1 引言
随着信息通信技术的飞速发展,越来越多的人使用互联网发布和获取信息。新技术在为人们的生活带来便利的同时,也带来了很多新问题。由于互联网公司提供的产品和服务种类多样,服务能力参差不齐,客户在使用过程中经常会遇到各种问题,随之而来的客户投诉也不断增加。
客户的投诉信息往往会暴露企业运营过程中存在的问题,从客户投诉中发掘客户的潜在需求,对于企业运营决策的调整和服务的改进有着重要的导向作用[1 ] 。因此,准确快速地分类客户投诉,将非结构化数据转换为结构化形式,对于企业快速处理客户投诉、挖掘客户潜在需求至关重要。客户投诉文本具有语句短小、特征稀疏、缺乏训练数据等特点,使得其自动分类较为困难,提高其自动分类准确率是客户投诉文本分类的主要目标。客户投诉文本分类是指通过自然语言处理技术将客户投诉文本按照设置的标签进行自动分类。其方法主要分为机器学习方法和深度学习方法两类。
传统客户投诉文本分类常用的机器学习算法有:支持向量机(Support Vector Machine,SVM)、K近邻(K-Nearest Neighbor,KNN)[2 ] 、朴素贝叶斯方法[3 ] 、决策树(Decision Tree,DT)等。余本功等结合两种语言模型构建了维度相对较低的SVM原始输入空间,并引入集成学习的思想,提出基于集成SVM的投诉文本分类方法[4 ] 。传统机器学习算法在缓解数据稀疏性、处理高维数据等方面的能力较弱,难以解决客户投诉文本存在的数据短小、特征稀疏的问题。
近年来,深度学习在解决这类问题上发挥的作用越来越大。常用于客户投诉文本分类的深度学习算法有循环神经网络(Recurrent Neural Network,RNN)及其变体、卷积神经网络(Convolutional Neural Network,CNN)及其变体。这两种算法各有优劣,RNN及其变体长短时记忆网络(Long Short-Term Memory,LSTM)、双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)等是一类对序列进行建模的神经网络,其基于时间序列的循环结构能够有效学习文本的全局语序特征,但是存在梯度弥散或梯度爆炸的情况[5 ] 。CNN的变体文本卷积神经网络(Text-CNN)采用不同尺寸的卷积核提取卷积核范围内的词语之间的局部特征,但是受卷积核尺寸的限制,无法获取远距离依赖[6 ] 。单独的分类算法都有自身的局限性,将不同的深度学习网络组合以获取更好的文本分类效果是当下的研究热点。
基于深度学习的方法按照网络结构可以分为单通道和多通道两类。单通道网络一般是对文本向量进行顺序处理,特征提取过程通常表现为串行结构。刘月等使用串行结构的CNN和嵌套长短时记忆网络(Nested LSTM),融合注意力机制,提出基于注意力的CNLSTM模型,在新闻文本分类任务上取得了很好的效果[7 ] 。韩永鹏等使用双通道词嵌入丰富文本表示,将Text-CNN提取的特征分别输入对应的LSTM网络中提取语序信息[5 ] 。王艳等结合文本多种特征,丰富语义特征,使用卷积与最大池化操作进行特征提取,提高文本分类效果[8 ] 。单通道的网络结构使得模型特征提取过程并不独立,顺序处理的网络结构导致靠后的特征提取网络不能发挥最好的效果。
多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题。田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] 。黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] 。张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] 。Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] 。传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题。
作为一种资源分配方法,注意力机制是解决信息过载问题的主要手段。目前广泛应用在计算机视觉和自然语言处理领域,在一定程度上能够为深度网络提供直观的解释[12 ] 。注意力机制在自然语言处理领域最早的应用是由Bahdanau等在机器翻译问题中引入,为编码器输入的不同部分赋予不同的权重,从而解决输入特征缺乏区分度的问题[13 ] 。协同注意力机制(Co-attention)是将多个特征向量同时输入网络,联合学习各自的注意力权重,因此常被用于视觉问答任务中图像特征与文本特征之间关键信息的相互提取[14 ] 。多头注意力机制是由Vaswani等提出的注意力机制的一种的组合方式,它将输入特征映射到不同子空间进行表示,使注意力部分可以联合关注到来自不同表示子空间的信息,提高了注意力机制的学习效果[15 ] 。针对传统客户投诉文本分类模型存在的问题,本文构建了文本向量化表示和多通道特征提取网络解决客户投诉文本所呈现的数据短小、特征稀疏的问题,后构建了多头协同注意力机制对多通道输出特征进行交互,解决传统多通道投诉文本分类模型特征间关系学习不足的问题,提出了一种基于多头协同注意力机制的客户投诉文本分类模型。
2 模型构建
2.1 模型框架
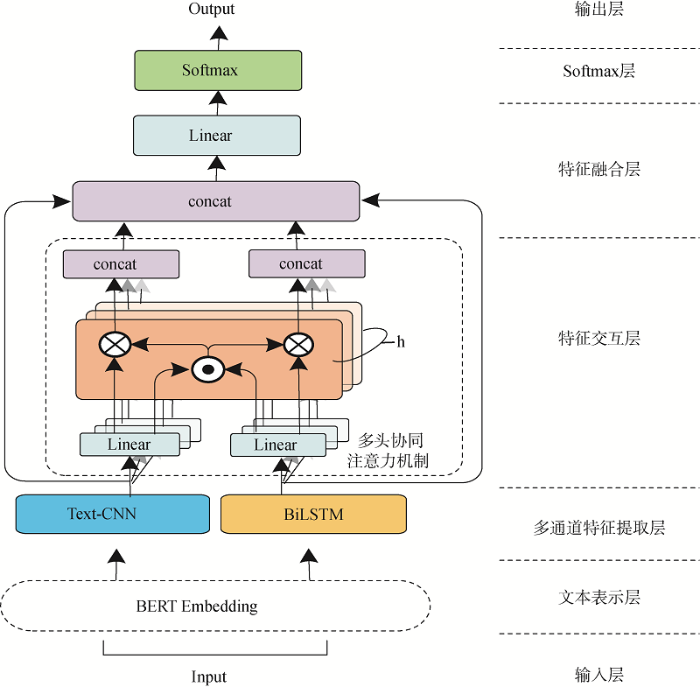
本文提出的基于多头协同注意力机制的客户投诉文本分类模型主要包含文本表示层、多通道特征提取层、特征交互层、特征融合层、Softmax层与输出层,其具体结构如图1 所示。模型使用BERT模型获取字向量粒度的文本向量化表示。相比于传统的文本表示模型,BERT模型能够有效缓解一词多义的现象。接下来将文本向量分别输入包含局部特征提取和全局特征提取的多通道特征提取层,其中局部特征提取部分是由三个不同尺寸的卷积核组成的Text-CNN网络,用于提取卷积核范围内字向量之间的局部特征。本文将三个通道获取的不同层级的局部特征进行拼接,作为文本局部特征输出。全局特征提取部分是一个BiLSTM网络,能够很好地捕捉到较长距离的依赖关系。使用BiLSTM网络对文本序列进行前向和后向两个方向的建模,以更好地捕捉双向的语义依赖;并将两个方向的特征输出拼接作为文本全局特征输出。在特征交互层,将局部特征和全局特征共同输入一个多头协同注意力机制中,互相提取另一特征向量中的关键信息,实现特征间的交互,最后作为特征间关系信息与原特征向量拼接,实现特征融合。随后将融合后的特征输入全连接网络中进行降维,输入Softmax层中获得预测向量,实现文本分类。
图1
图1
基于多头协同注意力机制的客户投诉文本分类模型
Fig.1
Customer Complaint Text Classification Model Based on a Multi-head Co-attention Mechanism
2.2 文本向量化表示
文本表示是将文本转化为计算机可读的数字矩阵的过程,是本文方法的第一步。传统的文本向量化表示模型有Word2Vec、Doc2Vec、LDA等,但是传统模型无法很好地解决一词多义的问题。BERT模型是由谷歌发布的预训练语言模型[16 ] ,可以有效解决一词多义问题。
本文模型以字粒度对文本进行切分与向量化表示,文本无需经过预处理。输入BERT模型前,每个字都会通过字典查找获得对应的Token,文本序列由此转变为数字编号序列,BERT模型处理的最大句子长度为512,超出的部分会被舍弃,不足的部分用零填充。假设每个样本S n ,在输入BERT模型后索引得到预训练的字向量。BERT模型中的Transformer编码器用于学习训练集文本的上下文字向量关系,通过层层传递得到最终的文本向量化表示,则整个文本通过文本表示层后的输出是n 个k X ∈ R n × k x i ∈ R k
(1) X = { x 1 , x 2 , … , x n }
2.3 多通道特征提取
BERT输出的文本向量化表示获得的字向量虽然包含上下文关系,但仍然存在噪声多、维度高的问题,同时投诉文本短小且特征稀疏,需要通过特征提取网络进行特征提取和降维。本文选用并行结构的Text-CNN和BiLSTM多通道特征提取网络分别提取文本的局部与全局特征。
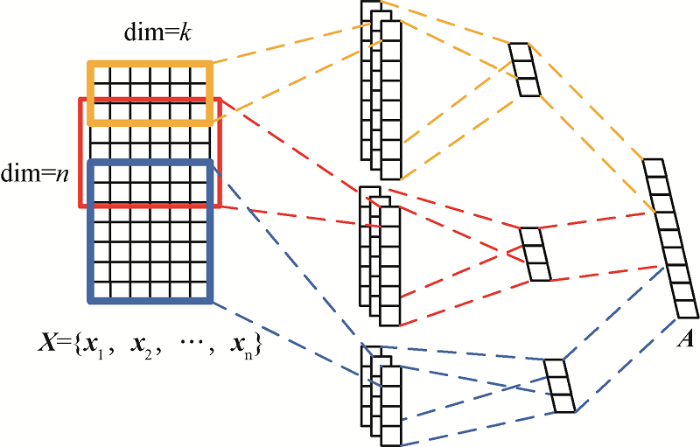
Text-CNN[17 ] 是一种具有较强文本特征提取能力的网络。本文采用三个不同尺寸卷积核的Text-CNN网络,分别提取卷积核范围内的特征信息,下接最大池化做降维,其结构如图2 所示。首先将文本表示层的输出X c j
(2) c j = f ( w ⋅ y j : j + r - 1 + b )
其中,f ( ⋅ ) b w r × k r
(3) C = { c 1 , c 2 , … , c n - h + 1 }
本文采用最大池化对每个通道输出的特征图集合进行特征提取和降维,最大池化即提取每个特征图中的最大值,如公式(4)所示。
(4) C ' = m a x { C }
本文采用三种不同尺寸的卷积核进行特征提取,每个通道的输出经过池化操作后分别得到一个尺寸为1 × r
(5) A = C 1 ' ⊕ C 2 ' ⊕ C 3 '
其中,C 1 ' C 2 ' C 3 ' A
图2
图2
文本卷积神经网络结构
Fig.2
Structure of Text-CNN
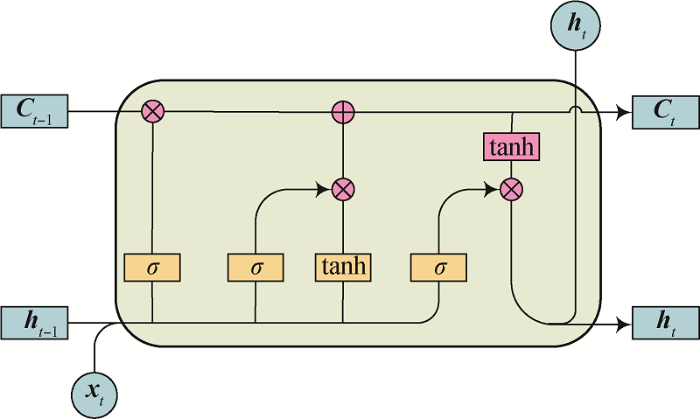
BiLSTM[18 ] 是LSTM的变体,其可对文本进行正向和反向两个方向的建模,获取前后文的依赖关系,完成文本序列的全局特征提取。LSTM的“门”结构如图3 所示。
图3
图3
LSTM的“门”结构
Fig.3
Structure of LSTM
在t h t
(6) f t = σ ( w c ⋅ [ h t - 1 , x t ] + b f )
(7) c t = f t × c t - 1 + i t × t a n h ( w c ⋅ [ h t - 1 , x t ] + b c )
(8) i t = σ ( w i ⋅ [ h t - 1 , x t ] + b c )
(9) o t = σ ( w o ⋅ [ h t - 1 , x t ] + b o )
(10) h t = o t × t a n h ( c t )
其中,x t f t t c t i t o t t w c w i w o b σ h t t
(11) B = h a ⊕ h b
其中,h a h b B ∈ R d × 2
2.4 多头协同注意力机制
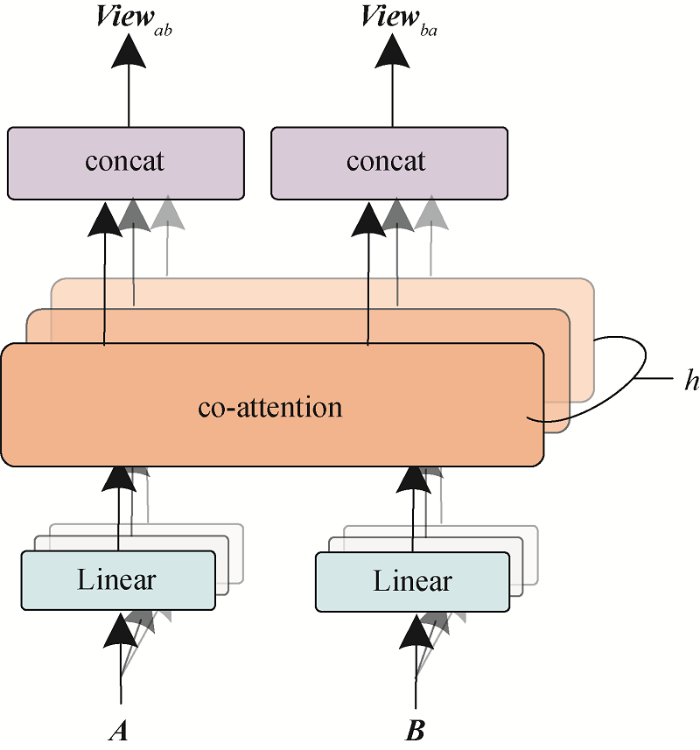
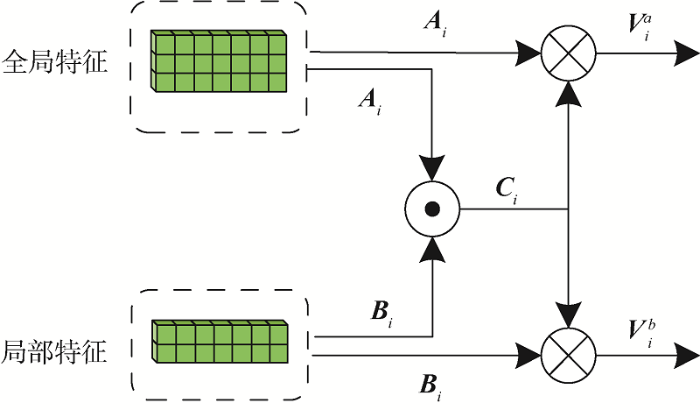
协同注意力机制[14 ] 通过计算特征向量之间的共享相似度矩阵反映特征向量间的关系,后将共享相似度矩阵作用于原特征向量实现特征间的信息交互。在协同注意力机制和多头注意力机制[16 ] 的基础上,笔者构建多头协同注意力机制,用于投诉文本局部特征与全局特征的交互。在本文模型中,多头协同注意力机制的输入是多通道特征提取网络输出的局部特征矩阵A ∈ R d × 3 B ∈ R d × 2 h 图4 所示。首先通过h
(12) A 1 , A 2 , … , A h = L i n e a r 1,2 , … , h a ( A )
(13) B 1 , B 2 , … , B h = L i n e a r 1,2 , … , h b ( B )
经过函数L i n e a r 1,2 , … , h a ( ⋅ ) A i ∈ R ( d / h ) × 3 B i ∈ R ( d / h ) × 2 i 图5 所示。在协同注意力机制内部首先计算特征向量间的共享相似度矩阵C i ∈ R 3 × 2
(14) C i = t a n h ( A i T ⋅ B i )
经过归一化处理后的相似度矩阵C i V i a V i b
(15) V i a = t a n h ( A i C i ) , V i b = t a n h ( B i C i T )
协同注意力机制的输入和输出特征维度不变,第i V i a ∈ R ( d / h ) × 2 V i b ∈ R ( d / h ) × 3 V i e w a b ∈ R d × 2 V i e w b a ∈ R d × 3
(16) V i e w a b = c o n c a t ( V 1 a , V 2 a , … , V h a )
(17) V i e w b a = c o n c a t ( V 1 b , V 2 b , … , V h b )
由于降维后输出矩阵宽度设置为d / h
图4
图4
多头协同注意力机制
Fig.4
Multi-head Co-attention Mechanism
图5
图5
协同注意力机制
Fig.5
Co-attention Mechanism
2.5 特征融合与输出
在特征融合层与输出层,本文借鉴了类似ResNet[19 ] 中的残差连接和Transformer[15 ] 中经过注意力机制后再与原特征相加的操作,将交互后的特征向量V i e w a b V i e w b a A B F ∈ R d × 10
(18) F = c o n c a t ( V i e w a b , V i e w b a , A , B )
然后添加全连接层用于非线性降维,再输入Softmax层获取分类结果矩阵。
3 实验与分析
3.1 实验环境与实验参数
实验采用Windows10操作系统,使用Jupyter Notebook作为编译工具,在PyTorch框架下搭建深度神经网络模型,在GPU上进行模型训练与测试。实验环境的设置和实验平台搭建如表1 所示。
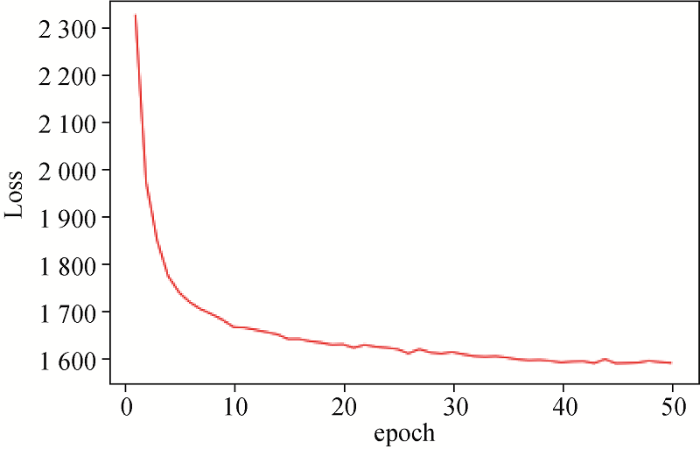
如图6 所示,主模型训练在Epoch为50时已经充分收敛,其他参数设置是在初始参数的基础上经过调优得到。具体可调参数设置如表2 所示。
图6
图6
Epoch与Loss关系图
Fig.6
Relationship Between Epoch and Loss
3.2 实验数据
本文使用两个数据集对提出的模型进行性能测试,包括THUCNews新闻文本数据集和电信客户投诉文本数据集。在THUCNews新闻文本数据集上验证模型文本分类效果,在电信客户投诉文本数据集上验证模型投诉分类效果。
THUCNews新闻文本数据集是由清华大学公开的数据集,是根据新浪新闻RSS订阅频道2005-2011年间的历史数据筛选生成,选取其中10个类别的样本分别为:财经、房产、家居、教育、科技、时尚、时政、体育、游戏、娱乐。每个类别包含5 000条训练样本,500条验证样本,1 000条测试样本。
电信客户投诉文本数据集是由某电信公司提供的2018年元旦期间安徽省部分地区已正确归类的投诉文本,包含4个类别总计8 409条样本。由于电信客户投诉文本数据集样本数量不多,为保证训练样本充足而未设置验证集,按照1∶9的比例划分测试集与训练集。数据统计结果如表3 所示。
3.3 基线方法实验与分析
为了验证模型分类效果,选取8种基线模型在两个数据集上进行对比,并选取准确率和F1 值作为评价指标。实验采用十折交叉验证计算评价指标,并区分了单通道方法与多通道方法,在训练的50次迭代中保存准确率最高的模型参数用于测试。对比方法如下:
(2)RCNN[20 ] :先使用RNN提取上下文信息,后接CNN提取局部特征。
(3)LSTM+att[21 ] :使用注意力机制对LSTM各时刻输出进行加权。
(4)BiLSTM+att[22 ] :结合多头注意力机制的双向LSTM。
(5)BiLSTM+max-pooling:在双向LSTM后接最大池化。
(6)组合-CNN[10 ] :在传统CNN模型基础上,实现6层组合-CNN模型。
(7)CNLSTM[7 ] :在CNN后接LSTM和注意力层提取特征。
(8)CFC-LSTM-multi[5 ] :融合通道特征的CNN与LSTM串联进行特征提取。
如表4 所示,BiLSTM+att、LSTM+att、NLSTM等序列建模方法取得了与BiLSTM相近的分类效果,但是由于NLSTM是多层嵌套LSTM,BiLSTM+att与LSTM+att也有较高的计算复杂度,在特征提取部分使用以上三种方法会进一步增加模型的时间复杂度与空间复杂度,可能出现梯度弥散或容易过拟合。因此选择BiLSTM作为全局特征提取方法。
表4 中结果显示,本文方法在两个数据集上都取得了最高的准确率。相比单通道方法在两个数据集上准确率最高的两个模型,准确率分别提高了0.38和0.54个百分点,F1 值分别提高了0.38和0.60个百分点。说明结合局部特征与全局特征的多通道特征提取方法相比单通道特征提取方法有明显优势。相较其他多通道方法,多头协同注意力机制发挥了明显作用,能够有效学习到局部与全局特征间关系,准确率相比多通道方法在两个数据集上准确率最高的两个模型分别提高了1.04和0.45个百分点。由于数据量不足,导致电信客户投诉数据集准确率普遍不高,但是本文方法仍取得了最高的准确率。
3.4 注意力机制对比分析
为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验。将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示。对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同。由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果。
3.5 消融实验与分析
为了进一步探究本模型各组成部分对分类效果的影响,进行了消融实验。消融实验的4个实验都使用基于字向量的BERT模型完成文本向量化表示,参数设置均与本模型相同。具体模型如下:
(1)Text-CNN:去掉原模型全局特征提取网络BiLSTM与多头协同注意力机制,仅保留局部特征提取网络。
(2)BiLSTM:去掉原模型局部特征提取网络Text-CNN与多头协同注意力机制,仅保留全局特征提取网络。
(3)Text-CNN+BiLSTM:去掉原模型中的多头协同注意力机制,使用Text-CNN与BiLSTM并联,局部特征与全局特征仅使用拼接方法进行融合。
如表6 所示,本文方法相较单独的特征提取方法BiLSTM、Text-CNN,在THUCNews数据集上准确率分别提升了3.18和4.88个百分点,在电信客户投诉数据集上准确率分别提升了0.99和0.83个百分点,证明多通道特征提取网络较单通道特征提取网络效果提升明显,全局特征与局部特征的结合实现了特征互补,能够更全面地提取投诉文本特征信息,缓解投诉文本短小且特征稀疏的问题。本文方法相比未进行特征间关系学习、仅使用拼接进行特征融合的模型Text-CNN+BiLSTM,在两个数据集上准确率分别提升2.62和0.35个百分点,说明本文方法引入的多头协同注意力机制能够实现特征间关系的学习,使得特征充分交互,进一步提高了分类效果。
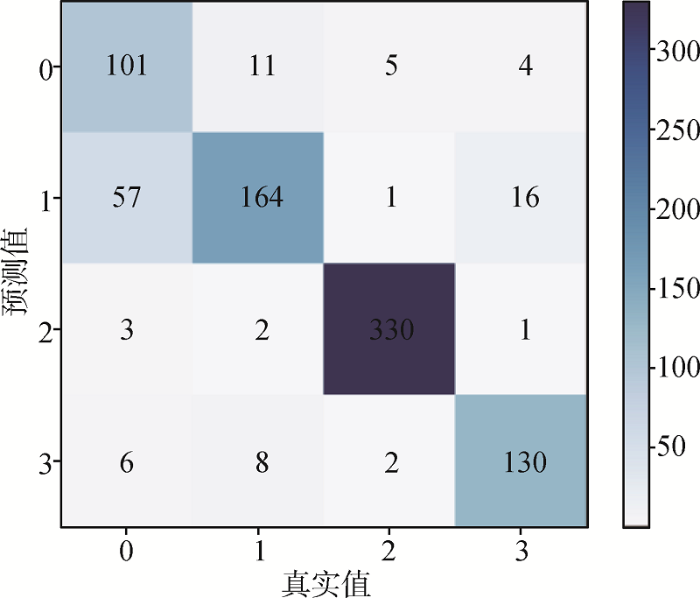
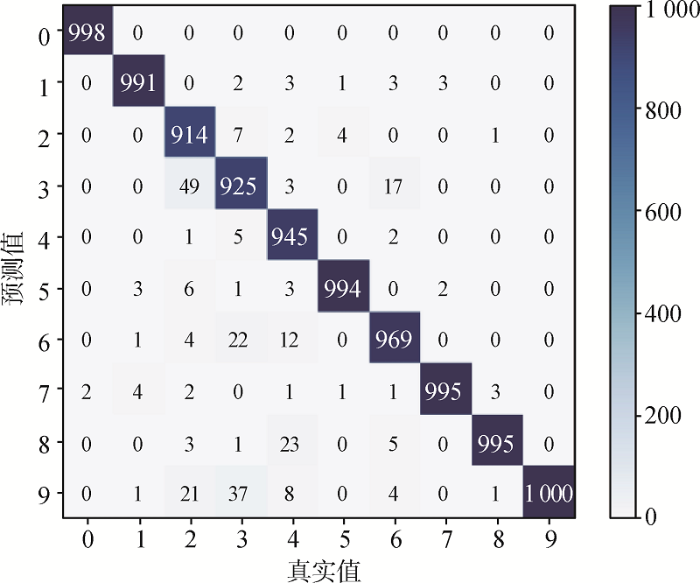
电信客户投诉数据集上模型的测试集混淆矩阵如图7 所示。本文方法在第2、3、4类的分类准确率都达到较高的水平,其中第3类分类准确率达到97.6%。第1类数据含有噪声,影响了此类投诉文本的分类准确率,导致第1类的分类准确率不高,仅有60.47%。本文模型在THUCNews数据集上表现优秀,各类准确率都达到较高的水平,如图8 所示。
图7
图7
客户投诉数据集混淆矩阵
Fig.7
Confusion Matrix of Complaint Dataset
图8
图8
THUCNews数据集混淆矩阵
Fig.8
Confusion Matrix of THUCNews Dataset
4 结语
本文提出一种基于多头协同注意力机制的客户投诉文本分类模型,使用BERT模型进行文本向量化表示,后接并行的Text-CNN和BiLSTM多通道特征提取网络完成局部特征和全局特征提取,同时引入多头协同注意力机制学习局部特征与全局特征间关系。实验表明:局部特征与全局特征相结合的多通道特征提取网络能够使特征提取更为充分,有效缓解投诉文本短小和特征稀疏的问题,同时多头协同注意力机制能够有效学习特征间关系,提取特征间关键信息,提升了客户投诉文本分类的准确率。但是本文仍有一定局限性,例如电信客户投诉数据集规模较小,由于训练不充分导致部分类别分类准确率不高。针对电信客户投诉文本分类问题,未来尝试在输入部分引入更丰富的信息,进一步克服客户投诉文本短小的缺点。在模型部分尝试使用改进的协同注意力机制实现特征间的交互,提高分类准确率。
作者贡献声明
利益冲突声明
支撑数据
支撑数据[1]为公开数据集;支撑数据[2]由作者自存储,E-mail:1845308711@qq.com。
[1] 孙茂松. THUCNews.zip. 中文新闻文本数据集. http://thuctc.thunlp.org/.
[2] 王金政. Telecom_customer_complaint_dataset.csv. 电信客户投诉数据集.
参考文献
View Option
[1]
梁昕露 , 李美娟 . 电信业投诉分类方法及其应用研究
[J]. 中国管理科学 , 2015 , 23 (S1 ): 188 -192 .
[本文引用: 1]
( Liang Xinlu Li Meijuan Text Categorization of Complain in Telecommunication Industry and Its Applied Research
[J]. Chinese Journal of Management Science , 2015 , 23 (S1 ): 188 -192 .)
[本文引用: 1]
[2]
李荣艳 , 金鑫 , 王春辉 , 等 . 一种新的中文文本分类算法
[J]. 北京师范大学学报(自然科学版) , 2006 (5 ): 501 -505 .
[本文引用: 1]
Li Rongyan Jin Xin Wang Chunhui et al. A New Algorithm of Chinese Text Classification
[J]. Journal of Beijing Normal University(Natural Science) , 2006 (5 ): 501 -505 .)
[本文引用: 1]
[3]
翟林 , 刘亚军 . 支持向量机的中文文本分类研究
[J]. 计算机与数字工程 , 2005 (3 ): 21 -23 ,45.
[本文引用: 1]
( Zhai Lin Liu Yajun. Research on Chinese Text Categorization Based on Support Vector Machine
[J]. Computer & Digital Engineering , 2005 (3 ): 21 -23 ,45.)
[本文引用: 1]
[4]
余本功 , 陈杨楠 , 杨颖 . 基于nBD-SVM模型的投诉短文本分类
[J]. 数据分析与知识发现 , 2019 , 3 (5 ): 77 -85 .
[本文引用: 1]
( Yu Bengong Chen Yangnan Yang Ying Classifying Short Text Complaints with nBD-SVM Model
[J]. Data Analysis and Knowledge Discovery , 2019 , 3 (5 ): 77 -85 .)
[本文引用: 1]
[5]
韩永鹏 , 陈彩 , 苏航 , 等 . 融合通道特征的混合神经网络文本分类模型
[J]. 中文信息学报 , 2021 , 35 (2 ): 78 -88 .
[本文引用: 9]
( Han Yongpeng Chen Cai Su Hang Liang Yi et al. Hybrid Neural Network Text Classification Model with Channel Features
[J]. Journal of Chinese Information Processing , 2021 , 35 (2 ): 78 -88 .)
[本文引用: 9]
[6]
田乔鑫 , 孔韦韦 , 滕金保 , 等 . 基于并行混合网络与注意力机制的文本情感分析模型
[J/OL]. 计算机工程 . [2022 -05 -10 ]. https://kns.cnki.net/kcms/detail/31.1289.tp.20211015.0640.010.html.
URL
[本文引用: 2]
( Tian Qiaoxin Kong Weiwei Teng Jinbao et al. Text Sentiment Analysis Model Based on Parallel Hybrid Network and Attention Mechanism
[J/OL]. Computer Engineering . [2022 -05 -10 ]. https://kns.cnki.net/kcms/detail/31.1289.tp.20211015.0640.010.html.)
URL
[本文引用: 2]
[7]
刘月 , 翟东海 , 任庆宁 . 基于注意力CNLSTM模型的新闻文本分类
[J]. 计算机工程 , 2019 , 45 (7 ): 303 -308 , 314.
[本文引用: 6]
( Liu Yue Zhai Donghai Ren Qingning News Text Classification Based on CNLSTM Model with Attention Mechanism
[J]. Computer Engineering , 2019 , 45 (7 ): 303 -308 ,314.)
[本文引用: 6]
[8]
王艳 , 王胡燕 , 余本功 . 基于多特征融合的中文文本分类研究
[J]. 数据分析与知识发现 , 2021 , 5 (10 ):1 -14 .
[本文引用: 1]
( Wang Yan Wang Huyan Yu Bengong Chinese Text Classification with Feature Fusion
[J]. Data Analysis and Knowledge Discovery , 2021 , 5 (10 ): 1 -14 .)
[本文引用: 1]
[9]
黄金杰 , 蔺江全 , 何勇军 , 等 . 局部语义与上下文关系的中文短文本分类算法
[J]. 计算机工程与应用 , 2021 , 57 (6 ): 94 -100 .
DOI:10.3778/j.issn.1002-8331.1912-0185
[本文引用: 1]
Short text is usually composed of several to dozens of words. Short length and sparse features make it difficult to improve the classification accuracy of short texts. In order to solve this problem, an algorithm of classification for Chinese short texts is proposed based on local semantic features and context relationships, called Bi-LSTM_CNN_AT. In this algorithm, CNN is utilized to extract the local semantic features of a text, while Bi-LSTM is used to extract the contextual semantic features of the text. Moreover, the attention mechanism is combined too. Thus, the Bi-LSTM_CNN_AT model is able to extract the most relevant features to the current task from short texts. The experimental results show that the Bi-LSTM_CNN_AT model achieves a classification accuracy of 81.31% in the 18 categories of NLP&CC2017 news headline classification dataset, which is 2.02% higher than the single-channel CNN model and 1.77% higher than the single-channel Bi-LSTM model respectively.
( Huang Jinjie Lin Jiangquan He Yongjun et al. Chinese Short Text Classification Algorithm Based on Local Semantics and Context
[J]. Computer Engineering and Applications , 2021 , 57 (6 ): 94 -100 .)
DOI:10.3778/j.issn.1002-8331.1912-0185
[本文引用: 1]
Short text is usually composed of several to dozens of words. Short length and sparse features make it difficult to improve the classification accuracy of short texts. In order to solve this problem, an algorithm of classification for Chinese short texts is proposed based on local semantic features and context relationships, called Bi-LSTM_CNN_AT. In this algorithm, CNN is utilized to extract the local semantic features of a text, while Bi-LSTM is used to extract the contextual semantic features of the text. Moreover, the attention mechanism is combined too. Thus, the Bi-LSTM_CNN_AT model is able to extract the most relevant features to the current task from short texts. The experimental results show that the Bi-LSTM_CNN_AT model achieves a classification accuracy of 81.31% in the 18 categories of NLP&CC2017 news headline classification dataset, which is 2.02% higher than the single-channel CNN model and 1.77% higher than the single-channel Bi-LSTM model respectively.
[10]
张昱 , 刘开峰 , 张全新 , 等 . 基于组合-卷积神经网络的中文新闻文本分类
[J]. 电子学报 , 2021 , 49 (6 ): 1059 -1067 .
DOI:10.12263/DZXB.20200134
[本文引用: 4]
At present,most of the researches on news classification are in English,and the traditional machine learning methods have a problem of incomplete extraction of local text block features in long text processing.In order to solve the problem of lack of special term set for Chinese news classification,a vocabulary suitable for Chinese text classification is made by constructing a data index method,and the text feature construction is combined with word2vec pre-trained word vector.In order to solve the problem of incomplete feature extraction,the effects of different convolution and pooling operations on the classification results are studied by improving the structure of classical convolution neural network model.In order to improve the precision of Chinese news text classification,this paper proposes and implements a combined-convolution neural network model,and designs an effective method of model regularization and optimization.The experimental results show that the precision of the combined-convolutional neural network model for Chinese news text classification reaches 93.69%,which is 6.34% and 1.19% higher than the best traditional machine learning method and classic convolutional neural network model,and it is better than the comparison model in recall and F-measure.
( Zhang Yu Liu Kaifeng Zhang quanxin et al. A Combined-Convolutional Neural Network for Chinese News Text Classification
[J]. Acta Electronica Sinica , 2021 , 49 (6 ): 1059 -1067 .)
DOI:10.12263/DZXB.20200134
[本文引用: 4]
At present,most of the researches on news classification are in English,and the traditional machine learning methods have a problem of incomplete extraction of local text block features in long text processing.In order to solve the problem of lack of special term set for Chinese news classification,a vocabulary suitable for Chinese text classification is made by constructing a data index method,and the text feature construction is combined with word2vec pre-trained word vector.In order to solve the problem of incomplete feature extraction,the effects of different convolution and pooling operations on the classification results are studied by improving the structure of classical convolution neural network model.In order to improve the precision of Chinese news text classification,this paper proposes and implements a combined-convolution neural network model,and designs an effective method of model regularization and optimization.The experimental results show that the precision of the combined-convolutional neural network model for Chinese news text classification reaches 93.69%,which is 6.34% and 1.19% higher than the best traditional machine learning method and classic convolutional neural network model,and it is better than the comparison model in recall and F-measure.
[13]
Bahdanau D Cho K Bengio Y Neural Machine Translation by Jointly Learning to Align and Translate
[C]// Proceedings of International Conference on Learning Representations . 2015 .
[本文引用: 1]
[14]
Lu J S Yang J W Batra D et al. Hierarchical Question-Image Co-Attention for Visual Question Answering
[C]// Proceedings of the 30th Conference on Neural Information Processing Systems . 2016 .
[本文引用: 2]
[15]
Vaswani A Shazeer N Parmar N et al. Attention is All You Need
[C]// Proceedings of the 31st Conference on Neural Information Processing Systems . 2017 .
[本文引用: 2]
[16]
Devlin J Chang M W Lee K et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies , Volume 1 (Long and Short Papers). 2019 :4171 -4186 .
[本文引用: 2]
[17]
Kim Y Convolutional Neural Networks for Sentence Classification
[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) . 2014 : 1746 -1751 .
[本文引用: 1]
[18]
Li W J Qi F Tang M et al. Bidirectional LSTM with Self-attention Mechanism and Multi-channel Features for Sentiment Classification
[J]. Neurocomputing , 2020 , 387 : 63 -77 .
DOI:10.1016/j.neucom.2020.01.006
URL
[本文引用: 1]
[19]
He K M Zhang X Y Ren S Q et al. Deep Residual Learning for Image Recognition
[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. IEEE , 2016 .
[本文引用: 1]
[20]
Wang R S Li Z Cao J et al. Convolutional Recurrent Neural Networks for Text Classification
[C]// Proceedings of 2019 International Joint Conference on Neural Networks . 2019 .
[本文引用: 1]
[21]
张冲 . 基于Attention-Based LSTM模型的文本分类技术的研究 [D]. 南京 : 南京大学 , 2016 .
[本文引用: 1]
(Zhang Chong, Text Classification Based on Attention-Based LSTM Model [D]. Nanjing : Nanjing University , 2016 .)
[本文引用: 1]
[22]
胡朝举 , 梁宁 . 基于深层注意力的LSTM的特定主题情感分析
[J]. 计算机应用研究 , 2019 , 36 (4 ):1075 -1079 .
[本文引用: 1]
( Hu Chaoju Liang Ning Deeper Attention-based LSTM for Aspect Sentiment Analysis
[J]. Application Research of Computers , 2019 , 36 (4 ): 1075 -1079 .)
[本文引用: 1]
电信业投诉分类方法及其应用研究
1
2015
... 客户的投诉信息往往会暴露企业运营过程中存在的问题,从客户投诉中发掘客户的潜在需求,对于企业运营决策的调整和服务的改进有着重要的导向作用[1 ] .因此,准确快速地分类客户投诉,将非结构化数据转换为结构化形式,对于企业快速处理客户投诉、挖掘客户潜在需求至关重要.客户投诉文本具有语句短小、特征稀疏、缺乏训练数据等特点,使得其自动分类较为困难,提高其自动分类准确率是客户投诉文本分类的主要目标.客户投诉文本分类是指通过自然语言处理技术将客户投诉文本按照设置的标签进行自动分类.其方法主要分为机器学习方法和深度学习方法两类. ...
电信业投诉分类方法及其应用研究
1
2015
... 客户的投诉信息往往会暴露企业运营过程中存在的问题,从客户投诉中发掘客户的潜在需求,对于企业运营决策的调整和服务的改进有着重要的导向作用[1 ] .因此,准确快速地分类客户投诉,将非结构化数据转换为结构化形式,对于企业快速处理客户投诉、挖掘客户潜在需求至关重要.客户投诉文本具有语句短小、特征稀疏、缺乏训练数据等特点,使得其自动分类较为困难,提高其自动分类准确率是客户投诉文本分类的主要目标.客户投诉文本分类是指通过自然语言处理技术将客户投诉文本按照设置的标签进行自动分类.其方法主要分为机器学习方法和深度学习方法两类. ...
一种新的中文文本分类算法
1
2006
... 传统客户投诉文本分类常用的机器学习算法有:支持向量机(Support Vector Machine,SVM)、K近邻(K-Nearest Neighbor,KNN)[2 ] 、朴素贝叶斯方法[3 ] 、决策树(Decision Tree,DT)等.余本功等结合两种语言模型构建了维度相对较低的SVM原始输入空间,并引入集成学习的思想,提出基于集成SVM的投诉文本分类方法[4 ] .传统机器学习算法在缓解数据稀疏性、处理高维数据等方面的能力较弱,难以解决客户投诉文本存在的数据短小、特征稀疏的问题. ...
一种新的中文文本分类算法
1
2006
... 传统客户投诉文本分类常用的机器学习算法有:支持向量机(Support Vector Machine,SVM)、K近邻(K-Nearest Neighbor,KNN)[2 ] 、朴素贝叶斯方法[3 ] 、决策树(Decision Tree,DT)等.余本功等结合两种语言模型构建了维度相对较低的SVM原始输入空间,并引入集成学习的思想,提出基于集成SVM的投诉文本分类方法[4 ] .传统机器学习算法在缓解数据稀疏性、处理高维数据等方面的能力较弱,难以解决客户投诉文本存在的数据短小、特征稀疏的问题. ...
支持向量机的中文文本分类研究
1
2005
... 传统客户投诉文本分类常用的机器学习算法有:支持向量机(Support Vector Machine,SVM)、K近邻(K-Nearest Neighbor,KNN)[2 ] 、朴素贝叶斯方法[3 ] 、决策树(Decision Tree,DT)等.余本功等结合两种语言模型构建了维度相对较低的SVM原始输入空间,并引入集成学习的思想,提出基于集成SVM的投诉文本分类方法[4 ] .传统机器学习算法在缓解数据稀疏性、处理高维数据等方面的能力较弱,难以解决客户投诉文本存在的数据短小、特征稀疏的问题. ...
支持向量机的中文文本分类研究
1
2005
... 传统客户投诉文本分类常用的机器学习算法有:支持向量机(Support Vector Machine,SVM)、K近邻(K-Nearest Neighbor,KNN)[2 ] 、朴素贝叶斯方法[3 ] 、决策树(Decision Tree,DT)等.余本功等结合两种语言模型构建了维度相对较低的SVM原始输入空间,并引入集成学习的思想,提出基于集成SVM的投诉文本分类方法[4 ] .传统机器学习算法在缓解数据稀疏性、处理高维数据等方面的能力较弱,难以解决客户投诉文本存在的数据短小、特征稀疏的问题. ...
基于nBD-SVM模型的投诉短文本分类
1
2019
... 传统客户投诉文本分类常用的机器学习算法有:支持向量机(Support Vector Machine,SVM)、K近邻(K-Nearest Neighbor,KNN)[2 ] 、朴素贝叶斯方法[3 ] 、决策树(Decision Tree,DT)等.余本功等结合两种语言模型构建了维度相对较低的SVM原始输入空间,并引入集成学习的思想,提出基于集成SVM的投诉文本分类方法[4 ] .传统机器学习算法在缓解数据稀疏性、处理高维数据等方面的能力较弱,难以解决客户投诉文本存在的数据短小、特征稀疏的问题. ...
基于nBD-SVM模型的投诉短文本分类
1
2019
... 传统客户投诉文本分类常用的机器学习算法有:支持向量机(Support Vector Machine,SVM)、K近邻(K-Nearest Neighbor,KNN)[2 ] 、朴素贝叶斯方法[3 ] 、决策树(Decision Tree,DT)等.余本功等结合两种语言模型构建了维度相对较低的SVM原始输入空间,并引入集成学习的思想,提出基于集成SVM的投诉文本分类方法[4 ] .传统机器学习算法在缓解数据稀疏性、处理高维数据等方面的能力较弱,难以解决客户投诉文本存在的数据短小、特征稀疏的问题. ...
融合通道特征的混合神经网络文本分类模型
9
2021
... 近年来,深度学习在解决这类问题上发挥的作用越来越大.常用于客户投诉文本分类的深度学习算法有循环神经网络(Recurrent Neural Network,RNN)及其变体、卷积神经网络(Convolutional Neural Network,CNN)及其变体.这两种算法各有优劣,RNN及其变体长短时记忆网络(Long Short-Term Memory,LSTM)、双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)等是一类对序列进行建模的神经网络,其基于时间序列的循环结构能够有效学习文本的全局语序特征,但是存在梯度弥散或梯度爆炸的情况[5 ] .CNN的变体文本卷积神经网络(Text-CNN)采用不同尺寸的卷积核提取卷积核范围内的词语之间的局部特征,但是受卷积核尺寸的限制,无法获取远距离依赖[6 ] .单独的分类算法都有自身的局限性,将不同的深度学习网络组合以获取更好的文本分类效果是当下的研究热点. ...
... 基于深度学习的方法按照网络结构可以分为单通道和多通道两类.单通道网络一般是对文本向量进行顺序处理,特征提取过程通常表现为串行结构.刘月等使用串行结构的CNN和嵌套长短时记忆网络(Nested LSTM),融合注意力机制,提出基于注意力的CNLSTM模型,在新闻文本分类任务上取得了很好的效果[7 ] .韩永鹏等使用双通道词嵌入丰富文本表示,将Text-CNN提取的特征分别输入对应的LSTM网络中提取语序信息[5 ] .王艳等结合文本多种特征,丰富语义特征,使用卷积与最大池化操作进行特征提取,提高文本分类效果[8 ] .单通道的网络结构使得模型特征提取过程并不独立,顺序处理的网络结构导致靠后的特征提取网络不能发挥最好的效果. ...
... (8)CFC-LSTM-multi[5 ] :融合通道特征的CNN与LSTM串联进行特征提取. ...
... Experimental Results of Comparison Methods
Table 4 模型 类别 THUCNews 电信客户投诉数据集 准确率/% F1 /% 准确率/% F1 /% NLSTM 单通道 93.39[7 ] 93.39[7 ] 82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20
3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
融合通道特征的混合神经网络文本分类模型
9
2021
... 近年来,深度学习在解决这类问题上发挥的作用越来越大.常用于客户投诉文本分类的深度学习算法有循环神经网络(Recurrent Neural Network,RNN)及其变体、卷积神经网络(Convolutional Neural Network,CNN)及其变体.这两种算法各有优劣,RNN及其变体长短时记忆网络(Long Short-Term Memory,LSTM)、双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)等是一类对序列进行建模的神经网络,其基于时间序列的循环结构能够有效学习文本的全局语序特征,但是存在梯度弥散或梯度爆炸的情况[5 ] .CNN的变体文本卷积神经网络(Text-CNN)采用不同尺寸的卷积核提取卷积核范围内的词语之间的局部特征,但是受卷积核尺寸的限制,无法获取远距离依赖[6 ] .单独的分类算法都有自身的局限性,将不同的深度学习网络组合以获取更好的文本分类效果是当下的研究热点. ...
... 基于深度学习的方法按照网络结构可以分为单通道和多通道两类.单通道网络一般是对文本向量进行顺序处理,特征提取过程通常表现为串行结构.刘月等使用串行结构的CNN和嵌套长短时记忆网络(Nested LSTM),融合注意力机制,提出基于注意力的CNLSTM模型,在新闻文本分类任务上取得了很好的效果[7 ] .韩永鹏等使用双通道词嵌入丰富文本表示,将Text-CNN提取的特征分别输入对应的LSTM网络中提取语序信息[5 ] .王艳等结合文本多种特征,丰富语义特征,使用卷积与最大池化操作进行特征提取,提高文本分类效果[8 ] .单通道的网络结构使得模型特征提取过程并不独立,顺序处理的网络结构导致靠后的特征提取网络不能发挥最好的效果. ...
... (8)CFC-LSTM-multi[5 ] :融合通道特征的CNN与LSTM串联进行特征提取. ...
... Experimental Results of Comparison Methods
Table 4 模型 类别 THUCNews 电信客户投诉数据集 准确率/% F1 /% 准确率/% F1 /% NLSTM 单通道 93.39[7 ] 93.39[7 ] 82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20
3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
5 ]
85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
基于并行混合网络与注意力机制的文本情感分析模型
2
2022
... 近年来,深度学习在解决这类问题上发挥的作用越来越大.常用于客户投诉文本分类的深度学习算法有循环神经网络(Recurrent Neural Network,RNN)及其变体、卷积神经网络(Convolutional Neural Network,CNN)及其变体.这两种算法各有优劣,RNN及其变体长短时记忆网络(Long Short-Term Memory,LSTM)、双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)等是一类对序列进行建模的神经网络,其基于时间序列的循环结构能够有效学习文本的全局语序特征,但是存在梯度弥散或梯度爆炸的情况[5 ] .CNN的变体文本卷积神经网络(Text-CNN)采用不同尺寸的卷积核提取卷积核范围内的词语之间的局部特征,但是受卷积核尺寸的限制,无法获取远距离依赖[6 ] .单独的分类算法都有自身的局限性,将不同的深度学习网络组合以获取更好的文本分类效果是当下的研究热点. ...
... 多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题.田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] .黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] .张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] .Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] .传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题. ...
基于并行混合网络与注意力机制的文本情感分析模型
2
2022
... 近年来,深度学习在解决这类问题上发挥的作用越来越大.常用于客户投诉文本分类的深度学习算法有循环神经网络(Recurrent Neural Network,RNN)及其变体、卷积神经网络(Convolutional Neural Network,CNN)及其变体.这两种算法各有优劣,RNN及其变体长短时记忆网络(Long Short-Term Memory,LSTM)、双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)等是一类对序列进行建模的神经网络,其基于时间序列的循环结构能够有效学习文本的全局语序特征,但是存在梯度弥散或梯度爆炸的情况[5 ] .CNN的变体文本卷积神经网络(Text-CNN)采用不同尺寸的卷积核提取卷积核范围内的词语之间的局部特征,但是受卷积核尺寸的限制,无法获取远距离依赖[6 ] .单独的分类算法都有自身的局限性,将不同的深度学习网络组合以获取更好的文本分类效果是当下的研究热点. ...
... 多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题.田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] .黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] .张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] .Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] .传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题. ...
基于注意力CNLSTM模型的新闻文本分类
6
2019
... 基于深度学习的方法按照网络结构可以分为单通道和多通道两类.单通道网络一般是对文本向量进行顺序处理,特征提取过程通常表现为串行结构.刘月等使用串行结构的CNN和嵌套长短时记忆网络(Nested LSTM),融合注意力机制,提出基于注意力的CNLSTM模型,在新闻文本分类任务上取得了很好的效果[7 ] .韩永鹏等使用双通道词嵌入丰富文本表示,将Text-CNN提取的特征分别输入对应的LSTM网络中提取语序信息[5 ] .王艳等结合文本多种特征,丰富语义特征,使用卷积与最大池化操作进行特征提取,提高文本分类效果[8 ] .单通道的网络结构使得模型特征提取过程并不独立,顺序处理的网络结构导致靠后的特征提取网络不能发挥最好的效果. ...
... (7)CNLSTM[7 ] :在CNN后接LSTM和注意力层提取特征. ...
... Experimental Results of Comparison Methods
Table 4 模型 类别 THUCNews 电信客户投诉数据集 准确率/% F1 /% 准确率/% F1 /% NLSTM 单通道 93.39[7 ] 93.39[7 ] 82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20
3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
7 ]
82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
7 ]
96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
7 ]
85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
基于注意力CNLSTM模型的新闻文本分类
6
2019
... 基于深度学习的方法按照网络结构可以分为单通道和多通道两类.单通道网络一般是对文本向量进行顺序处理,特征提取过程通常表现为串行结构.刘月等使用串行结构的CNN和嵌套长短时记忆网络(Nested LSTM),融合注意力机制,提出基于注意力的CNLSTM模型,在新闻文本分类任务上取得了很好的效果[7 ] .韩永鹏等使用双通道词嵌入丰富文本表示,将Text-CNN提取的特征分别输入对应的LSTM网络中提取语序信息[5 ] .王艳等结合文本多种特征,丰富语义特征,使用卷积与最大池化操作进行特征提取,提高文本分类效果[8 ] .单通道的网络结构使得模型特征提取过程并不独立,顺序处理的网络结构导致靠后的特征提取网络不能发挥最好的效果. ...
... (7)CNLSTM[7 ] :在CNN后接LSTM和注意力层提取特征. ...
... Experimental Results of Comparison Methods
Table 4 模型 类别 THUCNews 电信客户投诉数据集 准确率/% F1 /% 准确率/% F1 /% NLSTM 单通道 93.39[7 ] 93.39[7 ] 82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20
3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
7 ]
82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
7 ]
96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
7 ]
85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
基于多特征融合的中文文本分类研究
1
2021
... 基于深度学习的方法按照网络结构可以分为单通道和多通道两类.单通道网络一般是对文本向量进行顺序处理,特征提取过程通常表现为串行结构.刘月等使用串行结构的CNN和嵌套长短时记忆网络(Nested LSTM),融合注意力机制,提出基于注意力的CNLSTM模型,在新闻文本分类任务上取得了很好的效果[7 ] .韩永鹏等使用双通道词嵌入丰富文本表示,将Text-CNN提取的特征分别输入对应的LSTM网络中提取语序信息[5 ] .王艳等结合文本多种特征,丰富语义特征,使用卷积与最大池化操作进行特征提取,提高文本分类效果[8 ] .单通道的网络结构使得模型特征提取过程并不独立,顺序处理的网络结构导致靠后的特征提取网络不能发挥最好的效果. ...
基于多特征融合的中文文本分类研究
1
2021
... 基于深度学习的方法按照网络结构可以分为单通道和多通道两类.单通道网络一般是对文本向量进行顺序处理,特征提取过程通常表现为串行结构.刘月等使用串行结构的CNN和嵌套长短时记忆网络(Nested LSTM),融合注意力机制,提出基于注意力的CNLSTM模型,在新闻文本分类任务上取得了很好的效果[7 ] .韩永鹏等使用双通道词嵌入丰富文本表示,将Text-CNN提取的特征分别输入对应的LSTM网络中提取语序信息[5 ] .王艳等结合文本多种特征,丰富语义特征,使用卷积与最大池化操作进行特征提取,提高文本分类效果[8 ] .单通道的网络结构使得模型特征提取过程并不独立,顺序处理的网络结构导致靠后的特征提取网络不能发挥最好的效果. ...
局部语义与上下文关系的中文短文本分类算法
1
2021
... 多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题.田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] .黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] .张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] .Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] .传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题. ...
局部语义与上下文关系的中文短文本分类算法
1
2021
... 多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题.田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] .黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] .张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] .Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] .传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题. ...
基于组合-卷积神经网络的中文新闻文本分类
4
2021
... 多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题.田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] .黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] .张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] .Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] .传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题. ...
... (6)组合-CNN[10 ] :在传统CNN模型基础上,实现6层组合-CNN模型. ...
... Experimental Results of Comparison Methods
Table 4 模型 类别 THUCNews 电信客户投诉数据集 准确率/% F1 /% 准确率/% F1 /% NLSTM 单通道 93.39[7 ] 93.39[7 ] 82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20
3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
10 ]
84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
基于组合-卷积神经网络的中文新闻文本分类
4
2021
... 多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题.田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] .黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] .张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] .Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] .传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题. ...
... (6)组合-CNN[10 ] :在传统CNN模型基础上,实现6层组合-CNN模型. ...
... Experimental Results of Comparison Methods
Table 4 模型 类别 THUCNews 电信客户投诉数据集 准确率/% F1 /% 准确率/% F1 /% NLSTM 单通道 93.39[7 ] 93.39[7 ] 82.75 82.73 RCNN 单通道 95.69 95.67 83.71 83.71 LSTM+att 单通道 94.87[5 ] 94.85[5 ] 84.24 84.23 BiLSTM+att 单通道 95.05[5 ] 95.02[5 ] 85.32 85.32 BiLSTM+max-pooling 单通道 94.16 94.14 85.42 85.40 CNLSTM 单通道 96.87[7 ] 96.86[7 ] 85.66 85.60 组合-CNN 多通道 95.57[10 ] 95.55[10 ] 84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20
3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
... [
10 ]
84.54 84.34 CFC-LSTM-multi 多通道 96.21[5 ] 96.20[5 ] 85.75 85.75 本文方法 多通道 97.25 97.24 86.20 86.20 3.4 注意力机制对比分析 为了探究本文构建的多头协同注意力机制的特征交互效果,进行注意力机制对比实验.将本文方法与仅使用协同注意力机制(CNN-LSTM-Co)进行特征交互的方法作对比,结果如表5 所示.对比实验使用相同的文本向量化表示方法与特征提取方法、参数设置与本文方法相同.由实验结果可以看出,多头协同注意力机制相对于协同注意力机制有更好的分类效果,证明了多头协同注意力机制的构建方法有更好的特征交互效果. ...
AMFF: A New Attention-Based Multi-Feature Fusion Method for Intention Recognition
1
2021
... 多通道特征提取网络可以使用不同方法对输入序列进行独立特征提取,有助于缓解投诉文本短小与特征稀疏问题.田乔鑫等将两种不同的词向量并行输入双向门控单元和卷积神经网络中以提取全局特征和局部特征,结合双路注意力机制对关键信息进行加强[6 ] .黄金杰等利用CNN提取文本的局部语义特征,通过结合注意力机制的BiLSTM提取文本的上下文语义特征,提高了分类的准确率[9 ] .张昱等使用构造数据索引的方法,制作适合中文新闻分类的词汇表,下接三个并行的多通道卷积神经网络提取特征,使用拼接的方法进行特征融合,改善新闻文本分类特征提取不充分的问题[10 ] .Liu等融合三个不同模块提取的特征,以丰富短文本信息,解决短文本特征稀疏问题[11 ] .传统多通道客户投诉文本分类方法对不同特征提取网络输出的特征向量直接使用拼接或点乘进行特征融合,未实现特征间关系的交互,造成了特征间关系学习不足的问题. ...
A Review on the Attention Mechanism of Deep Learning
1
2021
... 作为一种资源分配方法,注意力机制是解决信息过载问题的主要手段.目前广泛应用在计算机视觉和自然语言处理领域,在一定程度上能够为深度网络提供直观的解释[12 ] .注意力机制在自然语言处理领域最早的应用是由Bahdanau等在机器翻译问题中引入,为编码器输入的不同部分赋予不同的权重,从而解决输入特征缺乏区分度的问题[13 ] .协同注意力机制(Co-attention)是将多个特征向量同时输入网络,联合学习各自的注意力权重,因此常被用于视觉问答任务中图像特征与文本特征之间关键信息的相互提取[14 ] .多头注意力机制是由Vaswani等提出的注意力机制的一种的组合方式,它将输入特征映射到不同子空间进行表示,使注意力部分可以联合关注到来自不同表示子空间的信息,提高了注意力机制的学习效果[15 ] .针对传统客户投诉文本分类模型存在的问题,本文构建了文本向量化表示和多通道特征提取网络解决客户投诉文本所呈现的数据短小、特征稀疏的问题,后构建了多头协同注意力机制对多通道输出特征进行交互,解决传统多通道投诉文本分类模型特征间关系学习不足的问题,提出了一种基于多头协同注意力机制的客户投诉文本分类模型. ...
Neural Machine Translation by Jointly Learning to Align and Translate
1
2015
... 作为一种资源分配方法,注意力机制是解决信息过载问题的主要手段.目前广泛应用在计算机视觉和自然语言处理领域,在一定程度上能够为深度网络提供直观的解释[12 ] .注意力机制在自然语言处理领域最早的应用是由Bahdanau等在机器翻译问题中引入,为编码器输入的不同部分赋予不同的权重,从而解决输入特征缺乏区分度的问题[13 ] .协同注意力机制(Co-attention)是将多个特征向量同时输入网络,联合学习各自的注意力权重,因此常被用于视觉问答任务中图像特征与文本特征之间关键信息的相互提取[14 ] .多头注意力机制是由Vaswani等提出的注意力机制的一种的组合方式,它将输入特征映射到不同子空间进行表示,使注意力部分可以联合关注到来自不同表示子空间的信息,提高了注意力机制的学习效果[15 ] .针对传统客户投诉文本分类模型存在的问题,本文构建了文本向量化表示和多通道特征提取网络解决客户投诉文本所呈现的数据短小、特征稀疏的问题,后构建了多头协同注意力机制对多通道输出特征进行交互,解决传统多通道投诉文本分类模型特征间关系学习不足的问题,提出了一种基于多头协同注意力机制的客户投诉文本分类模型. ...
Hierarchical Question-Image Co-Attention for Visual Question Answering
2
2016
... 作为一种资源分配方法,注意力机制是解决信息过载问题的主要手段.目前广泛应用在计算机视觉和自然语言处理领域,在一定程度上能够为深度网络提供直观的解释[12 ] .注意力机制在自然语言处理领域最早的应用是由Bahdanau等在机器翻译问题中引入,为编码器输入的不同部分赋予不同的权重,从而解决输入特征缺乏区分度的问题[13 ] .协同注意力机制(Co-attention)是将多个特征向量同时输入网络,联合学习各自的注意力权重,因此常被用于视觉问答任务中图像特征与文本特征之间关键信息的相互提取[14 ] .多头注意力机制是由Vaswani等提出的注意力机制的一种的组合方式,它将输入特征映射到不同子空间进行表示,使注意力部分可以联合关注到来自不同表示子空间的信息,提高了注意力机制的学习效果[15 ] .针对传统客户投诉文本分类模型存在的问题,本文构建了文本向量化表示和多通道特征提取网络解决客户投诉文本所呈现的数据短小、特征稀疏的问题,后构建了多头协同注意力机制对多通道输出特征进行交互,解决传统多通道投诉文本分类模型特征间关系学习不足的问题,提出了一种基于多头协同注意力机制的客户投诉文本分类模型. ...
... 协同注意力机制[14 ] 通过计算特征向量之间的共享相似度矩阵反映特征向量间的关系,后将共享相似度矩阵作用于原特征向量实现特征间的信息交互.在协同注意力机制和多头注意力机制[16 ] 的基础上,笔者构建多头协同注意力机制,用于投诉文本局部特征与全局特征的交互.在本文模型中,多头协同注意力机制的输入是多通道特征提取网络输出的局部特征矩阵 A ∈ R d × 3 B ∈ R d × 2 h 图4 所示.首先通过 h
Attention is All You Need
2
2017
... 作为一种资源分配方法,注意力机制是解决信息过载问题的主要手段.目前广泛应用在计算机视觉和自然语言处理领域,在一定程度上能够为深度网络提供直观的解释[12 ] .注意力机制在自然语言处理领域最早的应用是由Bahdanau等在机器翻译问题中引入,为编码器输入的不同部分赋予不同的权重,从而解决输入特征缺乏区分度的问题[13 ] .协同注意力机制(Co-attention)是将多个特征向量同时输入网络,联合学习各自的注意力权重,因此常被用于视觉问答任务中图像特征与文本特征之间关键信息的相互提取[14 ] .多头注意力机制是由Vaswani等提出的注意力机制的一种的组合方式,它将输入特征映射到不同子空间进行表示,使注意力部分可以联合关注到来自不同表示子空间的信息,提高了注意力机制的学习效果[15 ] .针对传统客户投诉文本分类模型存在的问题,本文构建了文本向量化表示和多通道特征提取网络解决客户投诉文本所呈现的数据短小、特征稀疏的问题,后构建了多头协同注意力机制对多通道输出特征进行交互,解决传统多通道投诉文本分类模型特征间关系学习不足的问题,提出了一种基于多头协同注意力机制的客户投诉文本分类模型. ...
... 在特征融合层与输出层,本文借鉴了类似ResNet[19 ] 中的残差连接和Transformer[15 ] 中经过注意力机制后再与原特征相加的操作,将交互后的特征向量 V i e w a b V i e w b a A B F ∈ R d × 10
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2
2019
... 文本表示是将文本转化为计算机可读的数字矩阵的过程,是本文方法的第一步.传统的文本向量化表示模型有Word2Vec、Doc2Vec、LDA等,但是传统模型无法很好地解决一词多义的问题.BERT模型是由谷歌发布的预训练语言模型[16 ] ,可以有效解决一词多义问题. ...
... 协同注意力机制[14 ] 通过计算特征向量之间的共享相似度矩阵反映特征向量间的关系,后将共享相似度矩阵作用于原特征向量实现特征间的信息交互.在协同注意力机制和多头注意力机制[16 ] 的基础上,笔者构建多头协同注意力机制,用于投诉文本局部特征与全局特征的交互.在本文模型中,多头协同注意力机制的输入是多通道特征提取网络输出的局部特征矩阵 A ∈ R d × 3 B ∈ R d × 2 h 图4 所示.首先通过 h
Convolutional Neural Networks for Sentence Classification
1
2014
... Text-CNN[17 ] 是一种具有较强文本特征提取能力的网络.本文采用三个不同尺寸卷积核的Text-CNN网络,分别提取卷积核范围内的特征信息,下接最大池化做降维,其结构如图2 所示.首先将文本表示层的输出 X c j
Bidirectional LSTM with Self-attention Mechanism and Multi-channel Features for Sentiment Classification
1
2020
... BiLSTM[18 ] 是LSTM的变体,其可对文本进行正向和反向两个方向的建模,获取前后文的依赖关系,完成文本序列的全局特征提取.LSTM的“门”结构如图3 所示. ...
Deep Residual Learning for Image Recognition
1
2016
... 在特征融合层与输出层,本文借鉴了类似ResNet[19 ] 中的残差连接和Transformer[15 ] 中经过注意力机制后再与原特征相加的操作,将交互后的特征向量 V i e w a b V i e w b a A B F ∈ R d × 10
Convolutional Recurrent Neural Networks for Text Classification
1
2019
... (2)RCNN[20 ] :先使用RNN提取上下文信息,后接CNN提取局部特征. ...
1
2016
... (3)LSTM+att[21 ] :使用注意力机制对LSTM各时刻输出进行加权. ...
1
2016
... (3)LSTM+att[21 ] :使用注意力机制对LSTM各时刻输出进行加权. ...
基于深层注意力的LSTM的特定主题情感分析
1
2019
... (4)BiLSTM+att[22 ] :结合多头注意力机制的双向LSTM. ...
基于深层注意力的LSTM的特定主题情感分析
1
2019
... (4)BiLSTM+att[22 ] :结合多头注意力机制的双向LSTM. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}