吴维芳, 高宝俊 , 杨海霞, 孙含琳
, 杨海霞, 孙含琳
武汉大学经济与管理学院 武汉 430072
Wu Weifang, Gao Baojun, Yang Haixia, Sun Hanlin
中图分类号: F59 G350
通讯作者:
收稿日期: 2016-12-5
修回日期: 2017-03-8
网络出版日期: 2017-03-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
展开
摘要
【目的】通过对评论文本进行文本分析, 研究影响酒店用户满意度的因素, 为酒店管理者提供建议。【方法】利用Word2Vec对Tripadvisor.com酒店评论进行特征抽取和降维, 结合情感分析技术, 提取每类特征对应的情感, 构建计量经济模型分析酒店特征评价与用户满意度的关系。【结果】研究结果表明: (1)评论文本的情感表达越积极满意度越高, 但这种影响并非线性的, 而是呈现“U”形的; (2)用户评论文本中提到的特征类别数越多, 该用户越有可能倾向不满意; (3)消费者对豪华型酒店和经济型酒店特征类别的关注存在显著差异, 消费者对前者更关注员工服务, 对后者更注重清洁度; (4)对豪华型酒店, 消费者满意度受到网络(Internet)这个特征维度的显著影响, 而对于经济型酒店该维度的影响则不显著。【局限】样本的选择不够全面, 未来可爬取多个城市数据进行更全面分析。【结论】从评论文本角度建立了酒店特征与消费者满意度的联系, 为酒店在线口碑研究提供了理论依据。
关键词:
Abstract
[Objective] This paper analyzes the online hotel reviews to identify the factors influencing the customer’s satisfaction, and then provides suggestion to the management. [Methods] First, we extracted features and reduced dimensionality of travelers’ comments from Tripadvisor.com with the help of Word2Vec technique. Secondly, we extracted the characteristics of each type of the corresponding emotion based on sentiment analysis technology. Finally, we constructed an econometric model to analyze the correlation between the hotel reviews and users’ satisfaction. [Results] We found that positive reviewers were generally satisfied with the hotel service, however, there was no linear relations between the two factors. The more feature categories mentioned by the user in comments, the more likely he or she was not satisfied. The consumers paid more attention to the staff of the luxury hotels, while cared the cleanliness of the economic ones. Consumers’ attitudes towards luxury hotels were significantly affected by the Internet, which posed less obvious influences to the economic ones. [Limitations] The sample was not comprehensive, and more studies are needed to analyze data from multiple cities. [Conclusions] This study lays theoretical foundation for the online word-of-mouth research from the perspective of user generated contents.
Keywords:
随着Web2.0时代的到来和电子商务的迅猛发展, 在社交媒体网站上用户生成内容(User Generated Content)已经成为消费者和商家的主要信息来源。在线评论不仅能帮助潜在消费者做出购买决策, 还能帮助相关管理者提高其产品或服务的质量。很多研究表明在线评论影响销量和消费者购买决策[1-2], 如在线影评与票房收入有显著相关关系, 在线书评对书籍销量有积极影响。而在线评论不仅有数值属性[3-4](Numerical Attribute), 如: 有用性投票、星级评分、评论数量; 还有文本属性[5](Text Attribute), 如: 可读性、评论文本字数、客观性、可信度等, 这些因素均可能对消费者购买意愿产生影响。然而很多学者研究对象是在线评论的数值评分[6-7], 只有少量学者研究了文本内容对在线评论的影响[8-9]。
相关经济学和市场理论[10]证明产品和服务有多维属性, 由于消费者的偏好不同, 对酒店功能和服务的预期也不同。即用户参考酒店评论进行决策时, 会依其偏好, 只关注或更加关注某些方面的特征。其中文献[9]考虑了多维特征对酒店经济效应的影响, 也有学者尝试对产品和服务的特征赋予不同的重要程度。因此只考虑数值评分不足以对用户生成内容得到全面和精确的评估。
考虑到用户生成的内容——即文本评论包含更多更可靠的信息, 这些信息在旅游网站的星级评分中无法反映出来, 此外用户关心的一些特征维度可能未体现在网站的定量打分体系中, 因此本文基于在线评论文本进行研究。通过对消费者的评论文本进行文本挖掘, 从用户生成内容得到顾客真正关心的维度, 更能反映对酒店的真实意见。鉴于此, 本文结合自然语言处理、机器学习和情感分析技术过滤保留在线评论中最有价值的信息。利用Word2Vec对爬取的所有酒店评论文本进行skip-gram训练, 对关键词的语义距离进行聚类分析, 然后把每条评论分成一个个评价单元, 用机器学习方法对评价单元进行训练, 得到每个评价单元属于某一主题特征; 接着对其进行情感倾向和强度识别分析[11], 以此得到每个评价单元的特征对应的情感分数; 最后汇总每条评论中提到各类主题特征的情感分数, 构建计量经济模型, 分析酒店特征的情感倾向与消费者满意度的关系, 能够识别酒店特征的重要程度; 此外, 按照酒店星级, 将酒店分为豪华型酒店和经济型酒店, 分析消费者对不同档次酒店特征的偏好。
基于在线评论文本研究酒店特征对消费者满意度的影响程度, 现有研究主要采用以下方法: 领域专家意见、语法研究方法、以及模型分析法。
最直观的方法是根据相关领域专家的认知意见对酒店特征进行识别并评价, 但是专家意见无法代表广大顾客的真实体验, 另外专家意见带有很强的主观性难免会受到诸多偏见的影响[12-13]。语法研究方法是指: 被越多的形容词修饰的特征词, 可推测这些特征越重要。通过句法依存关系, 确定修饰特征词的形容词个数, 然后聚类形容词识别特征的重要度[14-15]。文献[16]利用多变量回归识别“特征-观点对”的重要性, 将其作为自变量, 星级评分作为因变量, 计算每个特征的重要度。但这个回归方法存在一定问题, 因为有研究证明一星级评论比五星级评论往往能给用户带来更多的有用信息[2]。文献[17]采用计量模型研究特征的情感对消费者意愿的影响, 但该方法在分析特征的情感时, 只考虑情感极性, 未考虑情感强度。文献[18]改善了文献[19]对在线评论意见挖掘的范式, 对最常见名词运用一组过滤器, 通过NLP技术自动识别产品特征属性, 并发现特征属性的近义词。王伟等[20]对亚马逊386款数码相机的评论数据, 结合情感分析和计量模型, 分析用户购买意愿与产品特征评价的关系。本文借鉴王伟等[20]的思路, 结合酒店特征情感和计量模型, 分析消费者满意度与酒店特征评价的关系。
情感分析作为当前自然语言处理领域中最为活跃的研究之一[21], 是指对在线评论文本进行情感分析, 判断文本的情感极性是积极、消极还是中立, 或识别用户的观点是“赞同”还是“反对”。该技术被广泛用于预测产品销量、政治投票、票房收入、股票波动等, 如文献[22]运用评论对产品和商家进行排名, 文献[23]将Twitter情感分析用于预测选举结果, 文献[24-25]运用推特数据、电影评论以及博客文本进行情感分析, 预测电影票房收入。情感分析涉及多种技术, 如自然语言处理、信息抽取、机器学习等。特征情感预测模型代表工作是Liu等[19]的研究, 他们首先识别出评论文本中的产品特征属性, 然后针对每个特征属性, 得到文本中的正向情感和负向情感内容, 最后输出特征属性及其对应的情感极性。Li等[26]和Blair-Goldensohn等[27]为当地服务行业如餐馆和酒店构建了意见总结系统, 通过频繁名词方法挖掘服务相关的特征如Service、Value, 然后汇总每个特征的情感分数。本文情感分析方法借鉴前人采用基于情感词典的方法计算情感指标[28-31], 得到特征对应的情感分数, 旨在为后面计量模型作进一步分析。
本文研究包括文本语料预处理、Word2Vec、基于监督学习方法的特征分类、情感分析和有序逻辑回归模型。笔者采用Word2Vec工具, 将词映射到K维向量空间, 向量空间上的相似度可以用来表示文本语义上的相似度[32]。
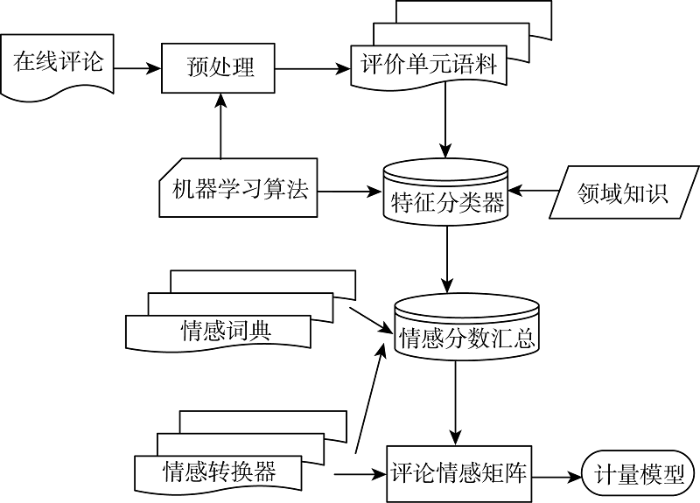
首先根据Word2Vec得到评论语料可以分为7大类特征维度, 接着进行特征识别, 即得到每个短分句所属的特征类别, 然后通过情感分析技术计算其情感分数, 最后归类汇总是指根据评论(Reviewid)汇总每条评论在不同特征类别的情感分数。在特征识别阶段, 主要根据特征词进行人工标记, 但同时结合领域知识判断属于哪个大类, “the food was great”由每个类别出现的特征词可标记为“Food”维度, 而存在少量短分句表意模糊需要结合酒店领域知识判断, 如“I think the room is fairly clean”则标记为“Cleanliness”维度。本文研究框架如图1所示。
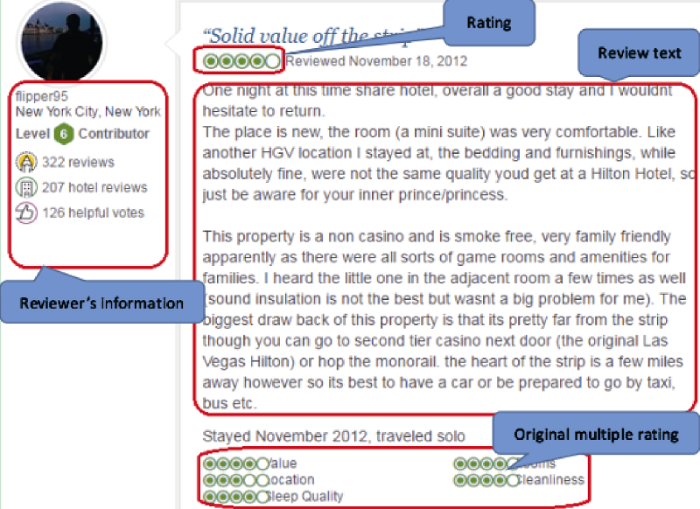
2013年10月1日, 笔者利用火车头采集器LocoySpider (http://www.locoy.com)采集Tripadvisor.com在2012年1月1日-2013年9月30日Las Vegas城市所有酒店的在线评论, Tripadvisor.com在线评论详情页如图2所示, 采集包括在Location、Rooms、Value、Cleanliness、Sleep Quality等5个维度的星级打分(Original Multiple Rating), 评论的ID、总体评分(Rating), 以及评论的标题、文本(Review Text)。经过清洗得到217 518条英文酒店评论, 针对 Las Vegas的所有在线评论(217 518条评论, 约4 000万个单词)进行Word2Vec分析, 训练得到每个词的向量。在计量模型中随机选取5 124条评论, 其中豪华型酒店2 625条, 经济型酒店2 499条。
对于英文文本语料, 处理步骤如下。
(1) 单词词根化、统一小写;
(2) 去停用词, 如连接词、介词、人称代词“and, in, you”等;
(3) 移除与情感、酒店特征无关的单词, 如酒店评论文本中的“hotel, any”等。
(1) Duan等[33]提取频繁出现的名词作为酒店候选特征, 本文通过对文本语料分析初步得到酒店评论中的高频名词, 词云图如图3所示, 发现用户对早餐(breakfast)、自助餐(buffet)、清洁度(clean)、无线网络(wireless)、房间(room)、价值(worth)、位置(location)等比较关心。
(2) 除去高频词中的噪音, 根据文献[18]过滤高频词噪音的方法, 采用极大似然比测试每一个已识别的名词, 计算其在相关类别评论(如酒店评论)和非相关类别评论(如书籍评论)的相对频率差异。似然比较低的名词被认为是不相关的, 过滤掉。由于似然比是渐进χ2分布, 阈值设置高于p=.05水平的名词作为候选产品特征, 同时人工编译一组不相关的名词, 比如命名实体hotel、酒店品牌Hilton, 然后从候选名词中去掉这些不相关的名词。最后一共得到55个酒店特征名词。
(3) 采用Word2Vec工具对包含40 953 696个词的酒店评论文本训练(threads = 3, vectors = 100, window=12), 得到每个词的词向量, 然后抽取步骤(2)中55个酒店特征名词向量表示, 将词向量之间的欧几里得距离定义为词之间的相似度, 通过K-means聚类算法将获取的词向量进行聚类。
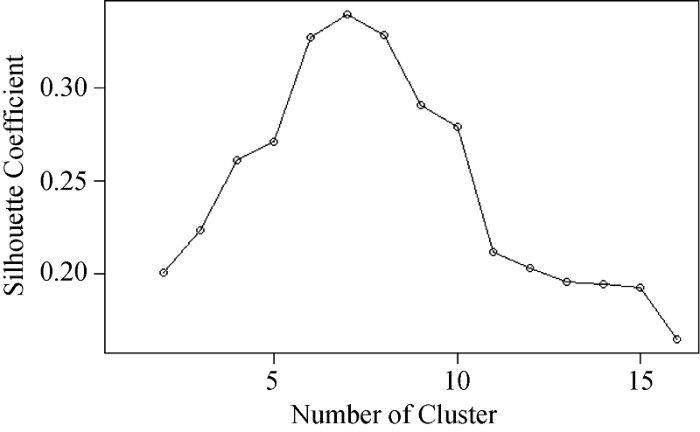
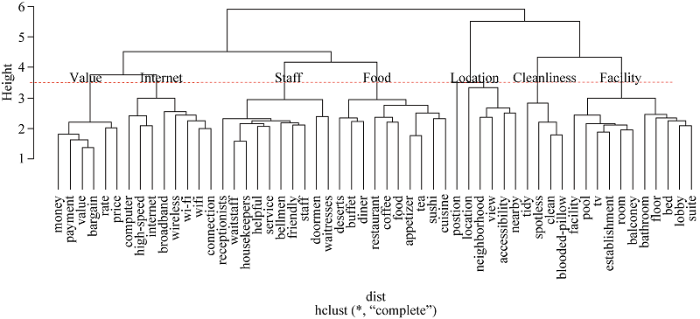
采用轮廓系数(Silhouette Coefficient)考察簇的分离情况和簇的紧凑情况以评估聚类质量。将聚类类别K设置为从2到15, 重复执行50次, 得到结果如图4和图5所示。
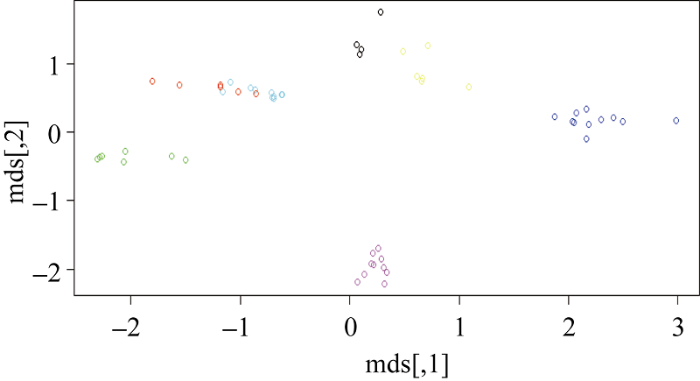
从图4可以明显看到在K=7时达到顶峰, 根据Silhouette Coefficient的定义, 值较大时的K较优。最后将数据从100维降低到2维平面, 并绘制聚类效果。通过文本聚类分析, 可以将酒店特征分为7类: Food(餐饮)、Facility(设施)、Staff(员工服务)、Cleanliness(清洁度)、Location(位置)、Value(物有所值)、Internet(网络)。聚类结果如图6所示。
与本文类似的文献[16,33], 前者将酒店评论分成句子, 然后运用Naive Bayes选择名词作为训练特征将每个句子划分到5个维度, 其准确率(Accuracy)达到68%; 后者将餐馆评论划分成句子, 然后运用Support Vector Machine将句子分到食品、服务、价格、氛围、叙事类和其他6个维度, 其中食物是准确率(Precision)最高维度, 达到81.43%, 叙事类最低为49.15%, 平均准确率为70.34%。
根据前一步, 已经将顾客关注的特征分为Food(餐饮)、Facility(设施)、Staff(员工服务)、Cleanliness(清洁度)、Location(位置)、Value (物有所值)、Internet(网络)等7大类, 借鉴文献[16,33], 首先根据标点符号“, 、.、!、?”等将每条评论划分成短分句, 然后去掉完全没有出现积极或消极情感词的客观句, 如“we went up to the room”, 接着去掉未包含酒店特征词的句子, 如“other complaints are minor”。最后得到约10万条意见单元, 其平均字数为6。评价单元示例如表1所示。
表1 评价单元示例
| reviewid | Opinion Unit | Word_count | Label |
|---|---|---|---|
| 155764734 | the rooms were a great size and layout | 8 | Facility |
| 155344163 | it is fairly clean | 4 | Cleanliness |
| 117415795 | the food was great | 2 | Food |
| 117474538 | the location at the cosmo is great | 7 | Location |
| 117490549 | food amazing | 2 | Food |
| 118435844 | great value for the money | 5 | Value |
| 118683963 | internet is free and fast | 5 | Internet |
| 143482015 | staff was very friendly and helpful. | 6 | Staff |
使用机器学习方法, 旨在得到每个短句所属的特征类别。由于不确定哪种分类器更适合本文数据集, 故分别使用Multinomial Naive Bayes和Support Vector Machines两种分类器进行分类。结果如表2所示, 表明SVM更适合本文的特征分类, 每个类别的分类准确率(Precision)均高于Multinomial Naive Bayes, 且平均准确率为80%, 比文献[16,33]分类效果好, 故后续采用SVM对所有评价单元进行分类。
表2 基于机器学习的特征分类效果比较
| 特征 | Naive Bayes | SVM | ||
|---|---|---|---|---|
| Precision | Recall | Precision | Recall | |
| Cleanliness | 74% | 78% | 75% | 77% |
| Facility | 78% | 64% | 82% | 82% |
| Food | 87% | 83% | 86% | 83% |
| Internet | 73% | 88% | 74% | 86% |
| Location | 65% | 84% | 69% | 85% |
| Staff | 88% | 85% | 87% | 87% |
| Value | 80% | 80% | 80% | 81% |
| Total | Accuracy 79% | Accuracy 80% | ||
运用基于情感词典方法计算每个短句的情感。在情感分数的计算中, 情感词典的选择至关重要, 因为同一情感词在不同的场景下的意思表达可能不一致[28]。本文选择的情感词典来自于文献[19]。以往研究中通常只标记情感词和短语, 并未考虑到情感转换器, 而这种方法并不科学。本文借鉴Ding等[29]基于语料的方法, 考虑了情感转换器, 也称效价转换器[30-31], 是由一些可以改变情感倾向的词和短语构成。典型的否定转换器, 如: 不(not), 决不(never), 没有(none), 没有人(nobody), 没有哪个地方(nowhere), 也不(neither), 以及不能(cannot)等。“这个酒店的位置非常棒[+1]”, 由 于否定词“不”, 将句子变成“这个酒店的位置不是非常棒[-1]”。这一步对计算所得的情感分数, 使用意见加总器计算出每条评论里每个短句的情感分数。假设句子${{s}_{i}}$含有一系列情感转换词$\{{{W}_{i1}}^{n},{{W}_{i2}}^{n},\cdots $ ${{W}_{ij}}^{n}\}$, 以及一系列情感极性词$\{{{W}_{i1}}^{p},{{W}_{i2}}^{p},\cdots {{W}_{ij}}^{p}\}$。对于句子${{s}_{i}}$中的特征$Sent{{i}_{i}}$由下面加总函数决定:
${{W}_{neg}}=\sum{{{W}_{ij}}^{n}}\bmod 2$ (1)
${{C}_{i}}=\sum{{{W}_{ij}}^{p}{{(-1)}^{2+{{W}_{neg}}}}}$ (2)
$Sent{{i}_{i}}={{C}_{i}}/\sqrt{word\_coun{{t}_{i}}}$ (3)
由公式(1)至公式(3)可以得到每个评价单元的情感分数, 文献[16, 33]指出每个评价单元非常短小, 所得情感分数就是消费者对相应酒店特征的意见看法。最后, 根据每条评论, 汇总每类特征的情感分数, 得到评论特征情感矩阵, 由此得到每条评论中对Food(餐饮)、Facility(设施)、Staff(员工服务)、Cleanliness(清洁度)、Location(位置)、Value (物有所值)、Internet(网络)这7个维度的情感分数。
本文基于在线评论文本进行研究, 之所以不选择网站提供的数值型星级打分而是选择文本型的评论内容, 是因为笔者认为用户生成的内容——即文本评论包含更多更可靠的信息, 这些信息在旅游网站的星级评分中是无法反应出来的, 另外用户关心的一些特征维度可能在网站的定量打分体系中未体现。由于本研究的因变量是有序变量, 其满意度水平从1 到5依次增大, 代表满意度由弱到强, 因此选择有序逻辑回归(Ordinal Logistic Regression)方法建立回归模型[34]。
从表3描述性统计结果分析, 新维度下顾客对每个维度的情感表达有正有负, 其中对设施(Facility)这个维度其最小值为-4.65, 最大值为11.1, 不管是从消极情感的强度还是积极情感的强度, 其绝对值均是7个维度中最大的, 表明情感最强烈; 其次是人员服务(Staff)这个维度, 其最小值为-4.02, 最大值为8.17, 情感强烈程度仅次于设施(Facility)维度。而对于原始维度Location、Rooms、Value、Cleanliness、SleepQuality, 这些维度的打分从1到5, 平均值比较接近, 维度间可能存在较强相关性, 而且这些数据都存在一定的缺失, 数据并不完整。
表3 变量的描述性统计分析结果
| Statistic | N | Mean | St.Dev. | Min | Pctl (25) | Median | Pctl (75) | Max |
|---|---|---|---|---|---|---|---|---|
| food_senti | 5124 | 0.21 | 0.44 | -1.64 | 0 | 0 | 0.39 | 3.05 |
| facilities_senti | 5124 | 0.6 | 1.05 | -4.65 | 0 | 0.41 | 1.12 | 11.1 |
| value_senti | 5124 | 0.11 | 0.45 | -2.52 | 0 | 0 | 0.22 | 3.78 |
| staff_senti | 5124 | 0.35 | 0.73 | -4.02 | 0 | 0.12 | 0.71 | 8.17 |
| cleanliness_senti | 5124 | 0.2 | 0.56 | -2.8 | 0 | 0 | 0.41 | 4.16 |
| location_senti | 5124 | 0.21 | 0.38 | -1.45 | 0 | 0 | 0.38 | 2.77 |
| internet_senti | 5124 | 0.05 | 0.28 | -1.74 | 0 | 0 | 0 | 4.49 |
| location | 4310 | 4.31 | 0.96 | 1 | 3 | 4 | 5 | 5 |
| rooms | 4356 | 3.96 | 1.17 | 1 | 3 | 4 | 5 | 5 |
| value | 4862 | 3.87 | 1.21 | 1 | 3 | 4 | 5 | 5 |
| cleanliness | 4842 | 3.94 | 1.21 | 1 | 3 | 4 | 5 | 5 |
| sleepquality | 4074 | 4.03 | 1.18 | 1 | 3 | 4 | 5 | 5 |
| ave_sentiment | 5124 | 0.24 | 0.26 | -1.53 | 0.08 | 0.23 | 0.39 | 2.29 |
| AvgRating | 5124 | 3.78 | 1.22 | 1 | 3 | 4 | 5 | 5 |
对选取的5 214条评论进行情感分析, 对新生成的各个维度进行相关性考察, 如表4所示。
表4 新维度下的相关系数表
| Food | Facilitity | Value | Staff | Clean | Location | Internet | |
|---|---|---|---|---|---|---|---|
| Food | 1 | 0.18 | 0.09 | 0.13 | 0.14 | 0.09 | 0.07 |
| Facilitity | 1 | 0.06 | 0.22 | 0.15 | 0.18 | 0.07 | |
| Value | 1 | 0.10 | 0.13 | 0.04 | 0.11 | ||
| Staff | 1 | 0.16 | 0.12 | 0.08 | |||
| Cleanliness | 1 | 0.06 | 0.11 | ||||
| Location | 1 | -0.003* | |||||
| Internet | 1 |
表5表明网站原始的5个维度之间相关系数是显著的, 说明彼此是相关的。原始5个维度相关系数最小的为0.43, 最大的达到0.73。这种高度的相关性及显著性说明这个评价模型在维度的划分上不够合理, 存在一定的问题, 不能够真实准确地反映顾客对酒店某些方面的实际态度。而新维度两两之间相关系数比较小, 最大也只有0.22。除了网络(Internet)与位置(Location)相关系数为负数, 其他维度之间的相关系数均为正数, 说明消费者对某个维度感受会受到其他维度的正向影响。因此, 为了研究不同特征对酒店总体满意度的影响, 利用新维度下的数据是合理的。
表5 原始维度的相关系数表
| Location | Rooms | Value | Clean | SleepQuality | |
|---|---|---|---|---|---|
| Location | 1 | 0.61*** | 0.43** | 0.49*** | 0.53*** |
| Rooms | 1 | 0.57*** | 0.73*** | 0.72*** | |
| Value | 1 | 0.62*** | 0.61*** | ||
| Cleanliness | 1 | 0.65*** | |||
| SleepQuality | 1 |
对酒店特征的研究颇多, 经典理论SERVQUAL模型[35]往往问项过多、理论性太强, 随着点评网站和旅游网站的兴起, 传统问卷不再是获取数据的必经途径。有不少学者对酒店特征进行了相关研究, 如Liu等[36]对酒店清洁度、位置、房间、服务、睡眠质量、物有所值等维度进行研究; 文献[33]研究酒店的服务、餐饮、设施、卫生、位置、价格等维度对酒店满意度的影响; 熊伟等[37]研究酒店的房间、网络、餐饮、选址等因素对酒店综合满意度的影响。文献[38]表明价值、房间和服务是顾客对酒店最关注的因素, 而文献[37]指出消费者对不同档次的酒店偏好不同, 豪华型酒店的消费者对网络要求严格, 而经济型酒店的客人对牙膏、牙刷等基本清洁服务有比较高的要求。从整体上看, 关于酒店满意度的研究已经比较深入, 但资料数据主要是通过调查问卷或采集数值评分, 未从用户生成的文本内容挖掘消费者的真实想法。针对此, 本文对专业且大型的旅游点评网的网友评论进行整理分析, 总结出消费者对酒店特征关注偏好以及其偏好评价对酒店满意度的影响, 以期对酒店满意度研究提供一定参考。
本文计量模型中, 模型(1)将顾客总体满意度作为因变量, 人员服务(staff_senti)、餐饮(food_senti)、清洁度(cleanliness_senti)、设施(facility_senti)、位置(location_senti)、价格(value_senti)作为影响总体满意度的自变量, 并控制了酒店个体的固定效应。
有研究表明, 在不同档次的酒店中, 顾客对不同档次酒店的体验和偏好不同[39]。为了考察顾客对不同档次酒店各维度的关注情况, 笔者按照酒店星级将酒店分为豪华型和经济型: 其中星级水平大于等于4的为豪华型酒店, 星级水平小于等于3的为经济型酒店。模型(2)和模型(3)分别对豪华型和经济型数据进行回归和对比分析。
从消费者在评论文本提到的特征类别数和总体情感表达进行研究, 模型(4)以顾客总体满意度作为因变量, 评论文本提到的特征类别数(Num_of_ feature)、总体情感表达(ave_sentiment)以及总体情感强度(sentiment^2)作为自变量, 回归输出结果如表6所示。
表6 回归模型结果
| Dependent variable: as.factor(AvgRating) | ||||
|---|---|---|---|---|
| (1) | (2) | (3) | (4) | |
| y≥2 | 2.0906*** | 1.8908*** | 2.3932*** | 2.1126*** |
| -0.0571 | (0.0747) | (0.0925) | (0.0600) | |
| y≥3 | 1.0706*** | 0.8228*** | 1.3668*** | 0.9845*** |
| -0.0438 | (0.0589) | (0.0686) | (0.0457) | |
| y≥4 | -0.2140*** | -0.7763*** | 0.3546*** | -0.4444*** |
| -0.0402 | (0.0577) | (0.0605) | (0.0429) | |
| y≥5 | -1.6895*** | -2.5997*** | -0.9835*** | -1.9997*** |
| -0.0456 | (0.0735) | (0.0626) | (0.0494) | |
| food_senti | 0.3006*** | 0.4529*** | 0.4552*** | |
| -0.0626 | (0.0786) | (0.1131) | ||
| facility_senti | 0.6049*** | 0.5666*** | 0.4389*** | |
| -0.0296 | (0.0415) | (0.0440) | ||
| value_senti | 0.3540*** | 0.5665*** | 0.6579*** | |
| -0.0599 | (0.0724) | (0.1231) | ||
| staff_senti | 0.7608*** | 0.8931*** | 0.7486*** | |
| -0.0424 | (0.0592) | (0.0651) | ||
| cleanliness_senti | 0.4665*** | 0.6457*** | 0.7906*** | |
| -0.0499 | (0.0604) | (0.1069) | ||
| location_senti | 0.5236*** | 0.4926*** | 0.3709** | |
| -0.0731 | (0.0984) | (0.1138) | ||
| internet_senti | 0.0624 | 0.3743*** | -0.1412 | |
| -0.0964 | (0.1049) | (0.3502) | ||
| ave_sentiment | 6.7401*** | |||
| (0.1954) | ||||
| sentiment^2 | -3.7624*** | |||
| (0.2259) | ||||
| Num_of_feature | -0.0802*** | |||
| (0.0178) | ||||
| Observations | 5, 124 | 2, 625 | 2, 499 | 5, 124 |
| R2 | 0.2571 | 0.3437 | 0.2087 | 0.3229 |
| chi2 (df = 7) | 1 424.3920*** | 1 037.0600*** | 538.1301*** | 1 863.1670*** |
表6中模型的回归结果, 模型(1)表明涉及设施(Facility)、人员服务(Staff)、位置(Location)、清洁度(Clean)、食物(Food)、价格(Value)等特征维度, 消费者的满意度受到这些维度情感的正向影响, 其中人员服务(Staff)特征维度的系数为(0.7608, p=-0.0424), 其优势比OR(Odd Ratio)=2.139988; 设施(Facility)这个特征维度的系数为(0.6049, p=-0.0296), 其优势比OR= 1.831069。优势比表明自变量增加一个单位, 变量对发生概率的影响程度。由上述系数表明人员服务明显比其他特征维度的优势比大, 表明酒店提供的人员服务质量对顾客评分的影响最大, 其次是设施。而其中网络(Internet)对满意度的影响不显著, 可能是网络这个维度概念在酒店出现得比较晚, 不如其他维度广为熟知, 可能对满意度有一定影响但只有少数消费者有意识在评论中对该维度表达。
通过模型(2)和模型(3)对比发现, 对于豪华型酒店, 人员服务(Staff)对消费者满意度影响最大, 其系数为(0.8931, p=0.0592, OR=2.44269), 而对于经济型酒店, 虽然该维度对用户满意度影响很大, 但其系数为(0.7486, p=0.0651, OR=2.114038), 表明人员服务对消费者满意度影响方面, 经济型酒店低于豪华型酒店。对经济型酒店, 最影响消费者满意度的是酒店的清洁程度(Cleanliness), 经济型酒店越干净整洁, 顾客越容易满意。而且, 网络(Internet)这个特征维度对不同档次酒店的满意度影响不同, 对于豪华型酒店, 网络覆盖程度、易用程度对消费者满意度有正向影响, 可能选择豪华型酒店的消费者更多是商务出行的用户, 由于办公需求, 满意度明显受到网络好坏的影响。而对经济型酒店, 网络特征维度对满意度则没有显著影响。
对于模型(4), 顾客的极度满意情绪或不满情绪在评论文本中得到体现, 故分析评论文本的内容至关重要。其中文本中的情感表达与满意度感知方向一致, 情感表达越正向, 满意度越高, 而情感表达的强度对满意度的影响是非正向的。另外, 评论文本中提到的特征数量越多, 满意度越低。由此表明, 在评论文本中提到的特征维度数量越少, 用户满意度越高。
通过对Tripadvisor.com酒店原始维度评价体系进行分析, 表明该网站所划分的“位置、房间、价格、睡眠质量、清洁度”各维度相关性较高, 另外还存在消费者在评分时不能确定某种感受属于哪一个维度, 消费者想评价的特征又没有相应的维度可以评价, 这从侧面反映对定量的星级评论进行研究时存在不真实、不完整、不准确的问题。
通过对评论文本进行宏观和微观的文本分析, 并结合情感分析技术, 建立有序逻辑回归模型, 发现对酒店总体满意度影响最大的是设施, 如房间大小、卧室舒适程度、阳台布局、游泳池等, 其次是人员服务。对酒店档次进行分类后发现, 入住豪华型酒店消费者满意度明显受到网络维度的影响, WiFi、Internet的连接和易用程度对满意度的影响较大。同时选择豪华型酒店的顾客最关注酒店的人员服务, 而对经济型酒店消费者满意度影响最大的清洁程度。本文的研究结果有助于酒店管理者以最低成本投入换来最高的总体满意度: 酒店重心应放在设施和服务这两个维度上, 致力于为顾客留下美好的第一印象和最后印象; 豪华型酒店应该意识到网络这个维度对消费者满意度有着显著影响, 经济型酒店则需要保证酒店的清洁度, 注意卫生管理。通过对酒店评论文本分析, 不同类型酒店的管理者可以用更少的投入获得更显著的回报, 这对酒店的长远发展具有重要战略意义。
本文的不足之处在于: 样本的选择不够全面。笔者在获取酒店文本评论时, 只面向一个城市, 而有研究表明顾客在不同的城市选择酒店时关注点也是不同的, 比如顾客评论伦敦酒店清洁度时, Bug(虫子)可能是高频词, 而本文分析的拉斯维加斯酒店语料中该词几乎没有出现, 由于特定地理气候, 影响消费者对满意度感知的特征因素往往不相同。未来研究可从多个城市收集样本进行全面的对比分析。
吴维芳: 设计研究方案, 进行数据分析, 论文撰写及最终版本修订;
高宝俊: 提出研究思路, 采集、清洗数据, 提出论文修改建议;
杨海霞: 分析数据, 提出论文修改建议;
孙含琳: 采集、清洗数据。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: weifang@whu.edu.cn。
[1] 吴维芳, 高宝俊, 孙含琳. LasVegas.csv. 拉斯维加斯酒店的评论数据.
[2] 吴维芳, 高宝俊, 杨海霞. HotelText_word2vec.bin. 评论语料的词向量表示数据.
[3]吴维芳, 高宝俊, 杨海霞. aspect-sentimentsumscore.RData. 评论的特征情感矩阵数据.
| [1] |
Do Online Reviews Matter? - An Empirical Investigation of Panel Data [J].https://doi.org/10.1016/j.dss.2008.04.001 URL [本文引用: 1] 摘要
ABSTRACT This study examines the persuasive effect and awareness effect of online user reviews on movies' daily box office performance. In contrast to earlier studies that take online user reviews as an exogenous factor, we consider reviews both influencing and influenced by movie sales. The consideration of the endogenous nature of online user reviews significantly changes the analysis. Our result shows that the rating of online user reviews has no significant impact on movies' box office revenues after accounting for the endogeneity, indicating that online user reviews have little persuasive effect on consumer purchase decisions. Nevertheless, we find that box office sales are significantly influenced by the volume of online posting, suggesting the importance of awareness effect. The finding of awareness effect for online user reviews is surprising as online reviews under the analysis are posted to the same website and are not expected to increase product awareness. We attribute the effect to online user reviews as an indicator of the intensity of underlying word-of-mouth that plays a dominant role in driving box office revenues.
|
| [2] |
The Effect of Word of Mouth on Sales: Online Book Reviews [J]. |
| [3] |
什么样的产品评论最有用?——在线评论数量特征和文本特征对其有用性的影响研究 [J].
随着电子商务在中国的快速发展,网络上有关产品的客户评论日益增多,越来越多的产品评论使得买卖双方都无法快速定位最好的评论和了解产品质量。本文基于可达性—可诊断性模型和不确定性降低理论,构建了产品评论有用性影响因素模型,并以两种产品的1 238条在线评论数据对研究假设进行了检验。结果表明,体验型产品评论的感知有用性显著高于搜索型产品;产品类型在评分极端性对感知有用性的影响中起调节作用,相比于搜索型产品,体验型产品评分极端性对感知有用性的正向影响更强;产品类型在评论客观性对感知有用性的影响中起调节作用,体验型产品评论的客观性对感知有用性有显著的正向影响,而搜索型产品却无此效应。本研究不仅拓展了劝服理论和社会互动理论,对于网络零售商的客户互动管理也具有重要的实践意义。
What is the Most Helpful Product Review? ——The Effect of Online Reviews’ Quantitative and Textual Features on Its Helpfulness [J].
随着电子商务在中国的快速发展,网络上有关产品的客户评论日益增多,越来越多的产品评论使得买卖双方都无法快速定位最好的评论和了解产品质量。本文基于可达性—可诊断性模型和不确定性降低理论,构建了产品评论有用性影响因素模型,并以两种产品的1 238条在线评论数据对研究假设进行了检验。结果表明,体验型产品评论的感知有用性显著高于搜索型产品;产品类型在评分极端性对感知有用性的影响中起调节作用,相比于搜索型产品,体验型产品评分极端性对感知有用性的正向影响更强;产品类型在评论客观性对感知有用性的影响中起调节作用,体验型产品评论的客观性对感知有用性有显著的正向影响,而搜索型产品却无此效应。本研究不仅拓展了劝服理论和社会互动理论,对于网络零售商的客户互动管理也具有重要的实践意义。
|
| [4] |
在线负面评论对体验型产品销量的影响——基于商家回复视角 [J].
本文从负面评论者专业度、 负面评论内容评分、 产品价格及负面评论星级评分四个方面分析在线负面评论对体验型产品销量的影响,并重点分析商家回复对负面评论内容评分与体验型产品销量关系的调节作用.研究表明:负面评论者专业度、 负面评论内容评分对体验型产品销量具有显著影响,且星级评论者对体验型产品销量的影响力大于一般评论者;产品价格、 负面评论星级评分对体验型产品销量没有显著影响;商家回复及时程度和商家回复质量对负面评论内容评分与体验型产品销量关系存在显著调节作用,其中商家即时回复、 敷衍型回复对负面评论内容评分与体验型产品销量关系的调节作用比延迟回复、 针对型回复更为显著.
Impact of Online Negative Reviews on Experiential Product Sales—— Based on Merchant Replies [J].
本文从负面评论者专业度、 负面评论内容评分、 产品价格及负面评论星级评分四个方面分析在线负面评论对体验型产品销量的影响,并重点分析商家回复对负面评论内容评分与体验型产品销量关系的调节作用.研究表明:负面评论者专业度、 负面评论内容评分对体验型产品销量具有显著影响,且星级评论者对体验型产品销量的影响力大于一般评论者;产品价格、 负面评论星级评分对体验型产品销量没有显著影响;商家回复及时程度和商家回复质量对负面评论内容评分与体验型产品销量关系存在显著调节作用,其中商家即时回复、 敷衍型回复对负面评论内容评分与体验型产品销量关系的调节作用比延迟回复、 针对型回复更为显著.
|
| [5] |
在线评论的感知有用性影响因素——基于在线影评的实证研究 [J].
作为电子口碑(EWOM)的一种表现形式,在线评论已经成为消费者的 重要信息来源之一。最近,在线评论吸引了大批研究者的注意,但是少有研究关注用户对在线评论的感知过程。本研究力图回答:什么因素影响用户对体验型商品在 线评论的感知有用性的评价?本研究在先前文献的基础上,建立了一个在线评论感知有用性影响因素模型,并基于豆瓣网收集的37397条实际用户评论进行验 证。结果显示:拥有较为极端的情感倾向和较长的正文的评论会正面影响在线评论的感知有用性;但是,评论的效价、评论标题长度和评论的可读性对评论的感知有 用性没有显著影响。
Factors Affecting the Perceived Usefulness of Online Reviews——An Empirical Study Based on Online Film Reviews [J].
作为电子口碑(EWOM)的一种表现形式,在线评论已经成为消费者的 重要信息来源之一。最近,在线评论吸引了大批研究者的注意,但是少有研究关注用户对在线评论的感知过程。本研究力图回答:什么因素影响用户对体验型商品在 线评论的感知有用性的评价?本研究在先前文献的基础上,建立了一个在线评论感知有用性影响因素模型,并基于豆瓣网收集的37397条实际用户评论进行验 证。结果显示:拥有较为极端的情感倾向和较长的正文的评论会正面影响在线评论的感知有用性;但是,评论的效价、评论标题长度和评论的可读性对评论的感知有 用性没有显著影响。
|
| [6] |
在线评论对酒店订满率的影响研究 [J].https://doi.org/10.3969/j.issn.1002-5006.2016.04.017 URL [本文引用: 1] 摘要
随着Web 2.0的广泛应用,在线评论对酒店销售产生了重大影响。由于无法获取确切的在线销售数据,已有的研究用在线评论量来替代,但其并不能有效地衡量酒店的在线销售量。因此,文章引入订满率,从Trip Advisor.com上采集酒店数据,研究消费者推荐比率和酒店位置评分等在线评论因素对不同档次酒店订满率的影响。结果表明:(1)订满率比在线评论量更能反映酒店的销售情况;(2)消费者推荐比率对豪华型酒店的订满率有正面影响,但对经济型酒店无显著影响;(3)消费者对酒店位置的评分对所有酒店的订满率都有显著的正面影响。
Influence of Online Reviews on Hotels’ Full-occupancy Rates [J].https://doi.org/10.3969/j.issn.1002-5006.2016.04.017 URL [本文引用: 1] 摘要
随着Web 2.0的广泛应用,在线评论对酒店销售产生了重大影响。由于无法获取确切的在线销售数据,已有的研究用在线评论量来替代,但其并不能有效地衡量酒店的在线销售量。因此,文章引入订满率,从Trip Advisor.com上采集酒店数据,研究消费者推荐比率和酒店位置评分等在线评论因素对不同档次酒店订满率的影响。结果表明:(1)订满率比在线评论量更能反映酒店的销售情况;(2)消费者推荐比率对豪华型酒店的订满率有正面影响,但对经济型酒店无显著影响;(3)消费者对酒店位置的评分对所有酒店的订满率都有显著的正面影响。
|
| [7] |
In Search of Patterns Among Travellers’ Hotel Ratings in TripAdvisor [J].https://doi.org/10.1016/j.tourman.2015.09.020 URL [本文引用: 1] 摘要
ABSTRACT This paper sheds light on ways travellers' rating patterns in the hotel review website TripAdvisor differ between independent and chain hotels. To delve deeper, travellers were classified according to their profiles, namely, business, couple, family, friend and solo. Besides, hotels straddled across four geographical regions, namely, America, Asia Pacific, Europe as well as Middle East and Africa. A 5 (profiles) 4 (regions) two-way factorial analysis of variance was conducted separately for independent and chain hotels. A qualitative analysis was further conducted to tease out the findings from the quantitative analyses. Travellers' rating patterns were found to differ substantially between independent and chain hotels across both profiles as well as regions. The paper concludes by highlighting its implications, limitations and potential directions for future research.
|
| [8] |
A Dynamic Model of the Effect of Online Communications on Firm Sales [J].https://doi.org/10.2307/23012020 URL [本文引用: 1] 摘要
Interpersonal communications have long been recognized as an influential source of information for consumers. Internet-based media have facilitated information exchange among firms and consumers, as well as observability and measurement of such exchanges. However, much of the research addressing online communication focuses on ratings collected from online forums. In this paper, we look beyond ratings to a more comprehensive view of online communications. We consider the sales effect of the volume of positive, negative, and neutral online communications captured by Web crawler technology and classified by automated sentiment analysis. Our modeling approach captures two key features of our data, dynamics and endogeneity. In terms of dynamics, we model daily measures of online communications about a firm and its products as contributing to a latent demand-generating stock variable. To account for the endogeneity, we extend the latent instrumental variable technique to account for dynamic endogenous regressors. Our results demonstrate a significant effect of positive, negative, and neutral online communications on daily sales performance. Failure to account for endogeneity results in a severe attenuation of the estimated effects. From a managerial perspective, we demonstrate the importance of accounting for communication valence as well as the impact of shocks to positive, negative, and neutral online communications.
|
| [9] |
Examining the Impact of Search Engine Ranking and Personalization on Consumer Behavior: Combining Bayesian Modeling with Randomized Field Experiments [OL]. . |
| [10] |
Effects of Opportunity to Communicate and Visibility of Individual Decisions on Behavior in the Common Interest [J].https://doi.org/10.1037/h0037450 URL [本文引用: 1] 摘要
ABSTRACT Conducted 2 experiments on the effects of opportunity to communicate and visibility of individual decisions on socially responsible behavior in group situations involving the "commons" problem. 280 undergraduates in a business administration course were assigned roles as firm representatives and assembled in groups of 5 to bid on contracts under various conditions. Opportunity to communicate resulted in more socially responsible bidding, but visibility of individual decisions had no effect. Opportunity to communicate also helped to sustain socially responsible bidding in the face of a persistently defecting group member. (PsycINFO Database Record (c) 2012 APA, all rights reserved)
|
| [11] |
Unsupervised Lexicon Induction for Clause-level Detection of Evaluations [J].https://doi.org/10.1017/S1351324911000131 URL [本文引用: 1] 摘要
Abstract This article proposes clause-level evaluation detection, which is a fine-grained type of opinion mining, and describes an unsupervised lexicon building method for capturing domain-specific knowledge by leveraging the similar polarities of sentiments between adjacent clauses. The lexical entries to be acquired are called polar atoms, the minimum human-understandable syntactic structures that specify the polarity of clauses. As a hint to obtain candidate polar atoms, we use context coherency, the tendency for the same polarity to appear successively in a context. Using the overall density and precision of coherency in the corpus, the statistical estimation picks up appropriate polar atoms from among the candidates, without any manual tuning of the threshold values. The experimental results show that the precision of polarity assignment with the automatically acquired lexicon was 83 per cent on average, and our method is robust for corpora in diverse domains and for the size of the initial lexicon.
|
| [12] |
Free Competition and the Optimal Amount of Fraud [J]. |
| [13] |
Low-Quality Product Review Detection in Opinion Summarization [C]// |
| [14] |
Feature-based Opinion Mining and Ranking [J].https://doi.org/10.1016/j.jcss.2011.10.007 URL [本文引用: 1] 摘要
The proliferation of blogs and social networks presents a new set of challenges and opportunities in the way information is searched and retrieved. Even though facts still play a very important role when information is sought on a topic, opinions have become increasingly important as well. Opinions expressed in blogs and social networks are playing an important role influencing everything from the products people buy to the presidential candidate they support. Thus, there is a need for a new type of search engine which will not only retrieve facts, but will also enable the retrieval of opinions. Such a search engine can be used in a number of diverse applications like product reviews to aggregating opinions on a political candidate or issue. Enterprises can also use such an engine to determine how users perceive their products and how they stand with respect to competition. This paper presents an algorithm which not only analyzes the overall sentiment of a document/review, but also identifies the semantic orientation of specific components of the review that lead to a particular sentiment. The algorithm is integrated in an opinion search engine which presents results to a query along with their overall tone and a summary of sentiments of the most important features.
|
| [15] |
Sentiment Analysis in Multiple Languages: Feature Selection for Opinion Classification in Web Forums [J].https://doi.org/10.1145/1361684.1361685 URL [本文引用: 1] 摘要
Abstract The Internet is frequently used as a medium for exchange of information and opinions, as well as propaganda dissemination. In this study the use of sentiment analysis methodologies is proposed for classification of web forum opinions in multiple languages. The utility of stylistic and syntactic features is evaluated for sentiment classification of English and Arabic content. Specific feature extraction components are integrated to account for the linguistic characteristics of Arabic. The Entropy Weighted Genetic Algorithm (EWGA) is also developed, which is a hybridized genetic algorithm that incorporates the information gain heuristic for feature selection. EWGA is designed to improve performance and get a better assessment of the key features. The proposed features and techniques are evaluated on a benchmark movie review data set and U.S. and Middle Eastern web forum postings. The experimental results using EWGA with SVM indicate high performance levels, with accuracy over 95% on the benchmark data set and over 93% for both the U.S. and Middle Eastern forums. Stylistic features significantly enhanced performance across all test beds while EWGA also outperformed other feature selection methods, indicating the utility of these features and techniques for document level classification of sentiments.
|
| [16] |
Improving the Quality of Predictions Using Textual Information in Online User Reviews [J].https://doi.org/10.1016/j.is.2012.03.001 URL 摘要
ABSTRACT Online reviews are often accessed by users deciding to buy a product, see a movie, or go to a restaurant. However, most reviews are written in a free-text format, usually with very scant structured metadata information and are therefore difficult for computers to understand, analyze, and aggregate. Users then face the daunting task of accessing and reading a large quantity of reviews to discover potentially useful information. We identified topical and sentiment information from free-form text reviews, and use this knowledge to improve user experience in accessing reviews. Specifically, we focus on improving recommendation accuracy in a restaurant review scenario. We propose methods to derive a text-based rating from the body of the reviews. We then group similar users together using soft clustering techniques based on the topics and sentiments that appear in the reviews. Our results show that using textual information results in better review score predictions than those derived from the coarse numerical star ratings given by the users. In addition, we use our techniques to make fine-grained predictions of user sentiments towards the individual topics covered in reviews with good accuracy.
|
| [17] |
Deriving the Pricing Power of Product Features by Mining Consumer Reviews [J].https://doi.org/10.1287/mnsc.1110.1370 URL 摘要
The increasing pervasiveness of the Internet has dramatically changed the way that consumers shop for goods. Consumer-generated product reviews have become a valuable source of information for customers, who read the reviews and decide whether to buy the product based on the information provided. In this paper, we use techniques that decompose the reviews into segments that evaluate the individual characteristics of a product (e.g., image quality and battery life for a digital camera). Then, as a major contribution of this paper, we adapt methods from the econometrics literature, specifically the hedonic regression concept, to estimate: (a) the weight that customers place on each individual product feature, (b) the implicit evaluation score that customers assign to each feature, and (c) how these evaluations affect the revenue for a given product. Towards this goal, we develop a novel hybrid technique combining text mining and econometrics that models consumer product reviews as elements in a tensor product of feature and evaluation spaces. We then impute the quantitative impact of consumer reviews on product demand as a linear functional from this tensor product space. We demonstrate how to use a low-dimension approximation of this functional to significantly reduce the number of model parameters, while still providing good experimental results. We evaluate our technique using a data set from Amazon.com consisting of sales data and the related consumer reviews posted over a 15-month period for 242 products. Our experimental evaluation shows that we can extract actionable business intelligence from the data and better understand the customer preferences and actions. We also show that the textual portion of the reviews can improve product sales prediction compared to a baseline technique that simply relies on numeric data.
|
| [18] |
Essays in Business Analytics [D].
|
| [19] |
Mining and Summarizing Customer Reviews [C]// |
| [20] |
特征观点对购买意愿的影响: 在线评论的情感分析方法 [J].
网络口碑是影响消费者购买行为的因素之一,在线评论中的各种评价信息会改变用户对产品质量的感知,进而影响购买意愿.不同产品特征对用户购买意愿的影响程度各不相同.为此,结合情感分析技术,构建计量经济模型,分析产品特征评价与用户购买意愿的关系,能够识别产品特征的重要程度.首先对产品特征进行抽取和降维,提取“特征一观点对”.然后依据信息增益的思想,计算特征的信息增益.利用情感分析技术识别情感极性及其强度,结合产品特征的信息增益,建立产品特征评价对用户购买意愿的计量经济模型,得到产品特征重要度的量化方法.对亚马逊网站上386款数码相机进行持续39个月的跟踪,实证结果表明,对数码相机产品特征的重要度识别高于TF-IDF算法以及HAC算法.研究结果建立起产品特征与用户购买意愿的联系,为网络口碑营销提供了理论依据.
The Influence of Aspect-based Opinions on User’s Purchase Intention Using Sentiment Analysis of Online Reviews [J].
网络口碑是影响消费者购买行为的因素之一,在线评论中的各种评价信息会改变用户对产品质量的感知,进而影响购买意愿.不同产品特征对用户购买意愿的影响程度各不相同.为此,结合情感分析技术,构建计量经济模型,分析产品特征评价与用户购买意愿的关系,能够识别产品特征的重要程度.首先对产品特征进行抽取和降维,提取“特征一观点对”.然后依据信息增益的思想,计算特征的信息增益.利用情感分析技术识别情感极性及其强度,结合产品特征的信息增益,建立产品特征评价对用户购买意愿的计量经济模型,得到产品特征重要度的量化方法.对亚马逊网站上386款数码相机进行持续39个月的跟踪,实证结果表明,对数码相机产品特征的重要度识别高于TF-IDF算法以及HAC算法.研究结果建立起产品特征与用户购买意愿的联系,为网络口碑营销提供了理论依据.
|
| [21] |
Sentiment Analysis: What is the End User’s Requirement? [C]// |
| [22] |
Star Quality: Aggregating Reviews to Rank Products and Merchants [C]//
|
| [23] |
Election Forecasts With Twitter: How 140 Characters Reflect the Political Landscape [J].https://doi.org/10.1177/0894439310386557 URL 摘要
This study investigates whether microblogging messages on Twitter validly mirror the political landscape offline and can be used to predict election results. In
|
| [24] |
Predicting the Future with Social Media [C]//
|
| [25] |
Osteoclast Differentiation Factor RANKL Controls Development of Progestin-driven Mammary Cancer [J].https://doi.org/10.1038/nature09387 URL PMID: 3084017 摘要
Breast cancer is one of the most common cancers in humans and will on average affect up to one in eight women in their lifetime in the United States and Europe. The Women's Health Initiative and the Million Women Study have shown that hormone replacement therapy is associated with an increased risk of incident and fatal breast cancer. In particular, synthetic progesterone derivatives (progestins) such as medroxyprogesterone acetate (MPA), used in millions of women for hormone replacement therapy and contraceptives, markedly increase the risk of developing breast cancer. Here we show that the in vivo administration of MPA triggers massive induction of the key osteoclast differentiation factor RANKL (receptor activator of NF- B ligand) in mammary-gland epithelial cells. Genetic inactivation of the RANKL receptor RANK in mammary-gland epithelial cells prevents MPA-induced epithelial proliferation, impairs expansion of the CD49fstem-cell-enriched population, and sensitizes these cells to DNA-damage-induced cell death. Deletion of RANK from the mammary epithelium results in a markedly decreased incidence and delayed onset of MPA-driven mammary cancer. These data show that the RANKL/RANK system controls the incidence and onset of progestin-driven breast cancer.
|
| [26] |
|
| [27] |
McDonald R, et al. Building a Sentiment Summarizer for Local Service Reviews [C]// |
| [28] |
When is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks [J].https://doi.org/10.1111/j.1540-6261.2010.01625.x URL [本文引用: 2] 摘要
Previous research uses negative word counts to measure the tone of a text. We show that word lists developed for other disciplines misclassify common words in f
|
| [29] |
A Holistic Lexicon-based Approach to Opinion Mining [C]// |
| [30] |
Contextual Valence Shifters[A]// Computing Attitude and Affect in Text: Theory and Applications [M]. |
| [31] |
Annotation of Negation Cues and Their Scope[R]. |
| [32] |
Distributed Representations of Words and Phrases and Their Compositionality [J].
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extensions that improve both the quality of the vectors and the training speed. By subsampling of the frequent words we obtain significant speedup and also learn more regular word representations. We also describe a simple alternative to the hierarchical softmax called negative sampling. An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of "Canada" and "Air" cannot be easily combined to obtain "Air Canada". Motivated by this example, we present a simple method for finding phrases in text, and show that learning good vector representations for millions of phrases is possible.
|
| [33] |
Exploring the Impact of Social Media on Hotel Service Performance: A Sentimental Analysis Approach [J].https://doi.org/10.1177/1938965515620483 URL [本文引用: 1] 摘要
Nuni04 N, Mi04i04 R, Popovi04 M, Azanjac R.
|
| [34] |
Interpreting Probability Models : Logit, Probit, and Other Generalized Linear Models [M]. |
| [35] |
SERVQUAL模型应用研究——以武汉某大酒店为例 [J].
SERVQUAL模型及其量表是目前比较成熟且受到业界认可的服务质量调查工具。根据武汉某大酒店的实际情况结合SERVQUAL量表,设计了调查问卷,定量测评客人对葛洲坝大酒店的服务质量期望和服务质量感知之间的差距,用鱼刺图法找出了酒店服务质量无形和有形两方面的问题。
The Application of SERVQUAL Model——A Case Study of a Hotel in Wuhan [J].
SERVQUAL模型及其量表是目前比较成熟且受到业界认可的服务质量调查工具。根据武汉某大酒店的实际情况结合SERVQUAL量表,设计了调查问卷,定量测评客人对葛洲坝大酒店的服务质量期望和服务质量感知之间的差距,用鱼刺图法找出了酒店服务质量无形和有形两方面的问题。
|
| [36] |
Analyzing Changes in Hotel Customers’ Expectations by Trip Mode [J].https://doi.org/10.1016/j.ijhm.2012.11.011 URL [本文引用: 1] 摘要
With the emergence of Web 2.0, electronic word-of-mouth (eWOM) shared through social networking sites has become the primary information source for many travelers. An enormous quantity of reviews has been posted by customers, and has become a valuable means by which hoteliers can better understand customer satisfaction and expectations. Efforts have been made to analyze these parameters in term...
|
| [37] |
基于内容分析法的我国经济型酒店服务质量评价研究——兼与高星级酒店相对比 [J].https://doi.org/10.3969/j.issn.1003-6539.2010.11.009 URL [本文引用: 1] 摘要
酒店的服务质量研究意义重大,国内外的研究成果在此已形成了一定的体系,但研究对象基本未涉及经济型酒店,且资料收集方法单一.本文在合理确定经济型酒店服务质量评价体系的基础上,通过网络内容分析法把大量网友客观真实的评价加以量化分析,结论如下:顾客对经济型酒店的综合服务质量满意度处于中等偏上水平,对客房、噪音、网络等因素的关注度高;客房的质量和隔音效果、网络预订和餐饮服务等有待提高;餐饮服务、网络等因素与酒店服务质量总评密切相关;东部城市经济型酒店综合服务质量优于中西部,但各地区酒店选址在顾客感知中差异不明显;商务旅行者更重视便利性而休闲旅行者更加重视舒适度;经济型酒店服务质量评价明显优于高星级酒店.对此,笔者有针对性地提出了相关建议,并对本文存在的局限性和后续可以深入的研究进行了讨论.
A Evaluation on Service Quality of Economic Hotel in China: A Content Analysis of Guest Comments on Website [J].https://doi.org/10.3969/j.issn.1003-6539.2010.11.009 URL [本文引用: 1] 摘要
酒店的服务质量研究意义重大,国内外的研究成果在此已形成了一定的体系,但研究对象基本未涉及经济型酒店,且资料收集方法单一.本文在合理确定经济型酒店服务质量评价体系的基础上,通过网络内容分析法把大量网友客观真实的评价加以量化分析,结论如下:顾客对经济型酒店的综合服务质量满意度处于中等偏上水平,对客房、噪音、网络等因素的关注度高;客房的质量和隔音效果、网络预订和餐饮服务等有待提高;餐饮服务、网络等因素与酒店服务质量总评密切相关;东部城市经济型酒店综合服务质量优于中西部,但各地区酒店选址在顾客感知中差异不明显;商务旅行者更重视便利性而休闲旅行者更加重视舒适度;经济型酒店服务质量评价明显优于高星级酒店.对此,笔者有针对性地提出了相关建议,并对本文存在的局限性和后续可以深入的研究进行了讨论.
|
| [38] |
Promoting Service Quality in Tourist Hotels: The Role of HRM Practices and Service Behavior [J].https://doi.org/10.1016/S0261-5177(03)00117-1 URL 摘要
Tourist hotels in Taiwan are focusing their attention on improving customer service quality. In general, a firm's human resource management (HRM) practices can create an environment that encourages positive employee behaviour, thereby enhancing service quality. This conceptualization is grounded in an extensive review of the literature, pooling together previously disparate research strands. Th...
|
| [39] |
Performance Comparisons of Hotels in China [J].https://doi.org/10.1016/j.ijhm.2004.04.004 URL [本文引用: 1] 摘要
Abstract China's hotel industry has only really existed since 1978. In that time, it has grown in size and complexity of ownership. Quality has been improved by the introduction of foreign management techniques and quality standards, for example the star-rating system of hotel classification. This paper compares performance of hotels using various hotel groupings according to ownership, size and star rating.The comparisons indicate that better performance occurs in hotels that have foreign ownership connections (especially those linked to Hong Kong, Macau and Taiwan partners), those that are bigger and those which have a higher star rating.According to the World Tourism Organization, China is forecast to become the world's number one tourist destination by 2020. This paper also identifies the major issues facing the Chinese hotel industry and the government as they face this astounding prediction.
|

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}