伶 , 丁轶群 . 基于MB-LDA模型的微博主题挖掘
[J]. 计算机研究与发展 , 2011 , 48 (10 ): 1795 -1802 .
URL
Magsci
[本文引用: 3]
摘要
随着微博的日趋流行,Twitter等微博网站已成为海量信息的发布体,对微博的研究也需要从单一的用户关系分析向微博本身内容的挖掘进行转变.在数据挖掘领域,尽管传统文本的主题挖掘已经得到了广泛的研究,但对于微博这种特殊的文本,因其本身带有一些结构化的社会网络方面的信息,传统的文本挖掘算法不能很好地对它进行建模.提出了一个基于LDA的微博生成模型MB-LDA,综合考虑了微博的联系人关联关系和文本关联关系,来辅助进行微博的主题挖掘.采用吉布斯抽样法对模型进行推导,不仅能挖掘出微博的主题,还能挖掘出联系人关注的主题.此外,模型还能推广到许多带有社交网络性质的文本中.在真实数据集上的实验表明,MB-LDA模型能有效地对微博进行主题挖掘.
(Zhang Chenyi Sun Jianling Ding Yiqun Topic Mining for Microblog Based on MB-LDA Model
[J]. Journal of Computer Research and Development , 2011 , 48 (10 ): 1795 -1802 .)
URL
Magsci
[本文引用: 3]
摘要
随着微博的日趋流行,Twitter等微博网站已成为海量信息的发布体,对微博的研究也需要从单一的用户关系分析向微博本身内容的挖掘进行转变.在数据挖掘领域,尽管传统文本的主题挖掘已经得到了广泛的研究,但对于微博这种特殊的文本,因其本身带有一些结构化的社会网络方面的信息,传统的文本挖掘算法不能很好地对它进行建模.提出了一个基于LDA的微博生成模型MB-LDA,综合考虑了微博的联系人关联关系和文本关联关系,来辅助进行微博的主题挖掘.采用吉布斯抽样法对模型进行推导,不仅能挖掘出微博的主题,还能挖掘出联系人关注的主题.此外,模型还能推广到许多带有社交网络性质的文本中.在真实数据集上的实验表明,MB-LDA模型能有效地对微博进行主题挖掘.
[9]
唐晓波 , 向坤 . 基于LDA模型和微博热度的热点挖掘
[J]. 图书情报工作 , 2014 , 58 (5 ): 58 -63 .
https://doi.org/10.13266/j.issn.0252-3116.2014.05.010
URL
[本文引用: 2]
摘要
分析传统LDA模型在进行微博热点挖掘时所得概率结果抽象且难以结合实际解释的缺点;考虑到微博本身的数据特点和信息论中信息量的观点,提出微博热度的概念,并将其引入到LDA模型的热点挖掘研究中,构建基于微博热度的LDA模型;通过API采集微博数据上的实验,证明新方法与旧方法具有相同的性能,而且能得到更直观的微博热度表,并得出更具有说服力的挖掘结论。
(Tang Xiaobo Xiang Kun Hotspot Mining Based on LDA Model and Microblog Heat
[J]. Library and Information Service , 2014 , 58 (5 ): 58 -63 .)
https://doi.org/10.13266/j.issn.0252-3116.2014.05.010
URL
[本文引用: 2]
摘要
分析传统LDA模型在进行微博热点挖掘时所得概率结果抽象且难以结合实际解释的缺点;考虑到微博本身的数据特点和信息论中信息量的观点,提出微博热度的概念,并将其引入到LDA模型的热点挖掘研究中,构建基于微博热度的LDA模型;通过API采集微博数据上的实验,证明新方法与旧方法具有相同的性能,而且能得到更直观的微博热度表,并得出更具有说服力的挖掘结论。
[10]
朱颖 . 基于微博的热点话题发现
[D]. 重庆: 西南大学 , 2014 .
[本文引用: 2]
(Zhu Ying Hot Topic Extraction from Microblogs
[D]. Chongqing: Southwest University , 2014 .)
[本文引用: 2]
[11]
伍万坤 , 吴清烈 , 顾锦江 . 基于EM-LDA综合模型的电商微博热点话题发现
[J]. 现代图书情报技术 , 2015 (11 ): 33 -40 .
URL
Magsci
摘要
<p><strong>[目的]</strong>在社交营销环境下, 准确且有效地挖掘电商微博中的热点话题。<strong>[方法]</strong>提出一种综合模型EM-LDA对电商微博文本数据进行主题挖掘。EM-LDA综合模型包含两个子模型: ET-LDA模型和IT-LDA模型, 前者对含有哈希标签的微博进行主题挖掘, 后者对不含有哈希标签的微博进行主题挖掘。<strong>[结果]</strong>在确定合适的主题个数之后, 标准LDA模型和EM-LDA综合模型均被用来挖掘电商微博文本数据的热点话题, 与标准LDA模型相比, EM-LDA综合模型的热词挖掘准确率和有效性均较高, 且能提高主题可解释性。<strong>[局限]</strong>在ET-LDA模型中, 未考虑微博联系人之间的关联关系, 即模型中未引入用户特征; 在IT-LDA模型中没有考虑如何处理那些既是转发式又是对话式的电商微博。<strong>[结论]</strong>EM-LDA综合模型根据数据的特点, 改进了标准LDA模型, 能够提升电商微博热点话题识别的准确性。</p>
(Wu Wankun Wu Qinglie Gu Jinjiang Hot Topic Extraction from E-commerce Microblog Based on EM-LDA Integrated Model
[J]. New Technology of Library and Information , 2015 (11 ): 33 -40 .)
URL
Magsci
摘要
<p><strong>[目的]</strong>在社交营销环境下, 准确且有效地挖掘电商微博中的热点话题。<strong>[方法]</strong>提出一种综合模型EM-LDA对电商微博文本数据进行主题挖掘。EM-LDA综合模型包含两个子模型: ET-LDA模型和IT-LDA模型, 前者对含有哈希标签的微博进行主题挖掘, 后者对不含有哈希标签的微博进行主题挖掘。<strong>[结果]</strong>在确定合适的主题个数之后, 标准LDA模型和EM-LDA综合模型均被用来挖掘电商微博文本数据的热点话题, 与标准LDA模型相比, EM-LDA综合模型的热词挖掘准确率和有效性均较高, 且能提高主题可解释性。<strong>[局限]</strong>在ET-LDA模型中, 未考虑微博联系人之间的关联关系, 即模型中未引入用户特征; 在IT-LDA模型中没有考虑如何处理那些既是转发式又是对话式的电商微博。<strong>[结论]</strong>EM-LDA综合模型根据数据的特点, 改进了标准LDA模型, 能够提升电商微博热点话题识别的准确性。</p>
[12]
Rosen-Zvi M Chemudugunta C Griffiths T et al . Learning Author-topic Models from Text Corpora
[J]. ACM Transactions on Information Systems , 2010 , 28 (1 ): Article No.4 .
https://doi.org/10.1145/1658377.1658381
URL
[本文引用: 1]
摘要
Abstract We propose a new unsupervised learning technique for extracting information about authors and topics from large text collections. We model documents as if they were generated by a two-stage stochastic process. An author is represented by a probability distribution over topics, and each topic is represented as a probability distribution over words. The probability distribution over topics in a multi-author paper is a mixture of the distributions associated with the authors. The topic-word and author-topic distributions are learned from data in an unsupervised manner using a Markov chain Monte Carlo algorithm. We apply the methodology to three large text corpora: 150,000 abstracts from the CiteSeer digital library, 1,740 papers from the Neural Information Processing Systems Conference (NIPS), and 121,000 emails from a large corporation. We discuss in detail the interpretation of the results discovered by the system including specic topic and author models, ranking of authors by topic and topics by author, parsing of abstracts by topics and authors, and detection of unusual papers by specic authors. Experiments based on perplexity scores for test documents are used to illustrate systematic dierences between the proposed author topic model and a number of alternatives. Extensions to the model, allowing (for example) generalizations of the notion of an author, are also briey discussed.
[13]
Zhao W X Jiang J He J et al .Topical Key Phrase Extraction from Twitter
[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. 2011 : 379 -388 .
[本文引用: 1]
[14]
Ramage D Dumais S T Liebling D J Characterizing Microblogs with Topic Models
[C]//Proceedings of the 4th International Conference on Weblogs and Social Media. 2010 .
[本文引用: 1]
[15]
吴夙慧 , 成颖 , 郑彦宁 , 等 . K-means算法研究综述
[J]. 现代图书情报技术 , 2011 (5 ): 28 -35 .
URL
Magsci
[本文引用: 1]
摘要
对聚类分析中的基本算法K-means算法中的K值确定、初始聚类中心选择以及分类属性数据处理等主要问题进行综述,理清K-means算法的整个发展脉络及算法研究中的热点和难点,提出改进K-means聚类算法的思路。
(Wu Suhui Cheng Ying Zheng Yanning et al .Survey on K-means Algorithm
[J]. New Technology of Library and Information Service , 2011 (5 ): 28 -35 .)
URL
Magsci
[本文引用: 1]
摘要
对聚类分析中的基本算法K-means算法中的K值确定、初始聚类中心选择以及分类属性数据处理等主要问题进行综述,理清K-means算法的整个发展脉络及算法研究中的热点和难点,提出改进K-means聚类算法的思路。
[16]
朱成文 , 李兵 , 胡奎 . HMM参数估计的Gibbs抽样算法
[J]. 计算机工程与应用 , 2012 , 18 (18 ): 57 -60 .
https://doi.org/10.3778/j.issn.1002-8331.2012.18.012
URL
[本文引用: 1]
摘要
隐马氏模型(HMM)的参数估计是隐马氏模型各种应用的关键.经典的Baum-Welch算法容易陷入局部最优,对初始参数的要求苛刻.HMM参数估计的Gibbs抽样法,充分利用模型先验信息,借助马氏链蒙特卡洛方法(MCMC)的强大计算功能,避免了陷入局部最优,有更好的效果.
(Zhu Chengwen Li Bing Hu Kui Algorithm of Parameter Estimation of HMM via Gibbs Sampling.
Computer Engineering and Applications , 2012 , 48 (18 ): 57 -60 .)
https://doi.org/10.3778/j.issn.1002-8331.2012.18.012
URL
[本文引用: 1]
摘要
隐马氏模型(HMM)的参数估计是隐马氏模型各种应用的关键.经典的Baum-Welch算法容易陷入局部最优,对初始参数的要求苛刻.HMM参数估计的Gibbs抽样法,充分利用模型先验信息,借助马氏链蒙特卡洛方法(MCMC)的强大计算功能,避免了陷入局部最优,有更好的效果.
[17]
关鹏 , 王曰芬 . 科技情报分析中LDA主题模型最优主题数的确定方法研究
[J]. 现代图书情报技术 , 2016 , 32 (9 ): 42 -50 .)
URL
[本文引用: 3]
摘要
【目的】有效确定科技情报分析中LDA主题模型的最优主题数目。【方法】利用主题相似度度量潜在主题之间的差异,同时结合困惑度提出一种确定LDA最优主题数目的方法,该方法既考虑主题抽取效果同时也考虑模型对新文档的泛化能力。【结果】获取国内新能源领域的科技文献作为数据集,实证结果表明本文提出的最优LDA主题数确定方法与单纯使用困惑度相比,具有更高的主题抽取查准率(91.67%)、F值(86.27%)及科技文献推荐精度(71.25%)。【局限】未针对其他类型的数据集进行新方法的验证,如微博短文本、XML文档等。【结论】本文方法能够有效地从科技文献数据集中抽取辨识度较高的主题,并能够提高科技文献推荐效果。
(Guan Peng Wang Yuefen Identifying Optionan Topic Numbers from Sci-Tech Information with LDA Model
[J]. New Technology of Library and Information , 2016 , 32 (9 ): 42 -50 .)
URL
[本文引用: 3]
摘要
【目的】有效确定科技情报分析中LDA主题模型的最优主题数目。【方法】利用主题相似度度量潜在主题之间的差异,同时结合困惑度提出一种确定LDA最优主题数目的方法,该方法既考虑主题抽取效果同时也考虑模型对新文档的泛化能力。【结果】获取国内新能源领域的科技文献作为数据集,实证结果表明本文提出的最优LDA主题数确定方法与单纯使用困惑度相比,具有更高的主题抽取查准率(91.67%)、F值(86.27%)及科技文献推荐精度(71.25%)。【局限】未针对其他类型的数据集进行新方法的验证,如微博短文本、XML文档等。【结论】本文方法能够有效地从科技文献数据集中抽取辨识度较高的主题,并能够提高科技文献推荐效果。
[18]
徐佳俊 , 杨飏 , 姚天昉 , 等 . 基于LDA模型的论坛热点话题识别和追踪
[J]. 中文信息学报 , 2016 , 30 (1 ): 43 -50 .
Magsci
[本文引用: 2]
摘要
语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型。该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的。实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行。<br>
(Xu Jiajun Yang Yang Yao Tianfang et al .LDA Based Hot Topic Detection and Tracking for the Forum
[J]. Journal of Chinese Information Processing , 2016 , 30 (1 ): 43 -50 .)
Magsci
[本文引用: 2]
摘要
语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型。该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的。实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行。<br>
[19]
张良均 , 王路 , 谭立云 , 等 .Python 数据分析与挖掘实战 [M]. 机械工业出版社, 2015 .
[本文引用: 1]
(Zhang Liangjun Wang Lu Tan Liyun et al .Python Practice of Data Analysis and Mining [M]. Machinery Industry Press, 2015 .)
[本文引用: 1]
[20]
jieba
[CP/OL].[2016 -11 -23 ]. .
URL
[本文引用: 1]
[21]
哈尔滨工业大学停用词词典
[OL]. [2016 -11 -23 ]. .
URL
[本文引用: 2]
(Stop Word Dictionary by Harbin Institute of Technology
[OL]. [2016 -11 -23 ].
URL
[本文引用: 2]
[22]
JGibbLDA: A Java Implementation of Latent Dirichlet Allocation (LDA) Using Gibbs Sampling for Parameter Estimation and Inference
[CP/OL]. [2016 -11 -23 ]. .
URL
[本文引用: 1]
Dynamic Topic Model
6
2006
... 话题识别和跟踪研究中, LDA[1 ] 主题模型是近年来文本挖掘领域的一个热门研究方向, 主题模型具有优秀的降维能力、针对复杂系统的建模能力和良好的扩展性.利用主题建模挖掘出的主题可以帮助人们理解海量文本背后隐藏的语义, 也可以作为其他文本分析方法的输入, 完成文本分类、话题检测、文本自动摘要和关联判断等多方面的文本挖掘任务. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
... LDA[1 ] 模型中对话题的定义为: 一组语义上相关的词及这些词在该话题上的分布概率.由于无法对LDA模型的未知参数进行求解, 在这里使用Gibbs Sampling的方法近似求解, Gibbs Sampling[16 ] 通过迭代采样达到逼近真实结果的效果, 其关键点在于对当前单词采样概率的求解, 如公式(1)[1 ] 所示. ...
... [1 ]所示. ...
... 其中, w 为词表个数; K 为话题数目; ij 项, 表示第j 个话题中第i 个词出现的次数; CDK 中的第dj 项, 表示第d 篇文档中, 第j 个话题包含的词的数目.通过Gibbs Sampling方法, 可以得到θ 、ϕ 的后验值, 如公式(2)[1 ] 和公式(3)[1 ] 所示. ...
... [1 ]所示. ...
基于LDA的微博文本主题建模方法研究述评
2
2012
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较[2 ] ...
基于LDA的微博文本主题建模方法研究述评
2
2012
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较[2 ] ...
TwitterRank: Finding Topic-sensitive Influential Twitterers
2
2010
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
Empirical Study of Topic Modeling in Twitter
2
2010
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
The Author- Topic Model for Authors and Documents
2
2004
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
Comparing Twitter and Traditional Media Using Topic Models
3
2011
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... [6 ]提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
Labeled LDA: A Supervised Topic Model for Credit Attribution in Multi-labeled Corpora
3
2009
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... [7 ]提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
基于MB-LDA模型的微博主题挖掘
3
2011
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... [8 ]提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
基于MB-LDA模型的微博主题挖掘
3
2011
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... [8 ]提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
基于LDA模型和微博热度的热点挖掘
2
2014
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
基于LDA模型和微博热度的热点挖掘
2
2014
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
基于微博的热点话题发现
2
2014
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
基于微博的热点话题发现
2
2014
... LDA主题模型具有优秀的降维能力和扎实的概率理论基础, 使其在短文本主题挖掘中具有很大的潜力.近年来, 为了提高LDA模型主题挖掘的效率和准确性, 出现很多对LDA模型的改进方法, 可归纳为纵向的过程扩展和横向的模型扩展[2 ] .一方面, 针对微博文本篇幅较短的局限, 基于操作过程扩展的方法考虑将微博文本进行适当的聚集, 这样短文本被聚集成相对适合挖掘的长文本.Weng等[3 ] 采用同一微博用户的所有微博文本聚集成一篇长文档的策略, 利用LDA模型进行主题挖掘.Hong等[4 ] 提出基于训练的用户模式建模和基于术语模式建模.另一方面, 为了适应微博短文本的主题挖掘, 规避短文本数据噪声大的影响, 提出基于模型扩展优化的LDA 模型, 典型的改进模型包括ATM[5 ] 、Twitter-LDA[6 ] 、Labeled-LDA[7 ] 、MB-LDA[8 ] 、HLDA[9 ] 以及MA-LDA[10 ] .Zhao等[6 ] 提出Twitter-LDA模型挖掘整个Twitter文本中具有代表性的文本主题.Ramage等[7 ] 提出Labeled-LDA, 一种基于标签的主题模型.张晨逸等[8 ] 提出微博生成模型MB-LDA, 该模型综合考虑了微博的文本关联关系和联系人关联关系, 这两种关系可以辅助微博的主题挖掘.文献[2, 11]对LDA模型的纵向和横向改进方法进行了比较总结, 如表1 所示. ...
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
基于EM-LDA综合模型的电商微博热点话题发现
0
2015
基于EM-LDA综合模型的电商微博热点话题发现
0
2015
Learning Author-topic Models from Text Corpora
1
2010
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
Topical Key Phrase Extraction from Twitter
1
2011
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
Characterizing Microblogs with Topic Models
1
2010
... LDA话题模型建模方法比较
[2 ] 模型 扩张方式 实现方式 优势 局限性 LDA[1 ] 无 直接使用 无需监督 主题挖掘不理想 基于用户聚集LDA[3 ] 过程扩展 文本聚集 解决短文本问题 只限微博用户层面建模, 需要人工干预 基于训练USER模式[4 ] 过程扩展 文本聚集、 解决短文本问题, 需要事先训练和人工干预, 若要更新 ATM[5 ] 模型扩展 文本聚集 解决短文本问题 只限微博用户层面主题建模 ATM扩展模型[12 ] 模型扩展 文本聚集 解决短文本问题 帖子层面主题少且不理想 Twitter-LDA[6 , 13 ] 模型扩展 文本聚集, 解决短文本问题和高频 一个帖子只能对应一个主题 Labeled-LDA[7 , 14 ] 模型扩展 引入标签信息 提高主题可解释性 要求文本具有足够的标签信息 MB-LDA[8 ] 模型扩展 引入结构化信息 解决短文本问题, 提高 主要针对会话类和转发类中文微博 HLDA[9 ] 模型扩展 引入微博评论数、 提高主题可解释性 主要针对具有高评论数和转发数的微博 MA-LDA[10 ] 模型扩展 引入时间特征 解决短文本问题, 提高 主要适应于短时间内被普遍关注的微博
本文鉴于LDA模型本身的优点和在短文话题识别上的优势, 又考虑到投诉文本与微博短文本不一样, 微博一般围绕一个话题展开, 包含评论、转发等额外信息; 但投诉文本没有一个明确的话题, 仅仅是客户的一条信息反馈, 文本结构简短, 内容复杂.因此, 本文提出一种基于LDA模型的移动投诉文本热点话题识别方法.首先对投诉文本聚类, 每一类使用Gibbs抽样方法进行话题的抽取; 然后对抽取的话题进行一系列的处理; 最后通过计算话题的文档支持率得出热点话题, 并在实验部分对本文方法进行了验证. ...
K-means算法研究综述
1
2011
... 本文采用k-means[15 ] 进行聚类, k-means是经典划分聚类算法.这种方法简单快速, 在对文档进行聚类前需要通过k值来确定簇数量.主要过程是从含n个文本的文档集中随机选择k个文本作为初始的聚类中心, 并通过计算得到其他文本到每个簇中心点的距离, 将文档划分到离它最近的簇中, 用迭代的方式不断重复上述过程, 直到满足准则函数或划分过程中相邻簇的中心不再发生变化为止.通过不断的迭代过程增加簇内的紧凑性, 降低簇间的相似性.图1 为本文聚类的流程. ...
K-means算法研究综述
1
2011
... 本文采用k-means[15 ] 进行聚类, k-means是经典划分聚类算法.这种方法简单快速, 在对文档进行聚类前需要通过k值来确定簇数量.主要过程是从含n个文本的文档集中随机选择k个文本作为初始的聚类中心, 并通过计算得到其他文本到每个簇中心点的距离, 将文档划分到离它最近的簇中, 用迭代的方式不断重复上述过程, 直到满足准则函数或划分过程中相邻簇的中心不再发生变化为止.通过不断的迭代过程增加簇内的紧凑性, 降低簇间的相似性.图1 为本文聚类的流程. ...
HMM参数估计的Gibbs抽样算法
1
2012
... LDA[1 ] 模型中对话题的定义为: 一组语义上相关的词及这些词在该话题上的分布概率.由于无法对LDA模型的未知参数进行求解, 在这里使用Gibbs Sampling的方法近似求解, Gibbs Sampling[16 ] 通过迭代采样达到逼近真实结果的效果, 其关键点在于对当前单词采样概率的求解, 如公式(1)[1 ] 所示. ...
HMM参数估计的Gibbs抽样算法
1
2012
... LDA[1 ] 模型中对话题的定义为: 一组语义上相关的词及这些词在该话题上的分布概率.由于无法对LDA模型的未知参数进行求解, 在这里使用Gibbs Sampling的方法近似求解, Gibbs Sampling[16 ] 通过迭代采样达到逼近真实结果的效果, 其关键点在于对当前单词采样概率的求解, 如公式(1)[1 ] 所示. ...
科技情报分析中LDA主题模型最优主题数的确定方法研究
3
2016
... 在推导参数之前, 需要预先将话题的数目K设置好, 数值越大则话题越多, 话题的颗粒度越小, 反之亦然.K的取值对LDA模型文本提取和拟合性能影响较大, 其最佳的确定可以通过两种方法: 一种是词汇被选中的概率p (w |T )[17 ] , 另一种是困惑度(perplexity)[17 ] .本文用困惑度确定K , 困惑度越小, 话题的拟合性就越好.困惑度计算如公式(4)[17 ] 所示. ...
... [17 ].本文用困惑度确定K , 困惑度越小, 话题的拟合性就越好.困惑度计算如公式(4)[17 ] 所示. ...
... [17 ]所示. ...
科技情报分析中LDA主题模型最优主题数的确定方法研究
3
2016
... 在推导参数之前, 需要预先将话题的数目K设置好, 数值越大则话题越多, 话题的颗粒度越小, 反之亦然.K的取值对LDA模型文本提取和拟合性能影响较大, 其最佳的确定可以通过两种方法: 一种是词汇被选中的概率p (w |T )[17 ] , 另一种是困惑度(perplexity)[17 ] .本文用困惑度确定K , 困惑度越小, 话题的拟合性就越好.困惑度计算如公式(4)[17 ] 所示. ...
... [17 ].本文用困惑度确定K , 困惑度越小, 话题的拟合性就越好.困惑度计算如公式(4)[17 ] 所示. ...
... [17 ]所示. ...
基于LDA模型的论坛热点话题识别和追踪
2
2016
... 根据LDA模型的原理, 每篇文档都是由数个不同的话题按照一定的比例生成的.这里假设一条经过预处理的投诉文本中有不少于话题z 中百分之几的词, 则认为这条投诉文本是话题z 的支持文档.之后使用徐佳俊等[18 ] 的方法计算文档话题支持率, 如公式(12)[18 ] 所示.如果在一个时间段内, 话题的支持文档的数量或者文档话题支持率超过一个设定的阈值, 那么这个话题就是热点话题. ...
... [18 ]所示.如果在一个时间段内, 话题的支持文档的数量或者文档话题支持率超过一个设定的阈值, 那么这个话题就是热点话题. ...
基于LDA模型的论坛热点话题识别和追踪
2
2016
... 根据LDA模型的原理, 每篇文档都是由数个不同的话题按照一定的比例生成的.这里假设一条经过预处理的投诉文本中有不少于话题z 中百分之几的词, 则认为这条投诉文本是话题z 的支持文档.之后使用徐佳俊等[18 ] 的方法计算文档话题支持率, 如公式(12)[18 ] 所示.如果在一个时间段内, 话题的支持文档的数量或者文档话题支持率超过一个设定的阈值, 那么这个话题就是热点话题. ...
... [18 ]所示.如果在一个时间段内, 话题的支持文档的数量或者文档话题支持率超过一个设定的阈值, 那么这个话题就是热点话题. ...
jieba
1
2016
... 本文所使用的数据是某电信公司投诉业务部提供的, 实验部分使用2015年3月-2015年4月的投诉文本, 其中, 3月份有20 000多条, 4月份有50 000多条, 前者用于训练提取话题和识别热点话题, 后者用于验证热点话题抽取的效果.分词使用的是结巴分词工具[20 ] , 停用词词典为哈尔滨工业大学的停用词词典[21 ] . ...
哈尔滨工业大学停用词词典
2
2016
... 通过箱型图分析[21 ] 进行话题支持文档数或者文档支持率阈值的设定, 箱型图的结构如图2 所示. ...
... 本文所使用的数据是某电信公司投诉业务部提供的, 实验部分使用2015年3月-2015年4月的投诉文本, 其中, 3月份有20 000多条, 4月份有50 000多条, 前者用于训练提取话题和识别热点话题, 后者用于验证热点话题抽取的效果.分词使用的是结巴分词工具[20 ] , 停用词词典为哈尔滨工业大学的停用词词典[21 ] . ...
哈尔滨工业大学停用词词典
2
2016
... 通过箱型图分析[21 ] 进行话题支持文档数或者文档支持率阈值的设定, 箱型图的结构如图2 所示. ...
... 本文所使用的数据是某电信公司投诉业务部提供的, 实验部分使用2015年3月-2015年4月的投诉文本, 其中, 3月份有20 000多条, 4月份有50 000多条, 前者用于训练提取话题和识别热点话题, 后者用于验证热点话题抽取的效果.分词使用的是结巴分词工具[20 ] , 停用词词典为哈尔滨工业大学的停用词词典[21 ] . ...
JGibbLDA: A Java Implementation of Latent Dirichlet Allocation (LDA) Using Gibbs Sampling for Parameter Estimation and Inference
1
2016
... 实验利用Gibbs Sampling方法进行参数推理, 使用基于Java的Gibbs Sampling开源工具包(JGibbLDA- v.1.0)[22 ] , 模型参数α 、β 默认值为50/k 和0.1, 每个话题下的词语个数设置为10. ...
 , 王荣波
, 王荣波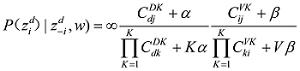
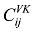
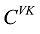
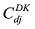
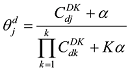
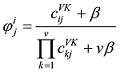
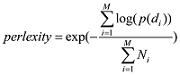
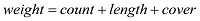
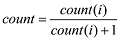
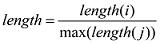
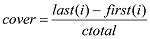
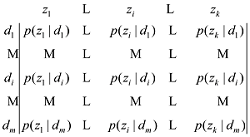
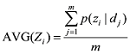
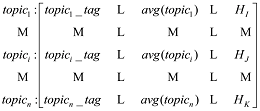
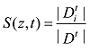
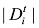







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}